This article was published as a part of the Data Science Blogathon.
Introduction
Even small companies today have an average of 47.81 terabytes of data to manage. Whether you’re a small company or a trillion-dollar giant, data makes the decision. But as data ecosystems become more complex, it’s important to have the right tools for the job.
.png)
One modern data management tool that can help manage data of really any size from a wide variety of data sources is Presto. Presto has been the backbone of many big tech companies like Netflix and Lyft. But Presto isn’t limited to helping big tech companies or even big companies in general. New technologies have made Presto popular with companies of all sizes recently.
In this article, we’ll discuss what Presto is, why companies use it, and how your company can implement it with companies like Starburst Data so you can take full advantage of it for your business.
What is Presto?
Presto is an open-source distributed SQL query engine running interactive analytical queries on data sources of all sizes, from gigabytes to petabytes. Unlike many other SQL engines, which were often written for particular databases, Presto can sit on top of many databases. Specifically, Presto allows you to query data where it lives, including Hive, Cassandra, relational databases, or even proprietary data stores. Presto helps us to join data in data stores and databases. This means you don’t need to centralize all your data to perform ad hoc queries. This begins to bring us to the next point.
Why use Presto?
Presto is very platform agnostic. Whether in the cloud or on-premise, this technology is versatile and used by big companies like Netflix and Lyft, but it’s also popular with small companies and startups. These companies chose to use Presto because it can easily create a self-service BI layer accessible to more than just data engineers. The fact that data can be queried across data sources allows Presto to provide more agile access to data by data consumers. But this is only one of the many advantages Presto offers users. Managing and querying terabytes of data in Big Data is normal. This leads to slower queries. That’s a problem. Analysts want their queries to be faster.
Presto provides fast queries by leveraging known and new techniques for distributed query processing. These techniques include in-memory parallel processing, chained execution across nodes in a cluster, a multi-threaded execution model that keeps all CPU cores busy, and efficient flat memory data structures.
Presto Limitations
For everything great on Presto. Presto was developed as a simple SQL Engine. This means you will have to manage scaling, security, monitoring, and also create new connections yourself. This means that your teams won’t be able to easily lock down data if only he is the one to manage it.
This can often make Presto unaffordable because, with all its benefits, it is difficult to manage. This is where companies like Starburst Data stepped in and built the infrastructure around Presto.
What are Starburst dates, and how can they help?
Starburst Data makes Presto implementation easy. Starburst Data provides all the benefits of Presto, such as reducing the time it takes for analysts to access data in almost any data source. In addition, Starburst Data helped develop several security features, such as Global Security for fine-grained access control, data encryption, data masking, and query auditing.
Plus, Starburst Data makes it easy to manage your Presto scaling calculation. If you tried to manage Presto yourself, you would have to develop your software to manage how Presto scaled with increasing queries. Developing any of these features in-house is expensive and requires an entire extra team. So now we know what, why, and how. But let’s answer a few places.
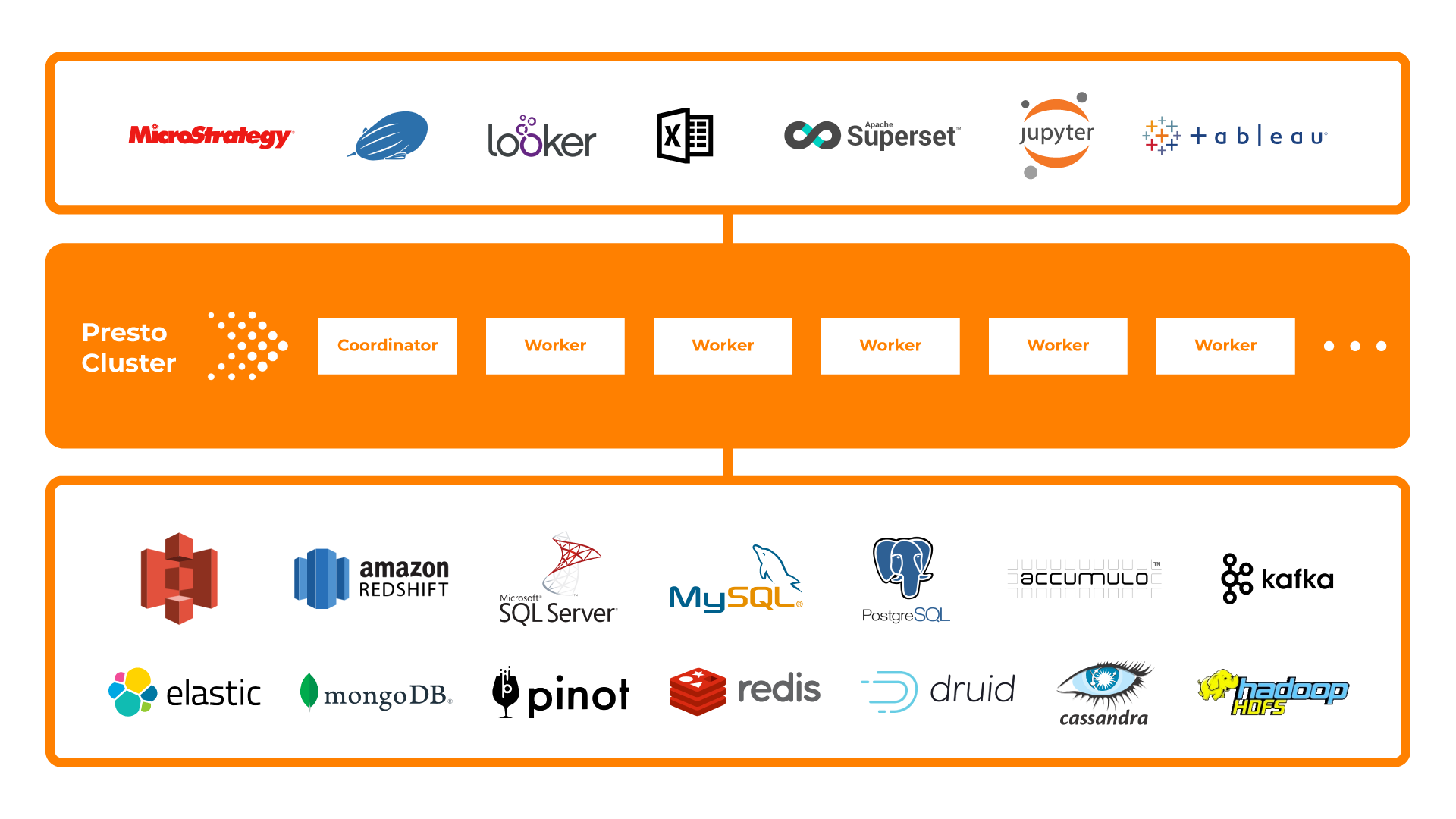
Source: ahana.io
Use Cases
Below we’ll discuss a few use cases where companies are already using Presto and some general examples of how your team can use Presto.
Netflix’s Big Data Platform
Netflix is one of the many companies that have leveraged Presto as their big data platform. Netflix has use cases ranging from analyzing A/B test results to analyzing user streaming to training data models for their recommendation algorithms. Using standard data warehouse tools wasn’t enough for Netflix.
That’s why Netflix turned to Presto. Presto has helped solve ad hoc interactive use cases for companies. They needed a data storage system that could manage all their different use cases at scale. Presto was a storage system for Netflix. But Netflix isn’t the only company using Presto for the computing part of its data warehouse.
Data Lake and SQL Engine in Lyft
In early 2017, Lyft started exploring Presto use cases for OLAP, and we realized the potential of this amazing query tool. Now thousands of dashboards inside Lyft use Presto and its ability to manage large users. Before Presto, Lyft relied on AWS-Redshift and had interconnected data storage and computing.
Multiple compute and storage caused many performance issues. For example, polling would be very slow if the system required maintenance, upgrades, downtime, or node scaling. They needed a system where data and computation were separated, so Presto fit our use case beautifully.
Thanks to these improvements, Lyft’s backend now manages approximately 1.5 thousand weekly active users who run several million daily queries on its platform.
Self-service BI
At the end of the day, getting access to the right data remains the bottleneck for data analytics, machine learning, and data science. Data engineers and data architects must constantly work to integrate, migrate, and design new data warehouse tables. With more data coming in from all directions and increased demand for data-driven decisions, Presto can help increase the pressure on data engineers and data storage systems. Presto enables analysts to combine data from different data sources.
This includes systems like Hadoop, S3, and Cassandra with other resources like a traditional relational database. With Presto, you can finally stop moving data just to query it! Starburst allows you to enjoy the performance benefits of Presto and the benefits of using a Presto instance built for Enterprise use.
Data Lakes
We discussed data lakes in the Lyft example. But we wanted to discuss it separately. The great thing about Presto is that it’s not limited to querying structured data. Presto offers a decent amount of field and map functionality.
This means teams can work with less structured data and still use SQL to analyze the information. In addition, Presto, especially in partnership with Starburst Data, can access data from almost any data storage system, whether it’s Hadoop or S3. The ability to query data where it is makes Presto a good computing layer for data lakes.
Conclusion
Presto provides many benefits for companies of all sizes. In particular, the ability to query data where it is reduces the amount of time data engineers need to spend developing complex ETLs. This means your teams can answer questions their business owners have more quickly. This is a huge advantage and coupled with Starburst Data; it is easy to use Presto relativity.
- Instead of needing a large team to manage your Presto clusters, you can easily have 1-2 engineers manage and grow your data infrastructure. And if your team needs help implementing Presto and Starburst Data, contact us today.
- Our data science and engineering consulting team can help you build everything from big data platforms to machine learning models.
- Presto is very platform agnostic. Whether in the cloud or on-premise, this technology is versatile and used by big companies like Netflix and Lyft, but it’s also popular with small companies and startups.
- Starburst Data makes Presto implementation easy. Starburst Data provides all the benefits of Presto, such as reducing the time it takes for analysts to access data in almost any data source. In addition, Starburst Data helped develop several security features, such as Global Security.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I am a Machine Learning Enthusiast. Done some Industry level projects on Data Science and Machine Learning. Have Certifications in Python and ML from trusted sources like data camp and Skills vertex. My Goal in life is to perceive a career in Data Industry.






