This article was published as a part of the Data Science Blogathon.
MongoDB is a type of NoSQL database which is open-sourced and widely used in data science and machine learning in form of a database. Hence, knowledge of it is important in the long run, especially in the field of data science and analytics.
In this article, we will explore how to use MongoDB for our data science applications. We shall learn about its powerful aggregation pipeline feature.
For this guide tutorial, we shall be using the Nobel Prize Dataset API which is a database of all Nobel prize winners. One can check the documentation of their API. In this tutorial, we shall use two datasets “laureates”(which contains detailed information about each of the laureate who won the Nobel prize) and “prize” (which contains information about Nobel prize winners).
Introduction to MongoDB
MongoDB was founded in the year 2007 by Dwight Merriman, Eliot Horowitz and Kevin Ryan. MongoDB is a scalable and flexible NoSQL document-based database platform designed to overcome the shortcomings of relational databases. It is known for its horizontal scaling & load balancing capabilities, which have given application developers an unprecedented level of scalability & flexibility
MongoDB features
MongoDB has many useful features they are:

Document-oriented
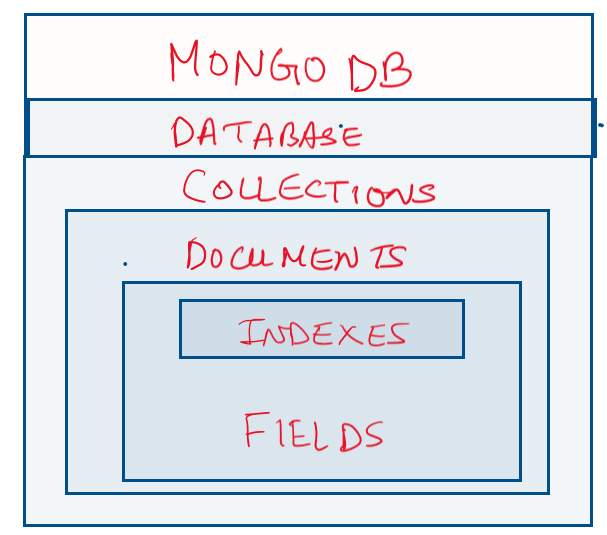
It is a document-oriented database, which is a great feature itself. As is known in relational databases, there are tables and rows of the data. Every row has a fixed number of columns which is non-dynamic.
This is where the unstructured nature of NoSQL comes where there are fields instead of tables and rows. In MongoDB, we can have many Databases(analogous to the schema of SQL). Each database consists of several collections(analogous to tables in SQL). There are collections of similar documents. The collection consists of documents and each document contains fields and unique keys and indexes such as object id which can be user or system defined.
Create Database and Collection in MongoDB
As discussed earlier our first step is to create a database name “nobel“.
Mongo shell command : use
use nobel
Pymongo command
In mongo, we can use the `dict` notation on the client. If the db already exists then mongo returns a reference to that db otherwise creates new db. To insert a number of documents we can use the `insert_many()` method on the collection instance and pass an iterable python object such as a list of dictionaries.
import pymongo
import requests
#Connect to local mongo server through client
mongo_client = pymongo.MongoClient("mongodb://localhost:27017/")
#Create database
nobel_prize_db = mongo_client['nobel']
#fetch prize json data from api request
response = requests.get("http://api.nobelprize.org/v1/prize.json")
#convert response to json data
prize_data = response.json()['prizes']
#insert the list of documents into collection ; we can pass any iterable python elemnent to insert many
nobel_prize_db['prize'].insert_many(prize_data)
Similarly, do for laureates’ data
#fetch laureate json data from api request
response = requests.get("http://api.nobelprize.org/v1/laureate.json")
#convert response to json data
laureate_data = response.json()['laureates']
#insert the list of documents into collection ; we can pass any iterable python elemnent to insert many
nobel_prize_db['laureates'].insert_many(laureate_data)
Now if we check the compass and refresh we will see our database within it two collections and each collection consists of respective documents.
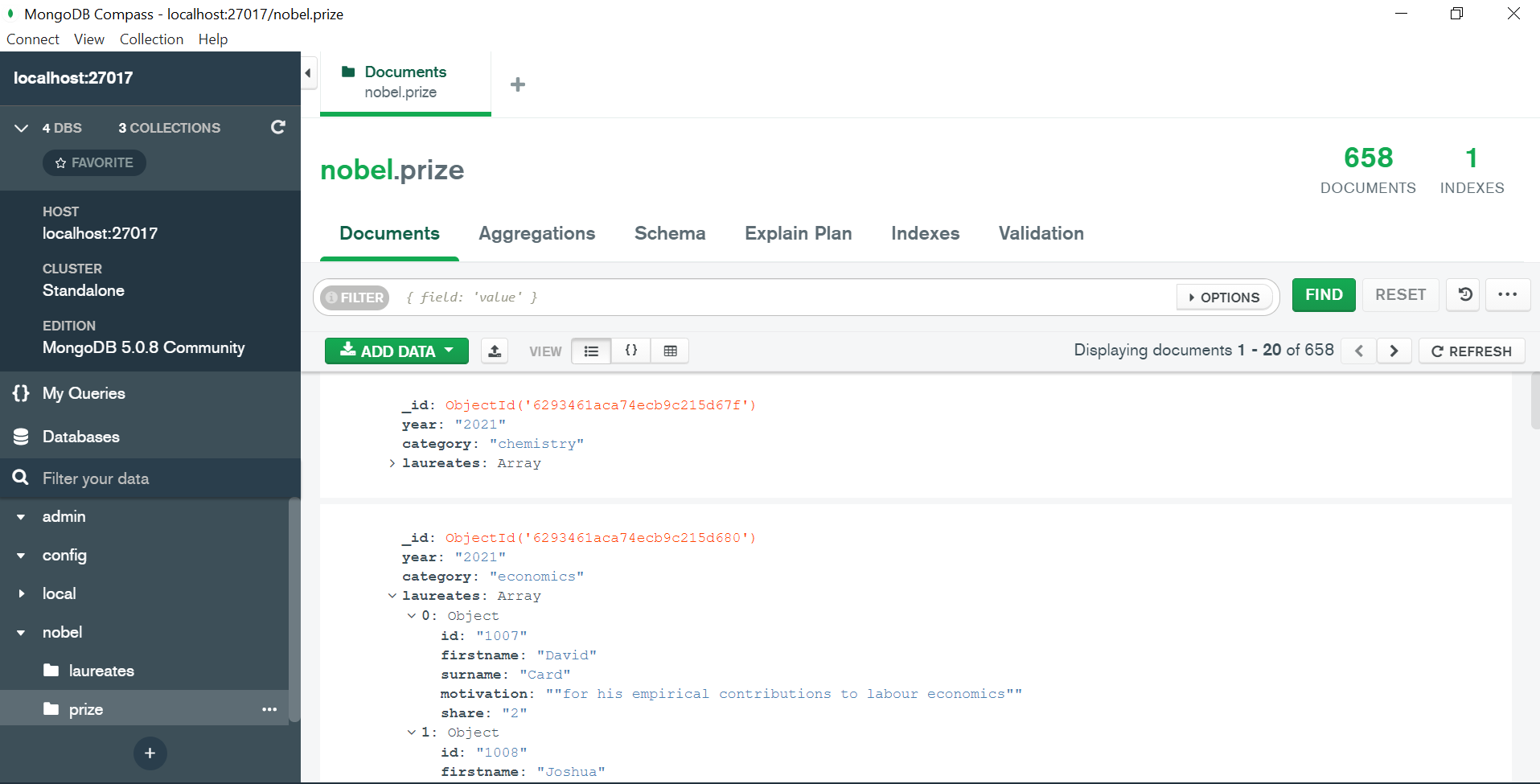
NOTE: MongoDB does not allow us to create an empty database . This means even if we run the use db or create client[‘nobel’] then also no db is created unless we create any collection in it.
Common MongoDB Operations
- List database and collection names
Mongo Shell :
Pymongo
nobel_prize_db.list_database_names() prize_coll = nobel_prize_db['prize'] prize_coll.list_collection_names()
- Drop Collection or Database
We can drop any collection or database by simply switching to that Db to drop a collection within that db.
Mongo Shell

Pymongo
nobel_prize_db.drop() prize_coll = nobel_prize_db['prize'] prize_coll.drop()
- Find Documents based on condition query
Pymongo
We can search and retrieve documents based on a condition query. We have two methods in collection .find() and .find_one() . To retrieve a single document we use .find_one() and for getting multiple documents we can use .find() which returns a cursor like object using next() method we can get each document through cursor. This method accepts an optional filter argument that specifies the pattern that the document must match.
Find Nobel prize winner of chemistry in the 2021 year. This will return a single document so we use the find_one() method.
#to find nobel prize winners of chemistry in 2021
single_docu = prize_coll.find_one({"year":'2021', "category":"chemistry"})
print(single_docu)
Output
{‘_id’: ObjectId(‘629427daf79936a9106eb2be’), ‘year’: ‘2021’, ‘category’: ‘chemistry’, ‘laureates’: [{‘id’: ‘1002’, ‘firstname’: ‘Benjamin’, ‘surname’: ‘Li
st’, ‘motivation’: ‘”for the development of asymmetric organocatalysis”‘, ‘share’: ‘2’}, {‘id’: ‘1003’, ‘firstname’: ‘David’, ‘surname’: ‘MacMillan’, ‘moti
vation’: ‘”for the development of asymmetric organocatalysis”‘, ‘share’: ‘2’}]}
- Count Number of Documents in Collection
Pymongo
Here we need to pass an empty query filter({}) to the count_documents method of find. If we pass any query then it will filter documents based on that query and return the count of documents based on the filter
prize_coll = nobel_prize_db['prize']
#to find number of documents in a collection
print(prize_coll.count_documents({}))
- Update documents in a collection
Pymongo
We can update data in a collection using update_one() method and update_many() method. We need to pass a filter query to select a document to update and then the second argument is an update operation. There are a set of update operators that can be used for example here we set a new field to an existing document using the `$set` operator.
#update single document
val =prize_coll.update_one({"year":'2021', "category":"chemistry"}, {"$set":{"test_update": "update"}})
print(val.modified_count , val.matched_count)
Output
1 1
Dot Notation and Projection
Dot notation is how MongoDB allows us to query document substructure. MongoDB allows us to query document substructure using dot notation. In the laureates’ collection, each laureate has won a prize and for each prize, they are affiliated with a particular university/college during the time of winning.
Let us find the affiliated college where “Amartya Sen won the Nobel prize”.
Projections allow us to select which field we want to display in the returned documents from a query. Syntax is {: 0 or 1} 0 means hide and 1 means display and default is 0. If no projection is mentioned the whole document is returned as-is.
laureates_coll = nobel_prize_db['laureates']
affiliated_college = laureates_coll.find({"firstname":"Amartya"},{"prizes.affiliations.name": 1})
print(list(affiliated_college))
Output
[{'_id': ObjectId('629427e1f79936a9106eb808'), 'prizes': [{'affiliations': [{'name': 'Trinity College'}]}]}]
Composing Query Filters
There are a number of ways in which we can query the document and MongoDB provides a number of query selectors. We will go through some important ones here.
We can use a query filter document which uses the query operators to specify conditions in the following form:
{ : { : }, ... }
$exists Operator
#Exists
no_bornCountry = laureates_coll.find({"bornCountry": {"$exists": False}}, {"firstname": 1})
list_no_bornCountry = list(no_bornCountry)
print("Count of winners with no born country:", len(list_no_bornCountry))
for v in list_no_bornCountry:
print(v['firstname'])
Output
Count of winners with no born country: 26
Institute of International Law
Permanent International Peace Bureau
International Committee of the Red Cross
Nansen International Office for Refugees
Friends Service Council
American Friends Service Committee
Office of the United Nations High Commissioner for Refugees
League of Red Cross Societies
….
We can see there are 26 winners with no born country they are mainly organizations.
In and Greater Than Operator
Let us find winners of the chemistry and physics categories with a prize share value greater than equal to 4.
#In
counts = laureates_coll.count_documents({"prizes.category":{"$in":["physics","chemistry"]}, "prizes.share":{"$gte":"4"}})
print(counts)
Output 56
Introduction Aggregation Pipelines
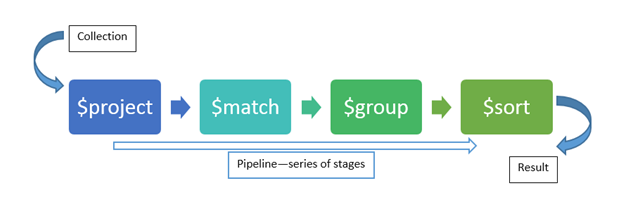
There are cases where you may want to avoid having to fetch and iterate over lots of data client-side. MongoDB can do a good chunk of our data analysis and aggregation for us using the Aggregation Pipeline. In the aggregation pipeline, we define a series of stages which are transformations that needs to be done on the collection. It takes in an input collection performs the stages and returns the processed final results of documents.
Each stage of the pipeline is executed before transferring the output to the next stage for processing. They are extremely fast and performant.
Source: https://www.codeproject.com/Articles/1149682/Aggregation-in-MongoDB
Nobel Prize Data Analysis using Pipelines
We shall now apply the various aggregation stages to our data and see their usage. To read more about various aggregation pipelines visit :
Grouping Stage
This stage is similar to Group By in SQL wherein we can group based on any field and then perform operations on each group.
Lets us try to find the count of Nobel prizes in each category in the prize collection.
Mongo Compass
In Mongo Compass we can easily apply aggregations and view results in its GUI.
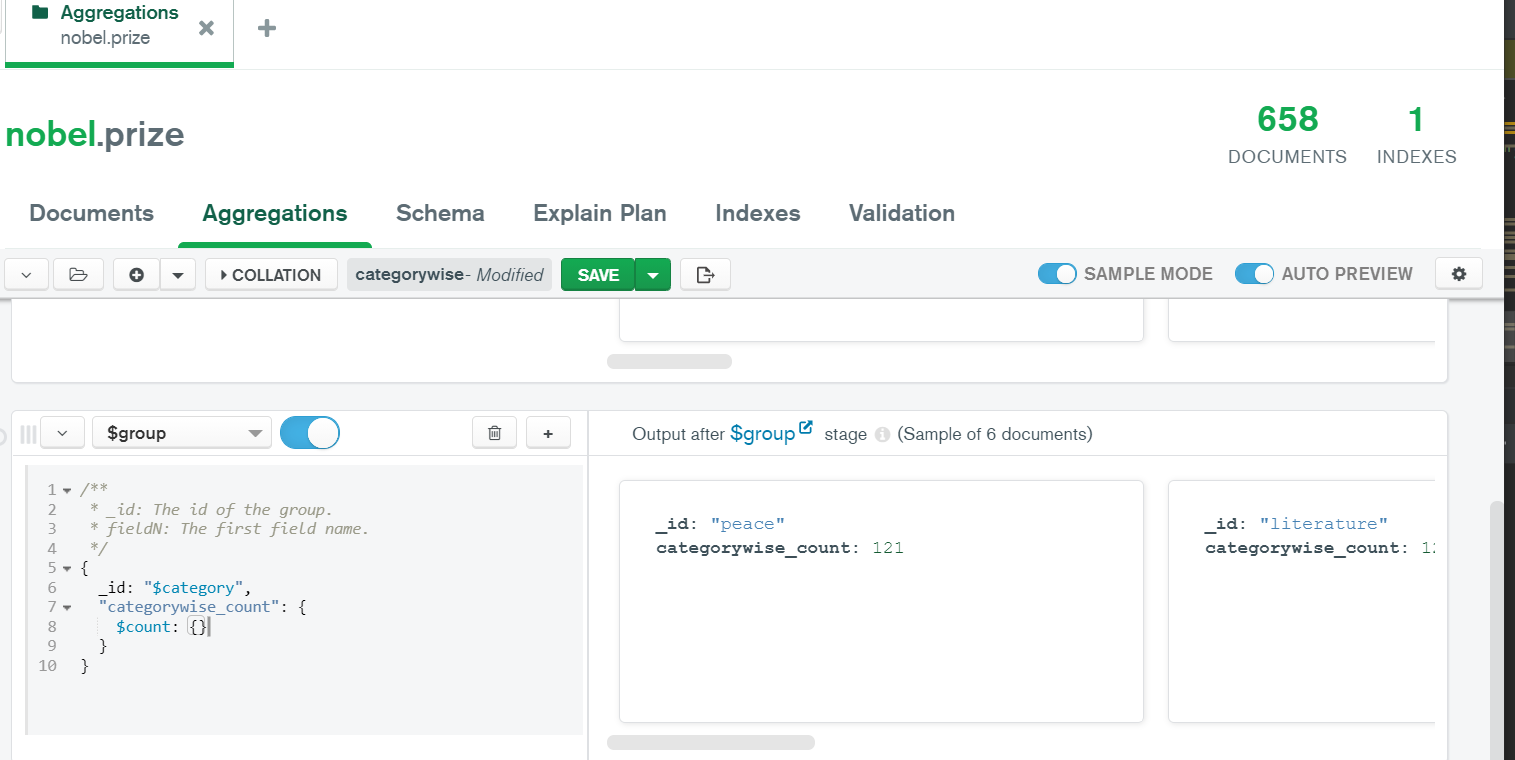
Pymongo
category_wise_count = list(prize_coll.aggregate([{
"$group":{"_id": "$category", "categorywise_count": {"$count": {}}}
}]))
print(category_wise_count)
Output
[{‘_id’: ‘peace’, ‘categorywise_count’: 121}, {‘_id’: ‘physics’, ‘categorywise_count’: 121}, {‘_id’: ‘literature’, ‘categorywise_count’: 121}, {‘_id’: ‘med
icine’, ‘categorywise_count’: 121}, {‘_id’: ‘chemistry’, ‘categorywise_count’: 121}, {‘_id’: ‘economics’, ‘categorywise_count’: 53}]
In the output we can see there are 6 categories and almost all have 121 prize counts except economics with a prize count of 53.
Unwind, Set, Sort, Project Stages
Now we will find the count of laureates grouped by category and country. For this, we have to perform 5 stages. First is the $unwind stage which unfolds each array element specified for the document. Then we use $group stage to group based on multiple fields this time. Next, we use the $set operator which allows us to create new fields for each document. Next, we sort the documents in descending order based on the count. Finally we $project the results.
Pymongo
results = list(laureates_coll.aggregate([
#1st Stage Unwind prize Array
{"$unwind":{"path": "$prizes", "preserveNullAndEmptyArrays": False}},
#2nd Stage: Group based on category and borncountry and perform count operation
{"$group":{"_id": {"category":"$prizes.category","country":"$bornCountry"}, "count": {"$count":{}}}},
#3rd Stage Set new fields on documents from previous stage COuntry and category
{"$set": {"category": "$_id.category","country":"$_id.country"}},
#4th Stage : Sort the document in descending order of count from prev stage
{"$sort":{"count": -1}},
#5th Stage Project the country , category and count fields
{"$project":{"_id" : 0,"category":1,"country":1,"count":1}}
]))
for i in results[:10]:
print(i)
Output
{'count': 79, 'category': 'medicine', 'country': 'USA'}
{'count': 70, 'category': 'physics', 'country': 'USA'}
{'count': 55, 'category': 'chemistry', 'country': 'USA'}
{'count': 50, 'category': 'economics', 'country': 'USA'}
{'count': 28, 'category': 'peace'}
{'count': 25, 'category': 'medicine', 'country': 'United Kingdom'}
{'count': 25, 'category': 'chemistry', 'country': 'United Kingdom'}
{'count': 23, 'category': 'physics', 'country': 'United Kingdom'}
{'count': 22, 'category': 'chemistry', 'country': 'Germany'}
{'count': 19, 'category': 'peace', 'country': 'USA'}
Thus, we can observe that for the categories “medicine,physics ,chemistry,economics” highest number of winners are from the USA country followed by the UK.
Match, Date Handling
Let us now try to find the category-wise average age of laureates. For this, we use the match operator which acts as the select operator of SQL.
Pymongo
results = list(laureates_coll.aggregate([
#1st Stage Unwind prize Array
- {“$unwind”:{“path”: “$prizes”, “preserveNullAndEmptyArrays”: False}},
#2nd Stage: Select documents which have born and prizes.year field
{"$match": {"born": {"$exists": True},"prizes.year":{"$exists": True}}},
#3rd Stage Set new fields on documents extract born year using substring
{"$set": {"bornYear": {"$toLong" :{"$substr":["$born",0,4]}}, "winningYear":{"$toLong":"$prizes.year"} }},
#4th Stage : Set new field which is calculated age of laureates at the time of winning nobel prize
{"$set":{"age":{"$toInt":{"$subtract":["$winningYear","$bornYear"]} }}},
#5th Stage Group the fields by category and find average age per category and count
{"$group":{"_id" : "$prizes.category","average_age":{"$avg": "$age"},"category_wise_laureates_count":{"$count":{}} }}
]))
for i in results[:10]:
print(i)
Output
{‘_id’: ‘chemistry’, ‘average_age’: 58.755319148936174, ‘category_wise_laureates_count’: 188}
{‘_id’: ‘medicine’, ‘average_age’: 58.59375, ‘category_wise_laureates_count’: 224}
{‘_id’: ‘physics’, ‘average_age’: 56.821917808219176, ‘category_wise_laureates_count’: 219}
{‘_id’: ‘literature’, ‘average_age’: 64.86440677966101, ‘category_wise_laureates_count’: 118}
{‘_id’: ‘peace’, ‘average_age’: 57.68382352941177, ‘category_wise_laureates_count’: 136}
{‘_id’: ‘economics’, ‘average_age’: 66.7752808988764, ‘category_wise_laureates_count’: 89}
As we can see the average is highest for economics and the lowest for physics.
Sharding
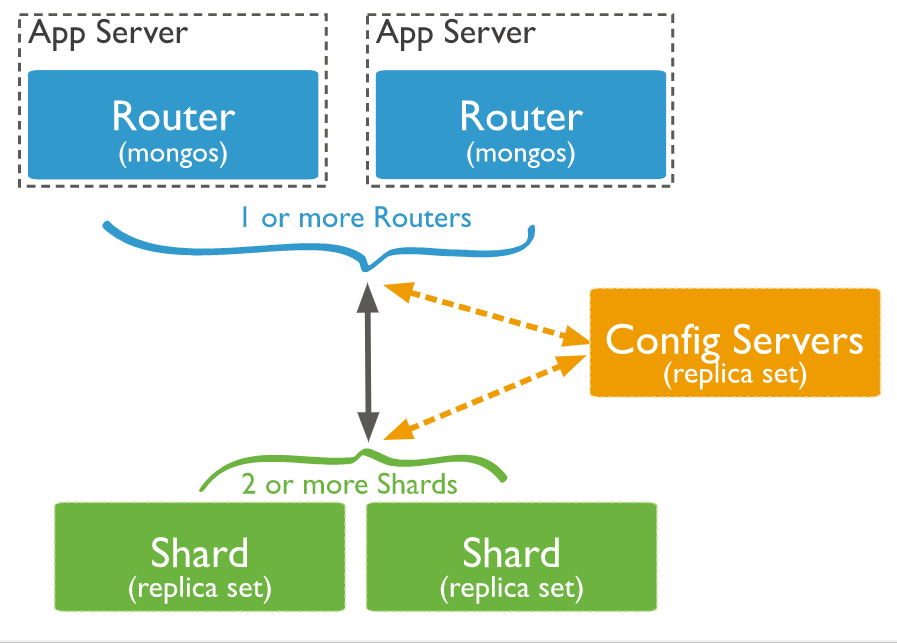
Sharding is the process of dividing a dataset and storing them in multiple machines this improves the efficiency of operations for very large data.
A sharded cluster consists of :
- Shards
- Mongos
- Config Server
The shard is a subset of the dataset.
The mongos serves as a query router for client requests, handling both read and write operations. Clients do not connect to individual shards instead they connect to a mongos. It dispatches client requests to appropriate shards & aggregates the result from shards to consistent client response.
Config servers are the handle source of sharding metadata. The metadata consists of various information such as sharded collections, routing information, etc.
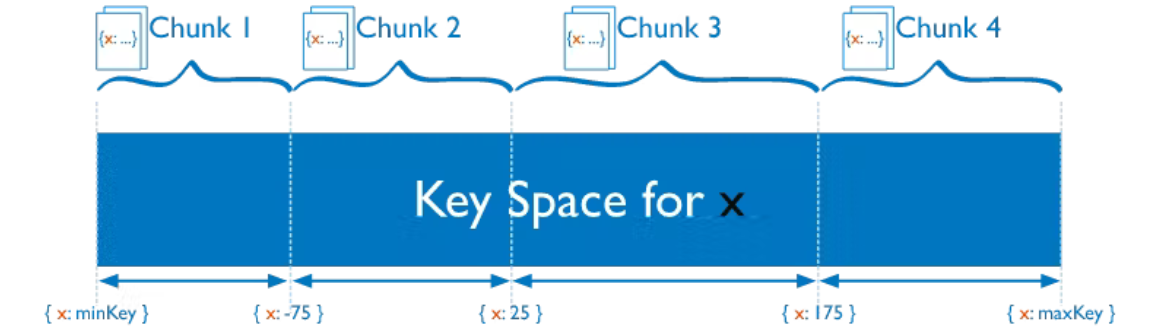
Shard Key
MongoDB performs sharding at the collection level. MongoDB uses the shard key as a strategy to distribute collection documents across shards. MongoDB first splits data into “chunks”, by dividing the span of shard key values into non-overlapping ranges. MongoDB then tries to distribute those chunks evenly among the shards in the cluster.
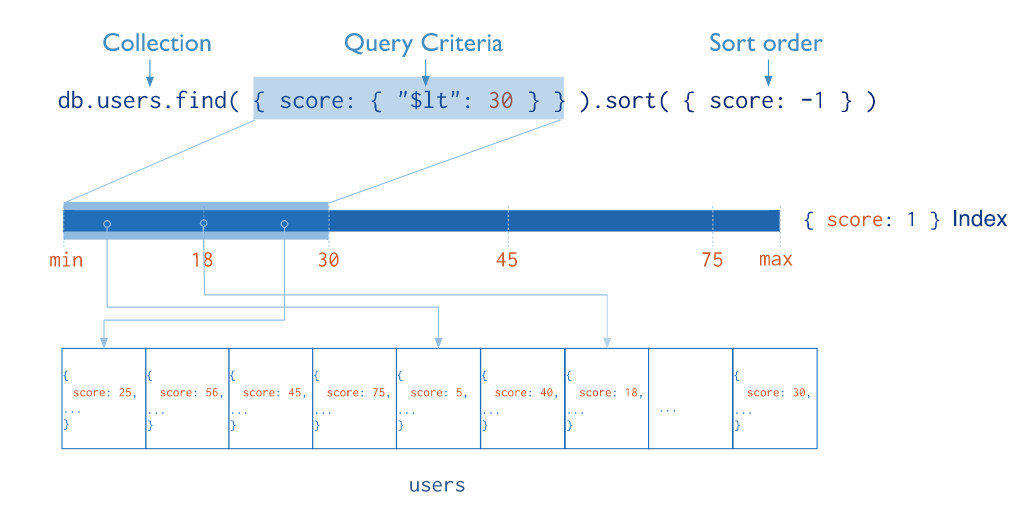
Indexes
Indexes are data structures that store a small portion of the collection’s data set so that it can be traversed easily. The index stores the value of a specific field or set of fields, which are sorted by the value of the field. Thus, ordering index entries supports speedy equality matches and range-based query operations. Apart from this, MongoDB can return sorted results by using order in the index.
MongoDB defines indexes at the collection level.
https://www.mongodb.com/docs/manual/indexes/
By default, the object _id is the default index.
Creating of the Index
One can easily create an index in Mongo Compass.
- Select the collection
- Navigate to the Indexes Tab at the top
- Click on create Index and then add fields.
- Choose the strategy sort in ascending or descending.
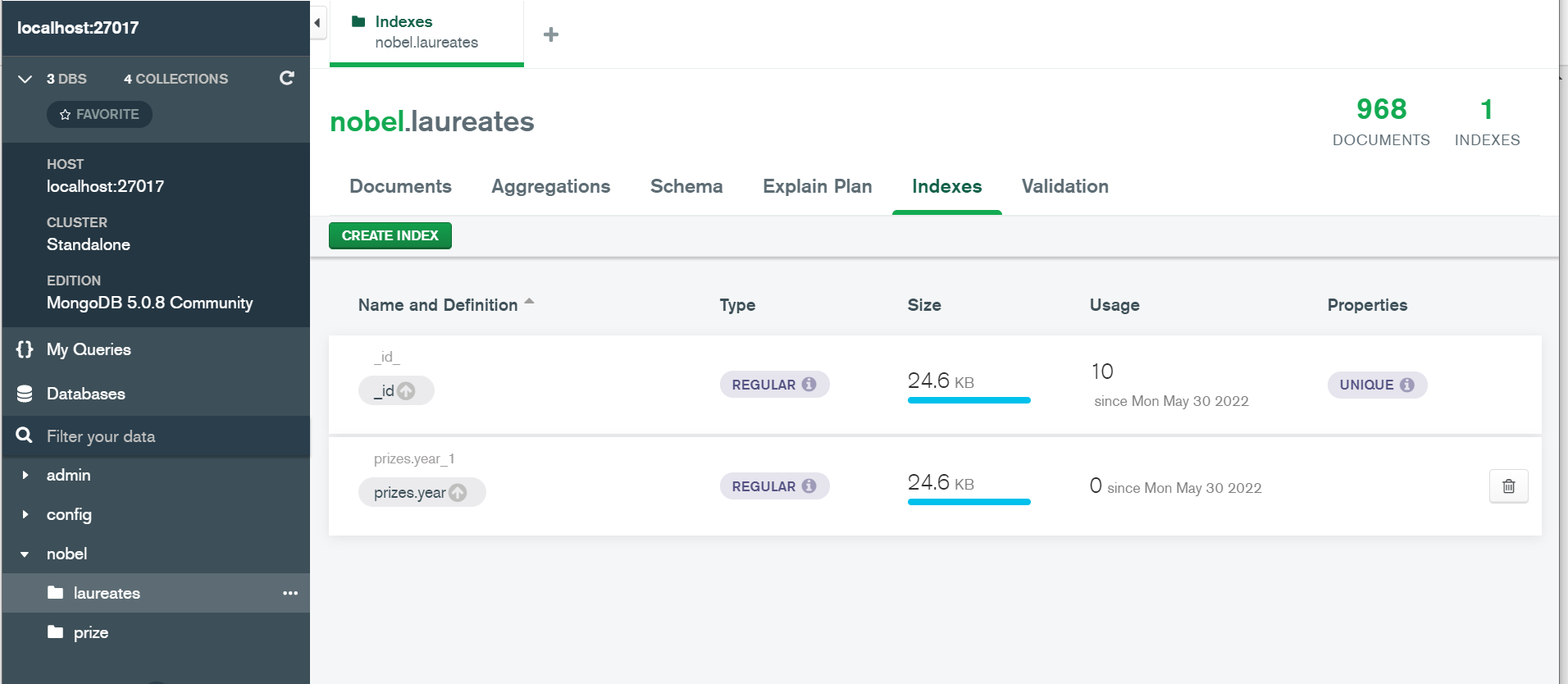
Conclusion
Thus, we saw how MongoDB is becoming an indispensable NoSQL database with several applications in Data Science. We learned about installing and setting up Mongo server locally and went through all its essential and common operations with examples from the Nobel prize dataset. We then saw how to use the powerful Aggregation Pipeline in Python using pymongo.
As a further learning endeavour, one could explore MongoDB as a service through MongoDB Atlas.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I am a professional working as data scientist after finishing my MBA in Business Analytics and Finance. A keen learner who loves to explore and understand and simplify stuff! I am currently learning about advanced ML and NLP techniques and reading up on various topics related to it including research papers .







great article. keep up the good work.