This article was published as a part of the Data Science Blogathon.
Introduction
One of the areas of machine learning research that focuses on knowledge retention and application to unrelated but crucial problems is known as “transfer learning.” In other words, rather than being a particular form of machine learning algorithm, transfer learning is a strategy or method used when training models. In transfer learning, a new task requires the reuse of a prior training model, at the same time, the new task will somehow relate to the one that was previously mastered. The old trained model often needs a high level of generalization to adapt to the new, unseen input.

Transfer learning refers to changing a network that has been trained to solve one problem to solve another. We might not always have enough data to train a machine learning model. Then, utilizing a parent model that had previously performed well on a comparable dataset, we may easily attain our end goals by altering the transfer learning approaches. We have two options: we may utilize the parent model exactly as it is, or we can use our small dataset to improve the model.
This is similar to how we perform in the final moments before tests. Assume that we didn’t have enough time to adequately prepare for the exam we have today. What do we typically do then? We will get in touch with a friend and request information about the subject of today’s exam. As a result, your friend who has well-prepared for the exam will import his/her knowledge to you. So in a short period of time and without the aid of any other resources, you will get sufficient confidence in that subject. So why are you still standing there? Go to the exam room and do your best on the answer sheet. I wish you all the very best✌️.
We can map many of our real-world daily situations to the idea of transfer learning, as we can see in the example above. So during the past three to four years, it has gained a lot of popularity. Many AI-based organizations are currently seeking employees with sufficient transfer learning experience and knowledge.
I will therefore demonstrate and discuss the top 10 questions to gauge your Data Science proficiency in this blog. Therefore, before getting started, I hope that this article will be useful for beginners to understand transfer learning. Use this opportunity to assess your transfer learning abilities if you have any prior knowledge of the subject.
Questions
1 – How would you define “Transfer Learning”? List some transfer learning models?
Ans: Transfer learning is the process of teaching one model to teach another model without starting from scratch. It applies important features of an existing model to solve related machine learning issues.
Few transfer learning models:
- GTP-3
- BERT
- Resnet-50
- VGG-16
- Inception V3
- XCeption
2 -What kinds of deep learning transfer learning techniques are there?
Ans: A variety of transfer learning approaches are extensively used in the field of data science. They do.
- Domain adaptation- In situations when the marginal probabilities between the source and destination domains differ, like P (Xs) ≠ P (Xt), domain adaptation transfer learning is used.
- Domain confusion- Multiple layers in a deep neural network gather different feature sets. We can now acquire domain-invariant features and improve their domain mobility due to this matter. Instead of letting the model learn any feature, we reduce the representations of both domains to be as relatable as possible. The fundamental idea behind this tactic is to add another purpose to the source model to boost similarity by confusing the domain itself.
- Multitask learning- In this case, there is no distinction between the source and the objectives, as different tasks are being learned simultaneously.
- One-shot learning- Deep learning tasks in which the model is only given a single training data instance and must learn to recognize the same instance in the testing data.
- Zero-shot learning- It doesn’t need labeled examples to learn a task, it is another extreme example of transfer learning. Multiple adjustments are made during the training phase using zero-data learning to benefit from new knowledge and understand data that is completely stranger to the model
3. List and write a small description of some Image Processing transfer learning models
Ans:
- Inception
- This module seeks to operate as a multi-level feature extractor by doing 1X1, 3X3, and 5X5 convolutions within the same network module. The output of these filters is then fed into the following layer of the network and is stacked along the channel dimension.
- VGG-16
- VGG16 is an object identification and classification algorithm that, when used to classify 1000 images into 1000 separate categories, has an accuracy rate of 92.7%. It is a popular method for categorizing photographs and is easy to use with transfer learning. The sixteen in VGG16 stands for sixteen weighted layers.
- Xception
- The depth-wise separable convolutions used in the Xception replace the typical inception model in the inception architecture.
- ResNet
- In contrast to traditional sequential networks like VGG, unconventional architectures like ResNet rely on microarchitecture modules, which are also referred to as networks in the architecture. A new network is built using a collection of parts known as microarchitecture.
4. List and write a small description of some Natural Language Processing transfer learning domains
Ans:
- Open AI GPT Series
- Deep learning is used by Generative Pre-trained Transformers (GPT), an autoregressive language model, to create text that sounds like human speech. GPT-3, the most latest version of GPT in use, features a most complex version with around 175 billion parameters. GPT-4, the next version in the series, is scheduled for release in the middle of 2022.
- BERT Variations
- Bidirectional Encoder Representations from Transformers, or BERT, is a state-of-the-art machine learning model that is used for NLP applications. Based on the transformer’s encoder part, Google created this model of a transformer. The original BERT, RoBERTa (created by Facebook), DistilBERT, and XLNet are some further BERT variations.
- ELMO Variations
- ELMO, which stands for Embeddings from Language Models, is a word embedding system for representing words and phrases as specified fixed length vectors. The Allen Institute for Brain Science developed ELMO, which simulates the syntax, semantics, and linguistic context of words. BERT and GPT models are both based on transformer networks, in contrast to ELMO models, which are based on bi-directional LSTM networks.
5. What are the Different ways to Transfer Learning?
Ans:
1. Training a model and reusing it
Think about doing Task A but failing to train a deep neural network architecture because of a shortage of data. One way around this is to find a different task B that is relevant and has a tonne of data. After training on problem B, the deep neural network architecture is used to complete task A. Whether you need to use the complete model or just a few levels will depend on the problem you’re trying to solve.
2. Using a pre-trained model
The second method is to use a model that has already been trained. Do some preliminary study because there are numerous models of these products accessible. Different layers should be recycled and retrained depending on the problem.
3. Feature Extraction
The objective of this approach is to use deep learning to pinpoint the representation of your problem that is most important. Performance obtained using this method, also known as representation learning, typically outperforms that obtained using manually created representations. The representation obtained can subsequently be used to address other problems.
6. What is fine-tuning in Transfer learning?
Ans: Applying or using transfer learning requires some changes. Fine-tuning, in particular, is the process of improving or modifying a model that has already been trained to carry out a first, custom perticular job in order to have it carry out a second, related job. In NLP, fine-tuning is, in other words, the act of retraining a language model that has already been trained using your own particular data. As a result of the fine-tuning job, the weights of the first model are changed to take into consideration the characteristics of the domain data and the job you are interested in.
7. Explain different strategies for fine-tuning
Ans: The pre-trained artificial neural network’s softmax layer is typically left out and replaced with a new softmax layer that is appropriate for our custom particular case.
Reducing the learning rate of the network when training the network is another option.
A common strategy is to reduce the first learning rate by a factor of ten from the learning rate used for scratch training.
Freezing the weights of the first few layers is another custom procedure.
The weights of the pre-trained network’s first few layers are almost frozen. This is because the early layers preserve a generic set of elements, like edges and curves, which are relevant to our present issue. Those weights have to stay the same. Instead, we’ll focus on teaching the network’s subsequent layers properties specific to a given dataset
8. What are the differences between pretraining and finetuning?
Ans: The pre-training procedure involves teaching the model on a sizable generic corpus. When it is modified to fit a particular task or dataset, the process is called “fine-tuning.” While finetuning can be done with a small amount of equipment, pretraining needs a lot of computational power and data. The network layers will update their weights in both scenarios.
9. Explain different categories of transformer-based pre-trained models
Ans:
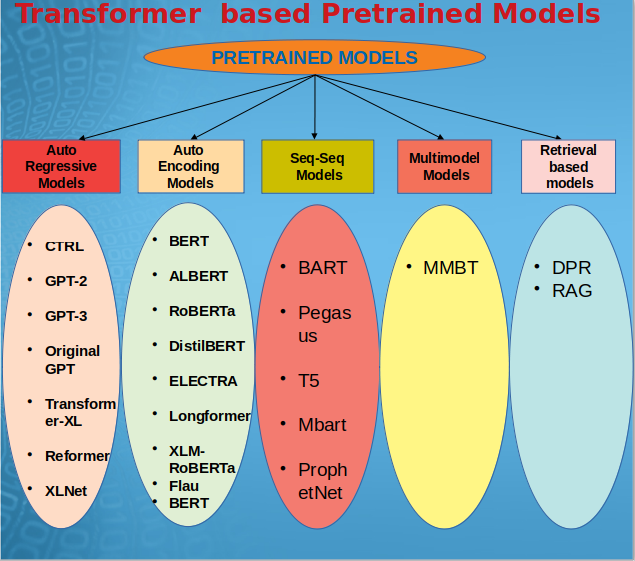
1 – Autoregressive-models
Autoregressive models are trained using the common language modeling task, which asks users to predict the next token after reading all the preceding ones. They represent the decoder in the original transformer model, and the entire sentence is covered by a mask so that the attention heads cannot perceive anything that follows what came before. Eg: GPT, CTRL
2 – Autoencoding-models
These models view every token in the attention heads because they don’t use a mask and just rely on the encoder part of the original transformer. For pretraining, the targets are the original sentences, while the inputs are the altered versions of those sentences. Eg: BERT, ALBERT
3 – Seq-to-seq-models
These copies have pre-trained encoders and decoders from the original transformer. Eg, T5, BART
4 – Multimodal-models
Unlike the other multimodal models, one has not undergone self-supervised pretrained. Eg, MMBT
5 – Retrieval-based-models
To respond to questions with an open domain during (pre)training, some models utilize document retrieval while others use inference. Eg: RAG, DPR
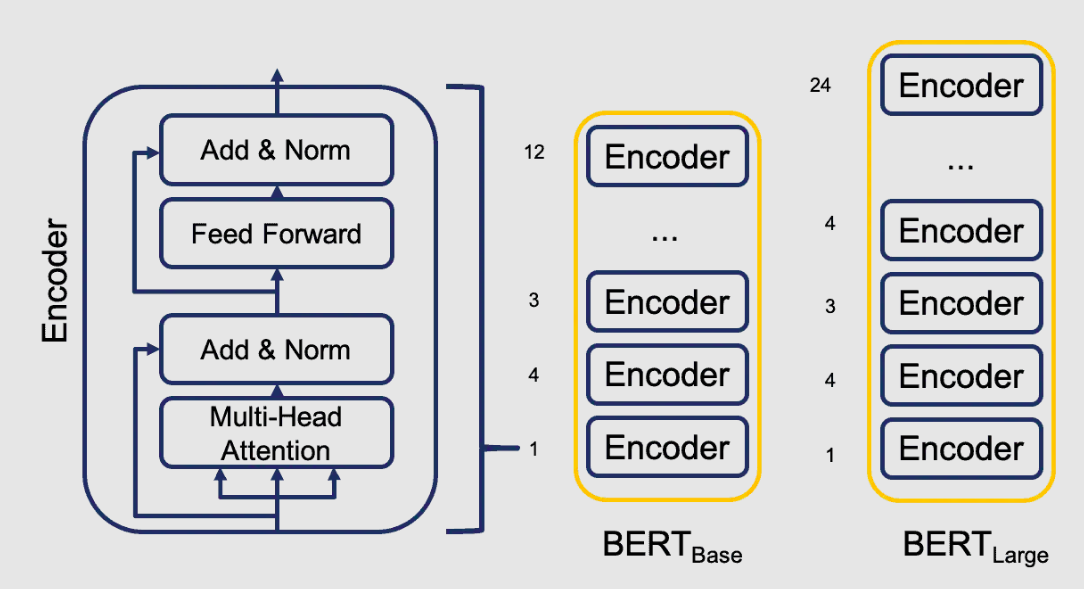
10: Compare the pre-trained models BERT-base with BERT-large
Ans: An encoder stack serves as the basis of BERT. BERT base and BERT large difference in the number of encoder layers. The BERT base model only contains 12 levels of encoders, as opposed to the BERT large, which has 24 layers of encoders stacked on top of one another. As the number of layers in a BERT large rises, so do the number of parameters (weights) and attention heads. The complete BERT base has 110 million parameters and 12 attention heads. Contrarily, BERT large has 340 million parameters and 16 attention heads. Compared to BERT base’s 768 hidden layers, BERT large has 1024.
Conclusion
Transfer learning has become one of the most important abilities for data scientists today. Transfer learning enhances the environment in addition to the technical advantages. According to research published in the MIT Technology Review, a big neural network (trained on a cloud TPU) with 200M+ parameters generates the same amount of carbon dioxide over its lifespan as six cars. Transfer learning can cut down on the time these powerful processing units are employed.
Major points to remember
- One area of machine learning research is transfer learning, which focuses on using knowledge learned from addressing one problem to solve another that is around similar to the first problem.
- Various transfer learning-based pre-trained models for NLP and computer vision are available nowadays. Eg: VGG-16, BERT, Resnet-50
- A model that has already been trained to carry out one particular activity is fine-tuned to enable it to carry out a second task that is similar.
- Depending on our use case, various fine-tuning strategies are available.
- The main subcategories of transformer-based pre-trained models include autoencoding, autoregressive, seq-seq, multimodel, and retrieval-based models.
I hope this article enabled you to better understand and assess your transfer learning knowledge. Feel free to leave a remark below if you have any questions, concerns, or recommendations.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
A passionate data scientist. I love to explore data and extract insights that can help solve complex problems. With my knowledge of programming languages such as Python, I am proficient in developing models and analyzing large data sets. My passion for learning has led me to continuously expand my skillset and stay up-to-date with the latest trends in the field. I am committed to using data science to make a positive impact on society and believe that the power of data can transform businesses and organizations.






Really informative post. Thanks for sharing.
Good and useful job for data scientist. Great!