This article was published as a part of the Data Science Blogathon.
Introduction on Amazon Sagemaker
Amazon Sagemaker is arguably the most powerful, feature-rich, and fully managed machine learning service developed by Amazon. From creating your own labeled datasets to deploying and monitoring the models on production, Sagemaker is equipped to do everything. It can also provide an integrated Jupyter notebook instance for easy access to your data for exploration and analysis, so you don’t have to fiddle around with server configuration. Sagemaker supports bring-your-own-algorithms and frameworks, which offer flexible distributed training options that adjust to your specific workflows. Pipelines can be created for any machine learning workflow that you can think of which can get quite complex.
Here are some of the important features provided by Amazon Sagemaker.
1. SageMaker Studio:
An integrated ML environment using which you can train, build, deploy, and analyze your models all at the same place.
2. SageMaker Ground Truth
Very high-quality training datasets using workers to create labeled datasets as you like.
3. SageMaker Studio Lab
A free service that gives access to computing resources in the Jupyter environment.
4. SageMaker Data Wrangler
Using Data Wrangler you can import, analyze, prepare, and featurize data in SageMaker Studio. You can integrate it into your ML workflows to simplify data pre-processing or feature engineering using little coding or sometimes no coding. You also have the facility to add your own Python scripts and transformations to customize your data preparation workflow.
People without ML knowledge can easily build classification and regression models.
Directly jumping into Sagemaker and working with it can be overwhelming especially for people who don’t have good machine learning knowledge and things can really get out of hand really quickly. This is the case where Sagemaker Autopilot can really help people and businesses.
Let us look at how easy it is to use Amazon Sagemaker to develop a Machine Learning model even for a beginner.
Getting Started with Sagemaker Autopilot
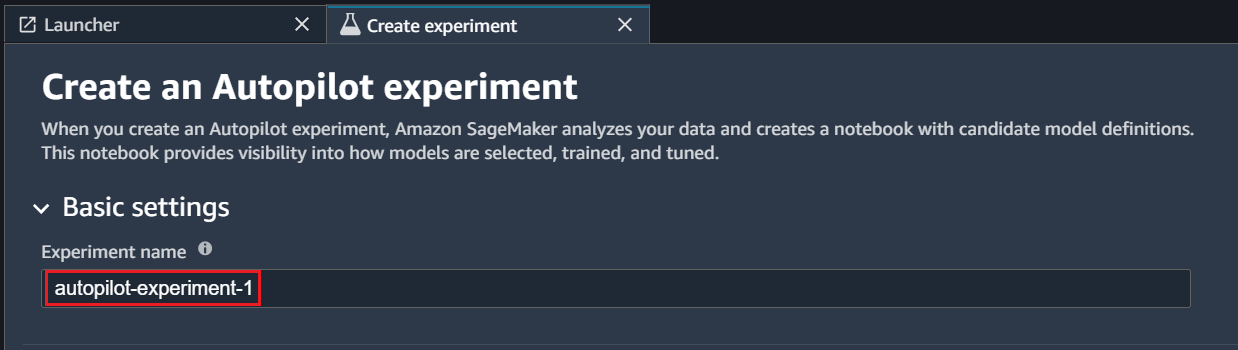
- Enter the Experiment name and the S3 location where your dataset is present.
2. Enter the Experiment name and the S3 location where your dataset is present.
(Note that URL must be an s3:// formatted URL where Amazon SageMaker has the write permissions and it must be in the current AWS Region. Also, the file must be in CSV or Parquet format and contain at least 500 rows.)
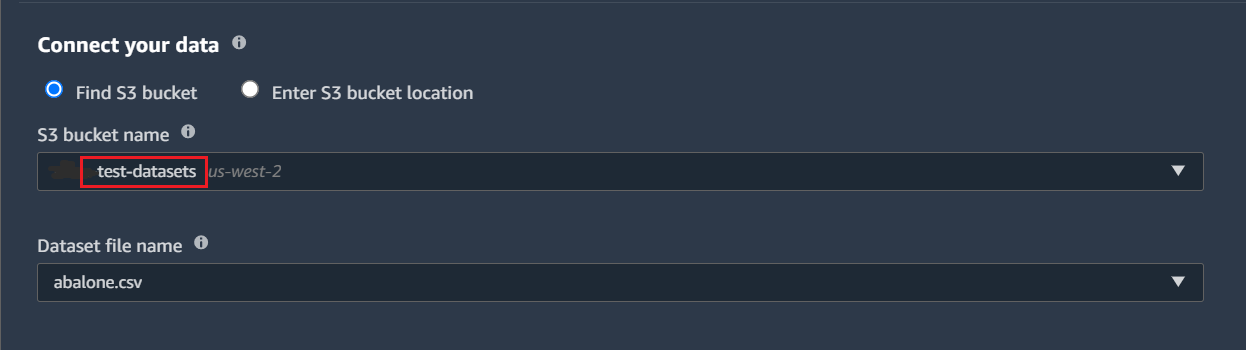
3. Next, Tick the toggle switch to on if you wish to provide a manifest file instead of the dataset directly. A manifest file includes metadata about input data along with the location of the data and which attributes from the dataset to be used etc.

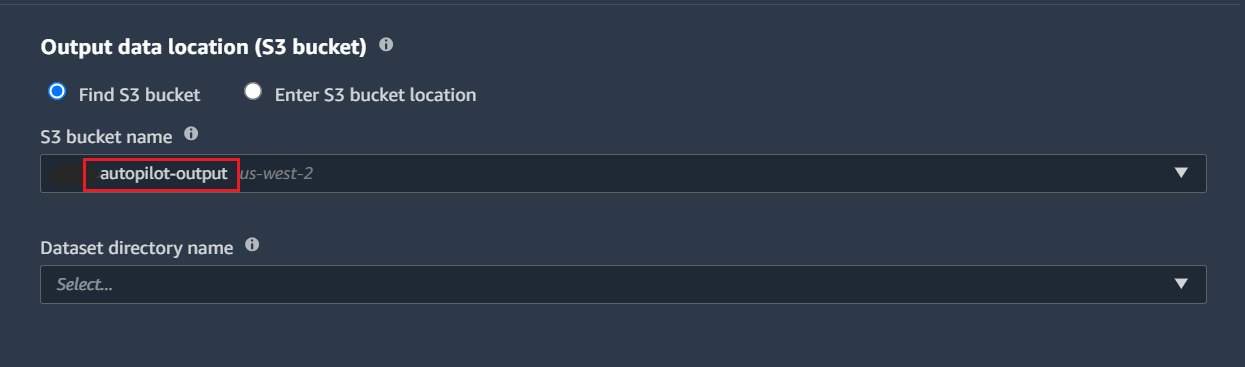
4. Select the target column and enter the output bucket location.

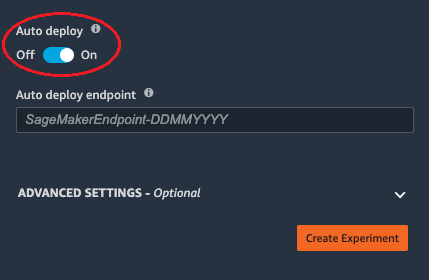
5. There are a few Advanced options you can set like the Machine learning problem type (Regression, Classification) and choosing how to run your experiment (only generate the candidates or create the model also for immediate deployment). You can also choose to auto-deploy the model after it is generated.
6. After these steps, you can click on create experiment button which puts the Sagemaker Autopilot to work and generates the
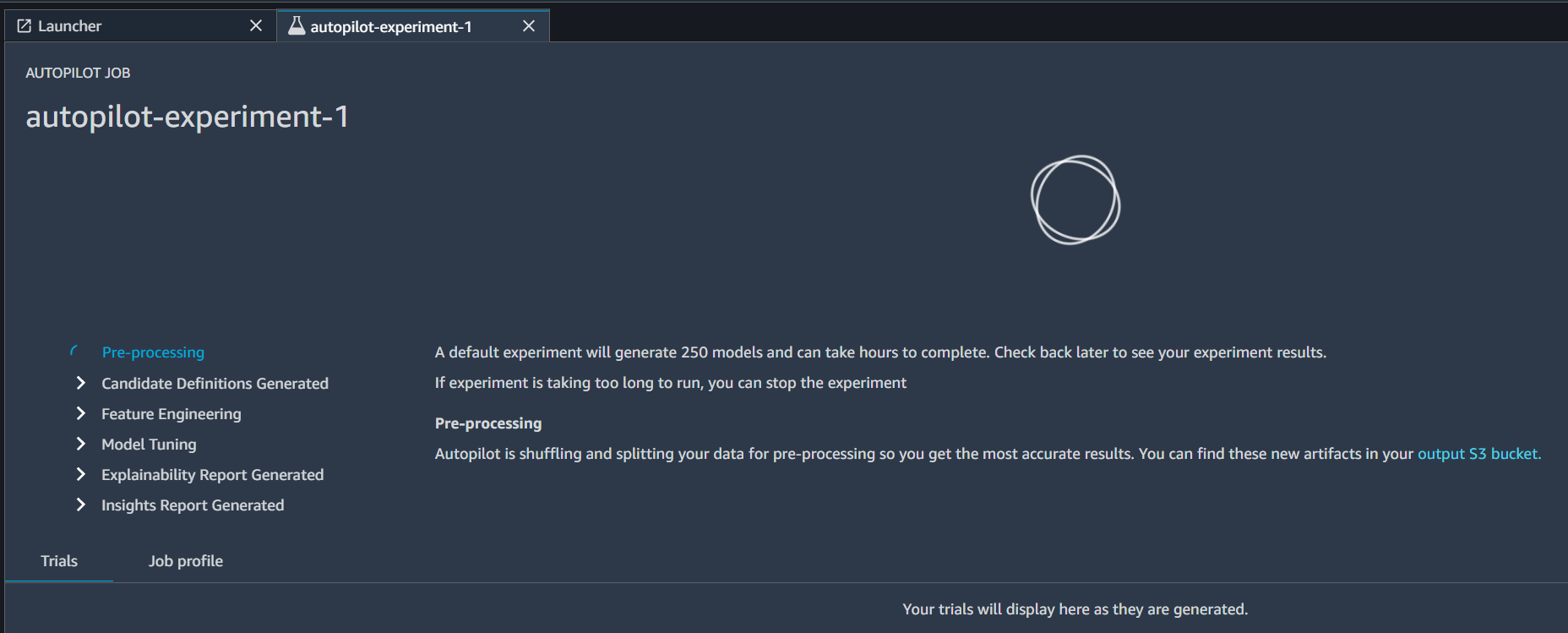
Notebooks Generated
If you remember the S3 bucket output location that we have provided while creating the experiment, it is here the Amazon Sagemaker creates 3 files. They are
- data exploration notebook
- candidate definition notebook
- model insights report
The data exploration notebook describes what Autopilot has learned about the data that you provided to it.
The Candidate definition notebook has information about all the candidates for the model generation. A candidate is nothing but a combination of preprocessing step, algorithm, and hyperparameter ranges. Each candidate has the potential to be the final model based on the metrics that the candidate generates.
Finally, the model insights report provides the model insights and charts only the best model candidate. This includes understanding false positives/false negatives, tradeoffs between true positives and false positives, and tradeoffs between precision and recall.
Autopilot Algorithm Support
These are 3 types of algorithms that Amazon Sagemaker Autopilot supports:
- Linear Learner Algorithm: It consists of a set of supervised learning algorithms used for solving either classification or regression problems.
- XGBoost Algorithm: It is a supervised learning algorithm that tries to accurately predict a target feature by combining estimates from a set of simpler and weaker models.
- Deep Learning Algorithm : It is a multilayer perceptron and feedforward artificial neural network. It can easily handle data that is not linearly separable.
It is not mandatory for you to provide an algorithm type to the Autopilot. Autopilot intelligently understands the problem and automatically chooses the correct algorithm based on the given dataset.
Autopilot Candidate Metrics
Amazon SageMaker Autopilot produces metrics that measure the predictive quality of machine learning model candidates. Here are some of them based on the problem type:
- Regression:- Mean Absolute Error, Mean Squared Error, R2, Root Mean Square Error.
- Binary classification:- Accuracy, AUC, F1, LogLoss, Precision, Recall, BalancedAccuracy.
- Multiclass classification:- Accuracy, F1macro, LogLoss, RecallMacro, PrecisionMacro.
Autopilot Model Deployment
There are three ways to deploy the models generated by the Sagemaker Autopilot.
- Automatically:- During the creation of the autopilot experiment, if you select the auto-deploy option, the Sagemaker will automatically deploy the best model from the experiment to an endpoint so that you can start interacting with the model right away. this is recommended for beginners.
- Manually:- You can choose not to auto-deploy your model for a number of reasons such as, you would wish to look at the steps and make changes to the preprocessing steps or the model itself and sometimes you would want to deploy the model in a completely different environment or cloud provider. In this case, you only need the model artifacts which are stored in the output S3 location.
- API calls:- Alternately, You can also deploy your model through API calls. In fact, you can create the entire experiment itself using the AWS SDK library. This is very useful if you wish to create AutoML jobs without logging into the AWS console.
Conclusion
So, to quickly recap, we have used the Amazon AWS Sagemaker Autopilot to create an autopilot experiment that will automatically generate the best ML model for the uploaded dataset. Then we have looked into what is the purpose of each notebook generated by Autopilot. We also discussed which algorithms are supported and what are the different ways to deploy a model generated by autopilot.
Autopilot can help any business to solve problems through machine learning without the need for the businesses having to hire ML experts which can save a lot of money. Even if the company already has a bunch of MLexperts, it speeds up the entire model development process reducing the time to market.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.





