This article was published as a part of the Data Science Blogathon.
Introduction
In today’s world, we all use many platforms for entertainment, like youtube, in the initial stages. Further, going forward, many platforms emerged like Aha, Hotstar, Netflix, Amazon prime video, Zee5, Sony Liv, and many more. First, we will see a video or movie based on our interest by searching for the desired movie on the search engine. The recommendation system works here. The system will analyze the video or the movie which we have watched. Analysation may be based on the film genre, cast, director, music director, etc. Based on this analysis made by the recommendation system, we will be getting some recommendations for the next videos.
Source: Reddit
Recommendation System
A recommendation system is a system that filters all the videos or movies based on our preferences and our watch history and provides recommendations to the users.
Let us build a recommendation system.
Dataset
Before processing further, we need a dataset to work on.
You can download the movies dataset from here: Dataset
This dataset contains two CSV files. One is credits, and the other is a movie file. We will explore these files later. This file contains columns like budget for the movie, genres, homepage, id, keywords, original_language, original_title, overview, popularity, production_companies, production_countries, release_date, revenue, runtime, spoken_languages, status, tagline, title, vote_average, vote_count.
The file contains columns like title, cast, and crew in credits.
Tools and Libraries used
- Python – 3. x
- Pandas – 1.2.4
- Scikit-learn – 0.24.1
Command used to install the libraries is
pip install pandas scikit-learn
To install the packages following code is used
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.metrics.pairwise import linear_kernel
from sklearn.metrics.pairwise import cosine_similarity
from ast import literal_eval
A recommendation system is either a program or an algorithm for which the input is the watch history, search history, etc.. and analyses the genre, cast, director, and so on, and based on this analysis, some movies are recommended for the users, That is how the recommendation system works either for a product selling platform like Amazon, Myntra, Flipkart, or for an OTT platform like Netflix, Amazon prime Video, Aha, and so on.
Types of Recommendation System
Generally, there are three types of recommendation systems.
1. Demographic filtering
2. Content-based filtering
3. Collaboration-based filtering
Let’s see them one by one.
Demographic filtering: In this, the recommendations are the same for every user despite their interests. For example, let’s take the top trending movies column in ott platforms. These are the same for every user. Demographic filtering is the system behind it.
Content-based filtering: Filterings are based on movie metadata. Metadata contains details like movies, songs, products, etc. Based on this data, the system will recommend related movies so the user will like them.
Collaboration-based filtering: Here, the system will group users with similar interests and recommend movies to them.
Source: Better Programming
Analysis
To analyze, we need two data sets. One dataset contains movie names and movie IDs. Another dataset contains the remaining information about the movie.
To work with data frames, we need to import pandas data frames. Then pass the path of CSV files into it.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.metrics.pairwise import linear_kernel
from sklearn.metrics.pairwise import cosine_similarity
from ast import literal_eval
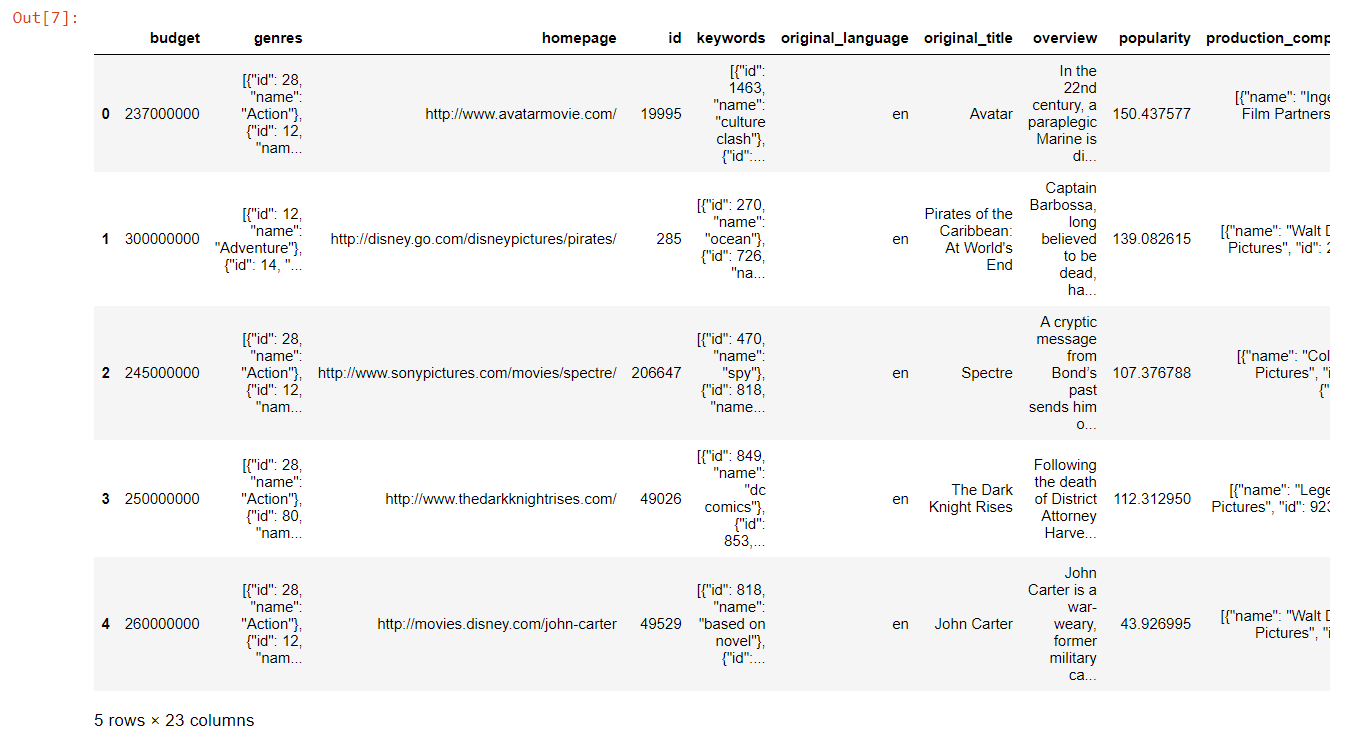
credits_df = pd.read_csv("tmdb_5000_movies.csv")
movies_df = pd.read_csv("tmdb_5000_credits.csv")
print(movies_df.head())Let’s view the credits data frame.
credits_df.head()

Now merge both the datasets into the movie data frame and view it.
credits_df.columns = [‘id’,’title’,’cast’,’crew’]
movies_df = movies_df.merge(credits_df, on=”id”)
movies_df.head()
Build Movies Recommendation System
With the help of a description of the movie or the film’s story, the recommendation system works more accurately to predict personalized pictures.
But with the help of the movie data set and credits data set, the recommendations can be more personalized. For Example, if a movie is searched, the recommendation system should suggest some other movies with the same director. And it should also show some movies with the same cast and others with the same genre.
# Demographic Filtering
C = movies_df["vote_average"].mean()
m = movies_df["vote_count"].quantile(0.9)
print("C: ", C)
print("m: ", m)
new_movies_df = movies_df.copy().loc[movies_df["vote_count"] >= m]
print(new_movies_df.shape)
def weighted_rating(x, C=C, m=m):
v = x["vote_count"]
R = x["vote_average"]
return (v/(v + m) * R) + (m/(v + m) * C)
new_movies_df["score"] = new_movies_df.apply(weighted_rating, axis=1)
new_movies_df = new_movies_df.sort_values('score', ascending=False)
new_movies_df[["title", "vote_count", "vote_average", "score"]].head(10)
def plot():
popularity = movies_df.sort_values("popularity", ascending=False)
plt.figure(figsize=(12, 6))
plt.barh(popularity["title"].head(10), popularity["popularity"].head(10), align="center", color="skyblue")
plt.gca().invert_yaxis()
plt.title("Top 10 movies")
plt.xlabel("Popularity")
plt.show()
plot()
# Content-based Filtering
print(movies_df["overview"].head(5))
tfidf = TfidfVectorizer(stop_words="english")
movies_df["overview"] = movies_df["overview"].fillna("")
tfidf_matrix = tfidf.fit_transform(movies_df["overview"])
print(tfidf_matrix.shape)
# Compute similarity cosine_sim = linear_kernel(tfidf_matrix, tfidf_matrix) print(cosine_sim.shape) indices = pd.Series(movies_df.index, index=movies_df["title"]).drop_duplicates() print(indices.head())
Implementation
We need a function to implement the recommendation system that takes the movie we are searching for as input and similar movie names as output.
Index of the movie and similarity function is considered, like how many times it is being searched and similar movies with the help of the similarity function.
Movies coming as output to the similarity function are taken and arranged in descending order based on the index of that movie.
In that order, first, ten or fifteen movies are taken and are recommended to the users.
For things to happen in order following code is used.
def get_recommendations(title, cosine_sim=cosine_sim):
idx = indices[title]
sim_scores = list(enumerate(cosine_sim[idx]))
sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True)
sim_scores = sim_scores[1:11]
movies_indices = [ind[0] for ind in sim_scores]
movies = movies_df["title"].iloc[movies_indices]
return movies
print("# Content Based Filtering - plot#")
print()
print("Recommendations for The Dark Knight Rises")
print(get_recommendations("The Dark Knight Rises"))
print()
print("Recommendations for Avengers")
print(get_recommendations("The Avengers"))
Print the movie data frame with features, cast, crew, keywords, and genres.
features = ["cast", "crew", "keywords", "genres"]
for feature in features:
movies_df[feature] = movies_df[feature].apply(literal_eval)
movies_df[features].head(10)
def get_director(x):
for i in x:
if i["job"] == "Director":
return i["name"]
return np.nan
def get_list(x):
if isinstance(x, list):
names = [i["name"] for i in x]
if len(names) > 3:
names = names[:3]
return names
return []
movies_df["director"] = movies_df["crew"].apply(get_director)
features = ["cast", "keywords", "genres"]
for feature in features:
movies_df[feature] = movies_df[feature].apply(get_list)
Now print the movie data frame.
movies_df[['title', 'cast', 'director', 'keywords', 'genres']].head()
def clean_data(x):
if isinstance(x, list):
return [str.lower(i.replace(" ", "")) for i in x]
else:
if isinstance(x, str):
return str.lower(x.replace(" ", ""))
else:
return ""
features = ['cast', 'keywords', 'director', 'genres']
for feature in features:
movies_df[feature] = movies_df[feature].apply(clean_data)
def create_soup(x):
return ' '.join(x['keywords']) + ' ' + ' '.join(x['cast']) + ' ' + x['director'] + ' ' + ' '.join(x['genres'])
movies_df["soup"] = movies_df.apply(create_soup, axis=1)
print(movies_df["soup"].head())
Here the input data is taken, words are counted, and it’s repeated. Each word’s count is noted, and a separate field is given to that, this way, each word is converted into two dimension vector, in which one dimension is the word, and another dimension is its frequency
In considering the words, we should not include words like a, an, the as these words are repeated frequently.
count_vectorizer = CountVectorizer(stop_words="english") count_matrix = count_vectorizer.fit_transform(movies_df["soup"]) print(count_matrix.shape) cosine_sim2 = cosine_similarity(count_matrix, count_matrix) print(cosine_sim2.shape) movies_df = movies_df.reset_index() indices = pd.Series(movies_df.index, index=movies_df['title'])
Testing
Now, let’s print recommendations for The Dark Knight Rises and for avengers.
print("# Content Based System - metadata #")
print("Recommendations for The Dark Knight Rises")
print(get_recommendations("The Dark Knight Rises", cosine_sim2))
print()
print("Recommendations for Avengers")
print(get_recommendations("The Avengers", cosine_sim2))
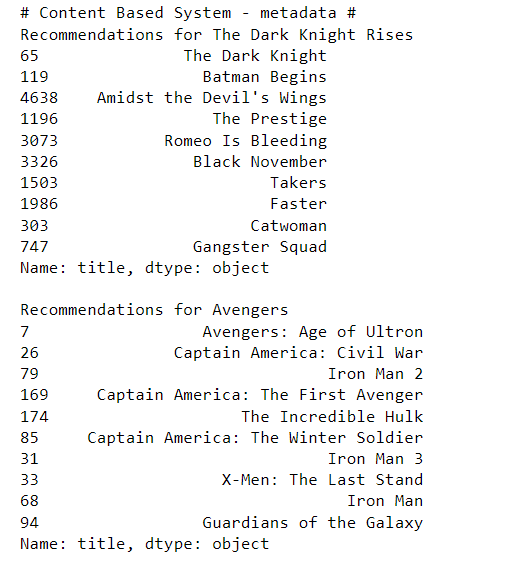
Thus, we can see how the system recommended movies based on the content. Here we can see the recommendations for the movie, The Dark Knight Rises, and the movie Avengers.
Conclusion
In today’s world, we can see that most people are using Netflix, Hotstar, and many other ott platforms. In that, we can see that movies are being recommended to us based on our watch history. Not only these, but you can also observe while watching Instagram reels and youtube shorts. These videos are also recommended based on our watch history. This is where the recommendation system works. And that we had built in this article.
Overall in this article, we have seen,
- What is a recommendation system
- Types of recommendation systems
- How to build it, implement it, and finally, we tested it.
I hope you guys found it useful.
Connect with me on Linkedin.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Hello Everyone,
This is Srivani. I had completed my B.Tech in the computer science department. I am interested in Data Science and programming. Thanks for reading my articles and hope you get knowledge from them.






