This article was published as a part of the Data Science Blogathon.
Introduction
Dealing with sequential data is considered one of the hardest problems to solve in the Data science industry. Standard neural networks have paved a new path in the rising AI industry. It worked very well with tabular data but every new invention in technology comes with a disadvantage. Similarly, ANN also came up with some gaps which as not being able to deal with Sequential data. These include a wide range of problems like predicting the next word on your mobile keyboard or finding the patterns in sock markets’ data.
With the recent discoveries that have been happening in this field, it has been observed that for almost all of these sequence problems, Long Short-Term Memory (LSTMs) has given the most appropriate solution.
In this article, we will understand the nitty-gritty details behind this algorithm and will answer your questions like where LSTMs is used, how we implement them, and why we need LSTMs if we had RNN already. Without wasting our time let’s start our article.
RNN Model Overview
A recurrent Neural Network is the first of its kind State of the Art algorithm that can memorize/remember previous inputs in memory when a huge set of Sequential data is given to it. The main objective behind RNN was to make use of sequential data. Examples of sequential data can be time-series data, text sequence, or audio which can be seen as a sequence of frequencies over time. In an artificial neural network, we assume that all the inputs are independent of each other. But for many tasks, that’s a terrible idea.
RNN, Recurrent neural networks are called recurrent because they perform the same task for every element of a series, with the output being dependent on the previous calculations.
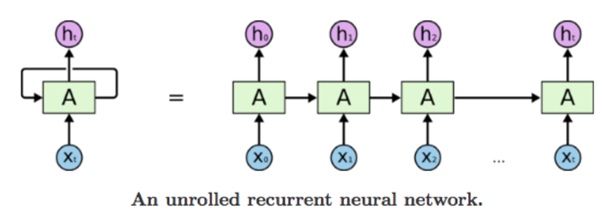
Image source: https://purnasaigudikandula.medium.com/recurrent-neural-networks-and-lstm-explained-7f51c7f6bbb9
Suppose you are reading a sentence, you’ll read it word by word keeping the previous context in mind, and then update your understanding. This is exactly what RNNs do. They maintain an ‘internal’ state called a hidden state which encodes everything which it has seen so far.
Let’s take an example. Consider the following text string: A boy walked into a cafe and said “Can I have 2 burgers and 1 French fries? The waiter said “certainly {}” . There are many options which can fill out this blank for instance, “miss”, “ma’am” and so on. However, other words could also fit, such as “sir”, “Mister” etc. To get the appropriate answer the neural network need to remember the context, like if the reader is talking about a ‘boy’ or a ‘girl’.
The diagram of the unrolled network above shows how we can supply a stream of data to RNN. At timestamp t=1 the first word is input to the network, the output of this is then fed to the 2nd timestamp. One thing to note here is that we can not send the sentence as it is to our network, we first need to convert them into computer language for that we can use one-hot-encoding or words embeddings (e.g. Word2vec)
Limitations of RNNs
If you have read my previous article then you should know that RNNs face vanishing and exploding gradient problems and due to which they are not able to deal with long sentences, which means they work just fine when dealing with short-term dependencies. It works well with problems like:

This is because RNNs have nothing to do with the context of the statement. In this case they just need to know that in most cases the Ice cream is “tasty”. Thus, the prediction would be:

Since RNN cannot understand or remember the context of a sentence, we can not use them when we have a long sentence because something that was said long before, cannot be recalled when making predictions in the present. Let’s understand this with the help of an example:

Suppose you are making a grammar checker, in the above sentence clearly instead of “her” it should be “his”. How did we know this? Because we know the context of the sentence, we know that here we are talking about a man who goes on a trip every Wednesday. Similarly, to make proper predictions RNN needs to remember all this context. This is where the Recurrent Neural Network fails. I have mentioned the reason behind this in my previous article on RNN, do have a look at it.
Now you know why we use LSTM when we have RNN. Let’s have a look at what is special about this network and how they perform better than RNN.
Long Short-Term Memory (LSTM) Networks
Suppose you are in your office, and you have a meeting in the evening and then out of nowhere you remember that you have to attend someone’s marriage that evening. What will you do? You will definitely make up some space, you know which meeting could be canceled and which couldn’t.
Turns out that an RNN doesn’t do so. In order to add some new information, it completely transforms the existing information by applying some activation function to it and because of this the entire information is modified i.e., no consideration for “important” information and “not so important” information.
On the other hand, LSTMs work on the concept of gates. The information here flows through a mechanism known as cell states. It has 3 main gates, Forget Gate, Input Gate, and Output gate. This way it can selectively remember and forget things.
In an LSTM cell, there are mainly two states that are being transferred to each cell; the cell state and the hidden state. The memory blocks are responsible for remembering things and operations to this memory are done through three major mechanisms called gates. There are mainly 3 types of gates in LSTM:
1. Forget Gate -What do you do when the refill of your pen finishes? You throw it out, right? Because the pen is not useful anymore. You will have to buy another one. Similarly, LSTM forgets the information which is not useful. Suppose you are talking about a person X and after the end of this sentence the reader starts talking about person Y, here person X is not useful and hence we don’t want our network to remember him/her. This is when forget gate comes into play it forgets the information which doesn’t seem to help us in any way. The equation of this gate is :
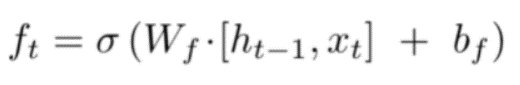
2. Input Gate – Do you think throwing the pen was the only option for us? We could also go and buy another refill for the same body, that would have worked. This means that you are not throwing your pen, you are using a new refill now. LSTM work in a similar manner. In the above example when we started talking about person Y the LSTM forgot the person X and started saving the information for person Y. Hence input gate is used when we want to add new information to our model. The equation of this gate is:
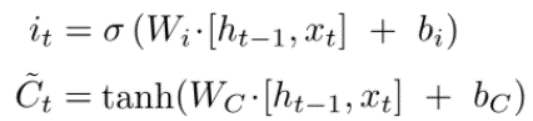
3. Output Gate – 1. If you have read my previous article on RNNs, there we studied that there are various types of RNN structures like one-to-many, and many-to-many. It depends on what structure we are using. Suppose we are using a many-to-many structure then we would want output from each cell and after each timestamp. The output gate also has a matrix where weights are stored and updated by backpropagation. The equation for the output gate is :
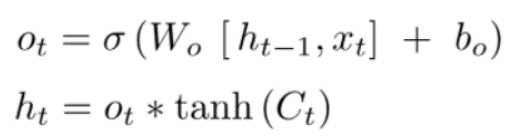
We’ll look in detail at these 3 gates in the next article. Let’s take one step at a time. In this article, we learned why we can’t use RNN and a basic intuition behind LSTM.
Conclusion
In this article, we had a basic understanding of what LSTMs is. There are various problems with RNN like exploding and vanishing gradient problems. It is very hard for RNNs to remember the context which was said long before because the activation which is passed onto the next timestamp is updated very quickly and that’s why RNNs couldn’t remember the context of the sentence. We then looked briefly at how LSTMs helps us to overcome all these issues faced by RNN. It basically uses the concept of gates. The forget gate is used to forget the unnecessary information we have in our sentence, the input gate is used when we want to add new information to our model and the output gate finally combines all the information we have and then give us the output accordingly.
In the next article will see and understand more about these gates and the mathematics behind them. We’ll also look at the implementation of LSTMs.
I hope after reading this some doubts regarding LSTMs might have cleared. Do reach out in the comments if you still have any doubts.
For any doubt or queries about LSTMs, feel free to contact me by Email
Connect with me on LinkedIn and Twitter.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I have recently graduated with a Bachelor's degree in Statistics and am passionate about pursuing a career in the field of data science, machine learning, and artificial intelligence. Throughout my academic journey, I thoroughly enjoyed exploring data to uncover valuable insights and trends.
I am eager to continue learning and expanding my knowledge in the field of data science. I am particularly interested in exploring deep learning and natural language processing, and I am constantly seeking out new challenges to improve my skills. My ultimate goal is to use my expertise to help businesses and organizations make data-driven decisions and drive growth and success.





