This article was published as a part of the Data Science Blogathon.
The Apache Pig is built on top of Hadoop. Provides a stream of data processing for large data sets. Apache Pork offers a high-quality language. It is another way of quoting more than Reduce Map (MR). The pig system supports the simulation method. To record the pig, it provides the Latin Pig language.
.png)
Apache Pig takes Latin Pig texts and converts them into a series of MR works. Pig scripting has the advantage of using applications on Hadoop on the client-side. The editing environment is simple compared to standard languages like Java. Provides easy compatible execution; the user can write and use their customized functions to perform unique processing.
Apache Pig Latin provides several operators such as LOAD, FILTER, SORT, JOIN, GROUP, FOREACH, and STORE to perform related data operations. Operators use data conversion functions with simple lines of code. Compared to MR code, Pig Latin codes are much smaller in line and offer better flexibility in some IT industry applications.
Apache Pig Architecture
Pig Architecture contains the Pig Latin Interpreter and will be used on the Client Machine. It uses Pig Latin texts and converts text into a series of MR tasks. It will then extract the MR functions and save the effect to HDFS. In between, perform various tasks such as Parse, Compile, Prepare and Organize Performing data into the system.
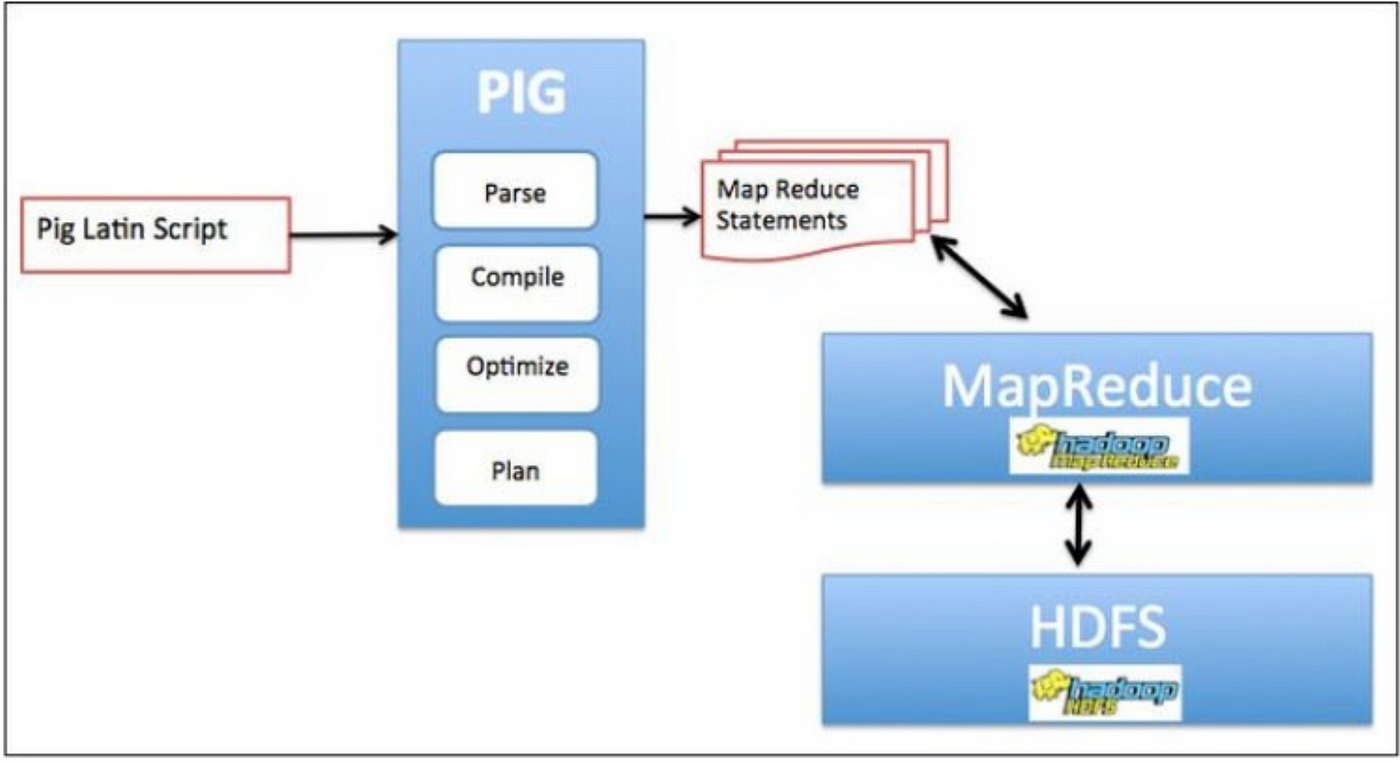
Performance flow
When the Apache Pig editor creates scripts, they are saved in a local file system in the form of user-defined tasks. When we move Pig Script, it interacts with the Pig Latin Compiler that separates the task and uses a series of MR tasks, while Pig Compiler downloads data to HDFS (i.e. the input file). After starting MR operations, the output file is saved in HDFS.
Pig Execution Modes
A pig can work in two ways of killing. Modes depend on where the Pig script will work and where the data resides. Data can be stored on a single machine, i.e. a local file system or can be stored in a distributed location like a normal Hadoop Cluster. We can use pig programs in three different ways.
The first is a non-compliant shell also known as script mode. In this case, we have to create a file, upload a code to the file and extract the script. The second is the grunt shell, the interactive shell of the Apache Pig command. Thirdly embedded mode, this time we use JDBC to run SQL programs in Java.
Pig Local Mode
In this mode, the pig works on a single JVM and accesses the local file system. This mode is best suited for dealing with small data sets. In this case, the removal of the corresponding map is not possible because previous versions of Hadoop versions are not secure.
By providing a local -x, we can enter the local Pig kill mode. In this mode, Pig constantly monitors the file system of the location where the data was uploaded. The local $ pig -x means it is in local mode.
Pig Map Reduce mode
In this mode, we may have the appropriate Hadoop setup settings and Hadoop installation in it. By default, the pig works in MR mode. Pig translates queries sent to Map cuts jobs and runs it over the Hadoop collection. We can refer to this mode as the Reduce Map mode in a fully distributed collection.
Latin pig statements such as LOAD and STORE are used to read data from the HDFS file system and to output. These statements are used to process the data.
Saving Results
During the processing and execution of MR operations, intermediate data will be generated. Pig stores this data in a temporary location on HDFS storage. To keep this data in the middle, a temporary location must be created within HDFS.
By using DUMP, we can get the final results displayed on the exit screen. In the production area, the results will be stored using the STORE operator.
Pig Use Case in Telecom Industry
Telecom Industry produces large amounts of data (Telephone details). In order to process this data, we use Apache Pig to exclude user call data details.
The first step is to store data in HDFS, use Pig scripts on uploaded data and improve user call data and download important call information such as duration, frequency, and other important log information. If the Unidentified Information exits, the result will be stored in HDFS.
Like this large amount of data comes to system servers and will be stored on HDFS and processed using scripts. During this process it will filter data, duplicate data and produce results.
The IT companies that use Pig to process their data are Yahoo, Twitter, LinkedIn, and eBay. They use Apache Pig to do most of their MR work. Pig is widely used to process web logs, standard data mining conditions, and image processing.
Relation
Now we will see a connection that looks like a bag or is like a table in some cases. We can say that the relationship is a bag, the bag contains tuples, the tuples contain fields and the entries are simple data. From the diagram, we can say that the relationship is the most external structure of the Latin pig data model. A relative can have many bags. As soon as we enter the database the data will be converted to tuples, bags, and relationships. So the pig handles the data in a different way.
- The relation is a bag (Like a table in some cases)
A bag is a collection of tuples. The bag is represented by flower braces. Example: {(10,iPhone),(20, Samsung),(30,Nokia)}. - The bag contains tuples
A tuple is a set of fields. Here Id and product_name form a tuple. Tuples are represented by braces. Example: (10, iPhone). - Tuples contain fields
A field is a piece of data. In the above data set, product_name is a field. - The relation is the most outspoken structure of the Pig Latin data model
Relation represents the complete database. A relation is a bag. To be precise relation is an outer bag. We can call a relation a bag of tuples.
Conclusion
Apache Pig is an open-source platform dedicated to analyzing large databases and representing them with the data flow. Using its advanced language, Pig Latin, users can improve tasks and write their texts to process data. These texts are converted into MapReduce functions using a component known as Pig Engine.
- The Working of Apache Pig
- Pig Architecture consists of Parser, Optimizer, Compiler & HDFS.
- Execution Modes like Local Mode & Pig Latin Mode
- Different types of Relation.
All the Important Topics are covered and this is all you needed to start working with Pig.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Data Analyst who love to drive insights by visualizing the data and extracting the knowledge from it. Automating various tasks using python & builds Real time Dashboard's using tech like React and node.js. Capable of Creaking complex SQL queries to fetch the accurate data.






