
Introduction
Training and inference with large neural models are computationally expensive and time-consuming. While new tasks and models emerge often for many application domains, the underlying documents being modelled remain mostly unaltered. In light of this, to improve the efficiency of future training and inference with large neural models, the researchers from Allen Institute for Artificial Intelligence and Northwestern University have proposed an approach termed embedding recycling (ER).
Embedding recycling is a technique of caching the output of an intermediate layer from a pre-trained model and fine-tuning the remaining layers for a given task. This approach claims to provide 100% speedup during training and 55-86% speedup for inference and has negligible effects on accuracy for text classification and entity recognition tasks in the scientific domain. ER provides a similar speedup for general-domain question answering tasks and lowers accuracy by a small amount.
I stumbled upon this interesting research work the other day and was intrigued to learn more about their approach. This post is basically a summary article based on the aforementioned research paper. All credit for this research goes to the researchers of this project.
Now let’s dive in and see how the recycling embedding approach can be used to improve the efficiency of future training and inference with large neural models.
Highlights
-
The researchers from Allen Institute for Artificial Intelligence and Northwestern University have proposed an approach called embedding recycling (ER) which claims to improve the efficiency of future training and inference with large neural models.
-
Embedding Recycling (ER) is a technique of caching an intermediate layer’s output from a pre-trained model and finetuning the remaining layers for new tasks.
-
ER claims to provide 100% speedup during training and a 55-86% speedup for inference and has negligible effects on accuracy for text classification and entity recognition tasks in the scientific domain. Additionally, ER provides comparable speedup with a small loss in accuracy for question-answering tasks.
Method Overview
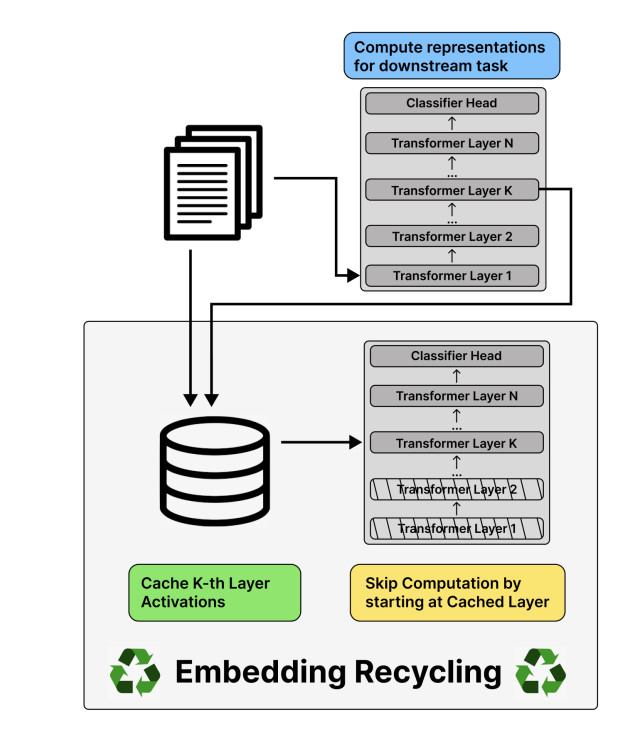
Figure 1: Overview of the embedding recycling approach (Source: Arxiv)
The key idea is to cache the output representations at a certain k-th layer and reuse them for fine-tuning on a new given task, skipping the redundant computations of earlier layers in the transformer model. This technique of caching and reusing the output representations of a layer is called “layer recycling”.
-
In layer recycling, we have an initial pre-trained transformer F consisting of F(1), …, F(k), …, F(N). The entire data (corpus) is processed with the transformer model. Then the output representations of the certain k-th layer are cached at each instance so that the representations can be reused during the fine-tuning and inference of new tasks.
-
The same transformer model is then used for fine-tuning on new tasks; however, instead of fine-tuning on all the layers, only the parameters of N-k layers are fine-tuned.
-
At this point, we can either train all of the weights in these layers (also referred to as reduced models) or train only adapters added to the layers. In either case, the previously cached representations are retrieved and used as input to F(k+1).
-
The layer recycling enables us to shrink the size of the transformer model from N layers to (N-k) layers, consequently reducing the computational cost during fine-tuning and inference. However, it does add a small cost for retrieving the representation from the storage.
Results
1. Text Classification and NER Tasks Result Comparison
For text classification and NER tasks on BERT-sized models, it was found that the reduced models generally offer similar performance to their full fine-tuned counterparts (Table 1) and significantly outperform the distilled models. For RoBERTa-large, the reduced models have the same accuracy as that of full fine-tuning, demonstrating the benefits of embedding recycling. On average, reduced distilled models also performed well compared to the distilled originals, although there is more variance across models and tasks compared to BERT-sized models.
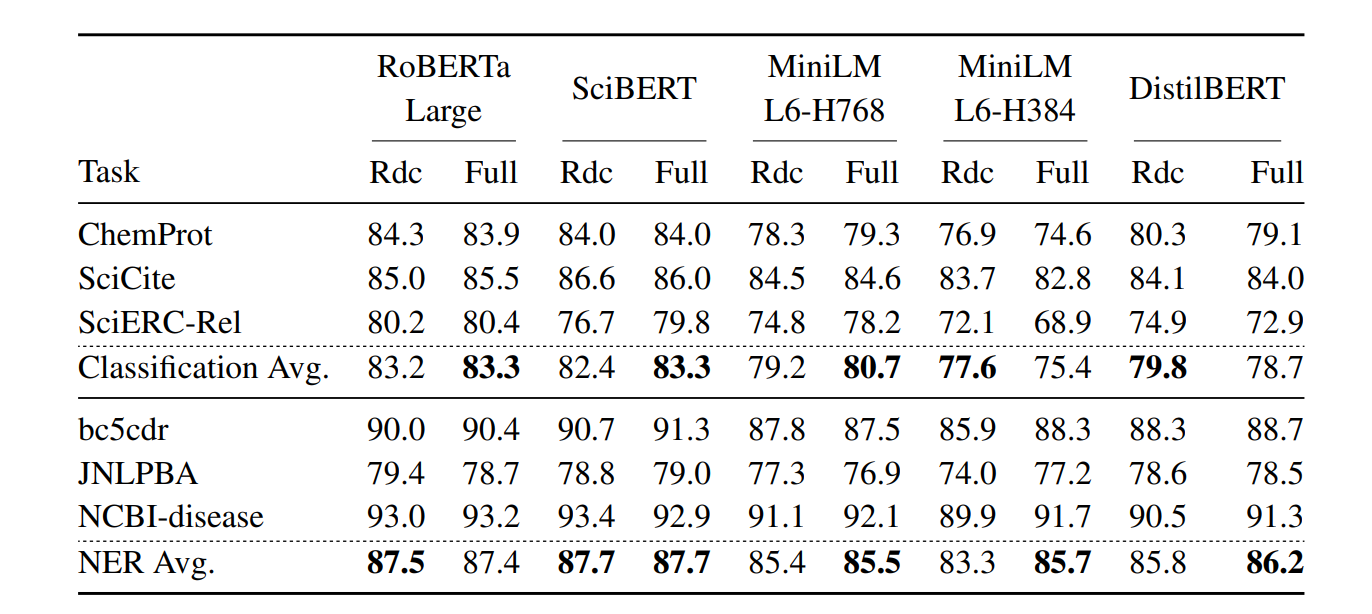
Table 1: Test scores of reduced (Rdc) and fully fine-tuned models on the text classification and NER tasks.
2. QA Tasks Result Comparison
For QA tasks, the fully fine-tuning works a little better than reduced configurations across all the explored models (Table 2). In the future, task-specific choices for
which layer to recycle needs to be studied.
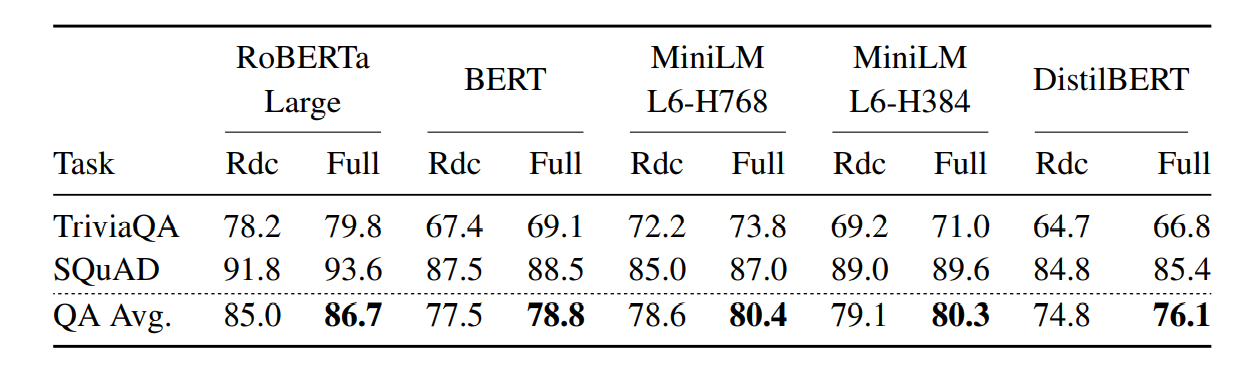
Table 2: Test scores of reduced (Rdc) and fully fine-tuned models on the QA tasks. The reduced models offer a small accuracy drop for QA tasks.
3. Average Inference Run-time Comparison
The inference time varies across tasks depending on dataset properties, such as length of sequences and number of samples, so the experiments were controlled by simulating a sequence classification task on QASPER. Table 3 shows the Average inference runtime comparison between vanilla encoders and models that cache embeddings on disk.
For all the runs, the middle layer of the encoder was cached, and it was found that the larger the model, the higher the speedup from re-using representations. Further, accelerators with fewer execution units (A10G) benefit more from recycling embeddings. For training, perfect speed-up scaling (i.e., 100%) for all models and hardware was observed.
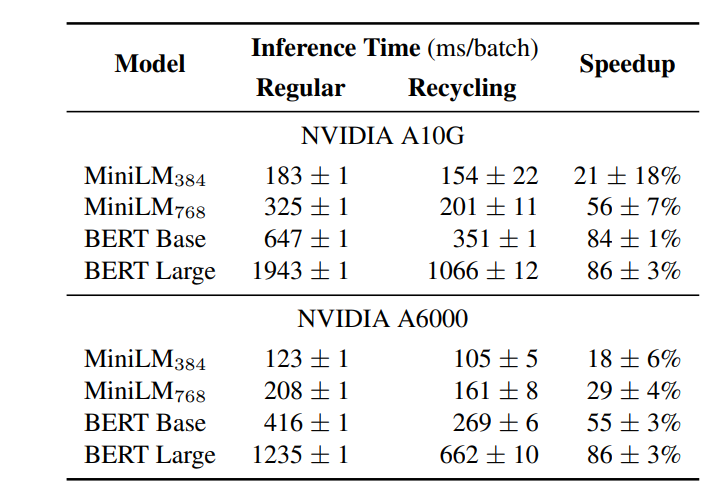
Table 3: Average inference runtime comparison between vanilla encoders and models that cache embeddings on disk.
4. Adapter configurations match or improve the performance of the fully fine-tuned transformer models on the text classification and NER tasks. For QA tasks, adapters don’t seem to benefit RoBERTa and BERT which lags about 1-2 points F1 compared to full fine-tuning.
5. Cross-model embedding reuse was not found to be effective in the experiments, i.e. the larger model’s (source model) contextual representations do not improve the smaller model’s (consumer model) accuracy. Adding them decreases the average F1 score. However, using rich contextualized embeddings from a large model to power a much smaller downstream model is an important application setting for ER; approaches for this need to be developed and investigated in the future.
Future Work
Following are the promising avenues for future research:
1. Determining how to best capture and store the syntactic and semantic knowledge encoded in the activations of a model for later recycling.
2. Considering that the optimum recycling approach can be task-specific and model-specific, it’s necessary to devise solutions that can automatically choose which embeddings to retrieve and recycle and the best optimum model to use for a given task, accuracy goal, and computational cost.
3. Results with encoder-only models were thoroughly investigated. Experiments with generative tasks, autoregressive models, and encoder-decoder models need to be undertaken in the future.
4. Testing whether the quantization technique remains effective when coupled with Embedding Recycling as it was when used with distillation for inference speedup. Furthermore, the effect of combining the ”late start” of layer recycling ER with early exit techniques on inference-speedup needs to be studied.
5. Considering that even an entirely new document will have some similarities and overlapped spans with previously processed document(s), it’s necessary to determine how to recycle previously-computed embeddings.
6. Using rich contextualized embeddings from a large model to power a much smaller downstream model is an important application setting for ER and developing
and evaluating new approaches for this is a promising avenue for research.
Conclusion
In this summary article, we learned how embedding recycling, a technique of caching the output of an intermediate layer from a pre-trained model and fine-tuning the remaining layers for a given task, can be used to lower the computational expenses of future training and inference. This approach provides substantial efficiency boosts for text classification and NER tasks in the scientific domain. Additionally, ER provides comparable speedup with a small loss in accuracy for question-answering tasks.
Code and Documentation are available at: https://github.com/allenai/EmbeddingRecycling/tree/main/recycling-code-demo
Thanks for reading. If you have any questions or concerns, please leave them in the comments section below. Happy Learning!
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I'm a Researcher who works primarily on various Acoustic DL, NLP, and RL tasks. Here, my writing predominantly revolves around topics related to Acoustic DL, NLP, and RL, as well as new emerging technologies. In addition to all of this, I also contribute to open-source projects @Hugging Face.
For work-related queries please contact: [email protected]






