This article was published as a part of the Data Science Blogathon.
Introduction
We know that Machine Learning Algorithms need preprocessing of data, and this data may vary in size. If we do not have enough computing power to pre-process it, we can not proceed with analyzing it, and then the question is how to load and process such a large amount of data using the available system.
The first thing here is to know if this question is valid or whether such a situation comes or not. The answer is YES; this question is valid because nowadays, a common man also produces a large amount of data. We are living in an internet economy where we are producing data 24×7. And that’s why we can say that companies have large data and need to process it, and here comes our question. How can we process it?
Following are some of the approaches that we can use to handle large amounts of data:
- Sub Sampling
- Cloud Computing
- Out of Core ML
Subsampling
If we have a large dataset and want to process it, the simplest way is to use Subsampling. It uses the simple concept of reducing data. Data can be reduced by removing some of the samples or features or sometimes removing both features and samples.
Subsampling is a procedure that creates a new dataset with a given percentage size of the original sample, where sampling is performed randomly.
Pandas have a compelling method to perform subsampling data using the sample() function, which has various helpful parameters to manage the sampling process.
DataFrame.sample(n=None, frac=None, replace=False, weights=None, random_state=None, axis=None, ignore_index=False)
Parameters:
− n: int (optional): the number of items to sample
− frac: float (optional): the proportion (out of 1) of items to return
− replace: bool (default False): whether to sample with replacement (i.e., items can be sampled more than once)
− weight: str or ndarray (optional): by default, samples are equally weighted. A series indicating weights can be applied. If they do not add to 1, they will be normalized to 1.
− random_state: int: a seed number to produce reproducible results.
− axis: 0 or ‘index’, 1 or ‘columns’: the axis to sample.
− ignore_index: boolean (default False): if we want to perform reindexing or not.
Let’s see the simplest implementation of subsampling in terms of percentage using pandas on the famous titanic dataset as.
Here we can see that there are 10692 records present in our dataset. Now let’s look at an example where we will pull 1% of the records using the sample’s frac parameter ().
sample_df = df.sample(frac=0.01) print(sample_df.size) sample_df
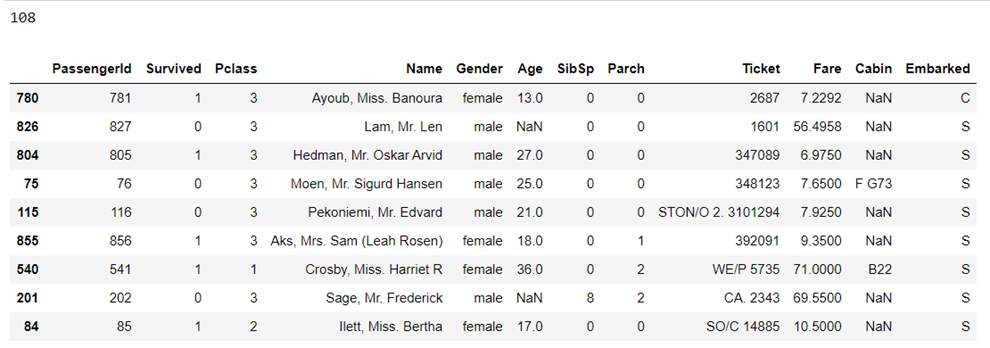
We can see that 1% of the data frame is sampled (108 records). Here, the first column represents the index from the original data frame. We can reset it using ignore index parameter.
But the main problem with subsampling is data loss. And we know that data is essential in ML, especially when we want to build a good model.
Cloud Computing
This is another way to handle a large dataset. Anyone can use various cloud service providers like Amazon AWS, Google Cloud Platform, or Microsoft Azure.
In cloud computing, we can configure the server as per our requirement, where we can configure memory (primary memory or core memory) ranging from Gigabyte to Terabyte.
The main disadvantage of the cloud platform is its Cost.
Out-of-Core ML
Out-of-core ML takes the reference from the concept of core memory which is nothing but RAM. We can say that out-of-core memory is only external memory which may be HDD.
If we want to define what is Out of Core ML in layman’s terms, it would be:
“It is a way to train your model on data that cannot fit your core memory.”
Out-of-core learning refers to the machine learning algorithms working with data that cannot fit into a single machine’s memory but can easily fit into some data storage, such as a local hard disk or web repository.
There are three ways to perform it in three steps:
- a. Streaming data
In simple terms, streaming data is nothing but loading your data in mini-batches from secondary storage like HDD or web repository into the core memory. For example, if we have 10GB of data, we can divide it into 10 batches of 1 GB each. We will load the first 1GB, process it after processing, removes it from core memory, and load the next batch.
But to do this, we need a reader. Generally, we call it a data reader. This reader facility is provided by Pandas IO library, which allows us to read data in chunks. In deep learning, Keras has built-in data readers. In Machine Learning, the Vaex library is specifically designed for such operation.
- b. Extracting features
Once a chunk of data is in RAM or core memory, we need to extract features from that data. These features we extract from data are used as input for the ML model. This feature extraction is a little tricky part.
- c. Training model
In normal conditions, we have all our data in RAM to train our model on that data. But here, we are not able to load all data in memory. Even though we extract features in the second step, those features may be larger than RAM.
Because of this, we cannot train all the data at once using a single machine learning algorithm.
Here, we can use the concept of Incremental Learning, where we train the machine learning algorithm by providing data in batches.
As we can see in the above figure, 1st chunk is given as input to Model M which generates output as M’, then 2md chunk is given as input to Model M’ instead of Model M. So, M’ model will not train from the beginning instead it trains from M and so on.
Not all Machine Learning Algorithms support Incremental Learning. Few supported algorithms are Multinomial Naive Bayes, Bernoulli Naive Bayes, Perceptron, SGDClassifier, PassiveAggressiveClassifier, SGDRegressor, PassiveAggressiveRegerssor, MiniBatchKMeans, etc.
Coding Part
Let’s see how we can implement it. We have a large dataset of 3GB and contain 30 million or 3 crores records. This is a dummy toy dataset having 4 independent features and 1 target feature, and it is a regression problem.
Please note that this is just dummy data, and we are trying to understand the out-of-core ML concept so we are not focusing on the data cleaning and other tasks.
import pandas as pd
df = pd.read_csv('large_dataset.csv')
df.shape

df.head()
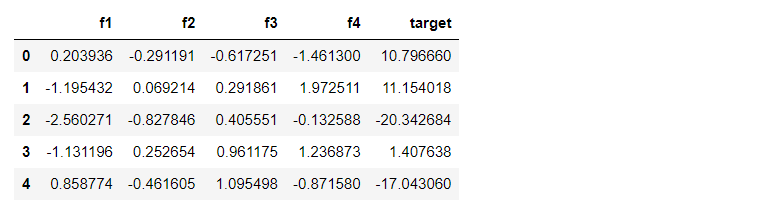
df.describe()
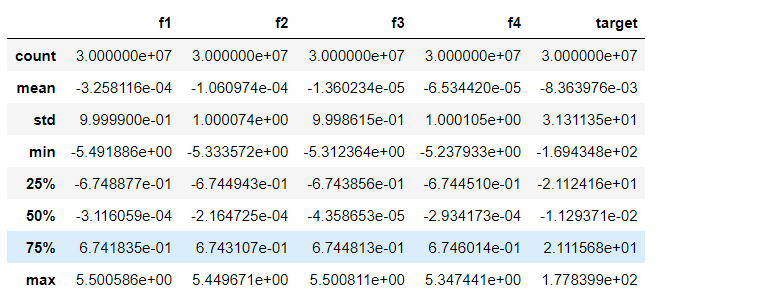
Now, if we try to use Panda’s library, it would take much time to read these records, and the process becomes very slow.
So instead of Pandas, we are going to use Vaex library, and we will train the ML model using this library.
First, we need to install vaex library using.
pip install vaex

We need to convert our dataset from csv to hdf5 file format. hdf5 file format is a hierarchal format where data is stored efficiently, and because of this, searching becomes very easy, which speeds up the operations.
import vaex vaex_df = vaex.from_pandas(df) type(vaex_df)

vaex_df.export_hdf5('large_data.hdf5')
vaex_df = vaex.open('large_data.hdf5')
vaex_df.head()
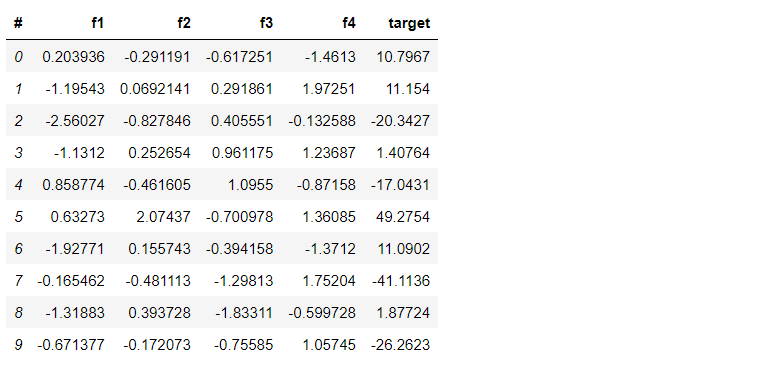
Vaex library is fast because it reads the metadata of hdf5 data when we use vaex_open() and as per requirement, only that data will be fetched/loaded into memory; for example, if we use head() then we know that we need only first 10 rows and vaex will only fetch first 10 rows into memory. At the same time, Pandas will load all the data in memory when we use the read_csv() function.
We are not performing preprocessing. So we will directly perform train_test_split(). We need to shuffle data first before performing a split.
vaex_df = vaex_df.shuffle() df_train, df_test = vaex_df.ml.train_test_split(test_size=0.2) df_train.shape

df_test.shape

The next step is to train the model, and we are using incremental learning to train the model. From the sklearn package of vaex.ml module, we are importing IncrementalPredictor class.
We provide independent features (input columns, input features) and the target variable.
from vaex.ml.sklearn import IncrementalPredictor from sklearn.linear_model import SGDRegressor features = ['f1','f2','f3','f4'] target = 'target' model = SGDRegressor()
We have created the model of SGDRegressor, which we are providing as a parameter to the vaex incremental model.
For the vaex incremental model, we are passing input features, target variable, model (i.e., SGDRegressor), and the important thing which is the batch size which is nothing but our chunks for incremental learning (how many numbers of rows we are passing at a time to model for training. We are passing 5lakh rows at a time in this example.)
vaex_model = IncrementalPredictor(features=features, target=target, model=model, batch_size=500000) vaex_model.fit(df=df_train,progress='widget')

While using the vaex library transform() function performs prediction, the same task in Pandas will be made using predict() function.
Transform() will give us a data frame with one extra ‘predict’ column.
df_test = vaex_model.transform(df_test) df_test.head()
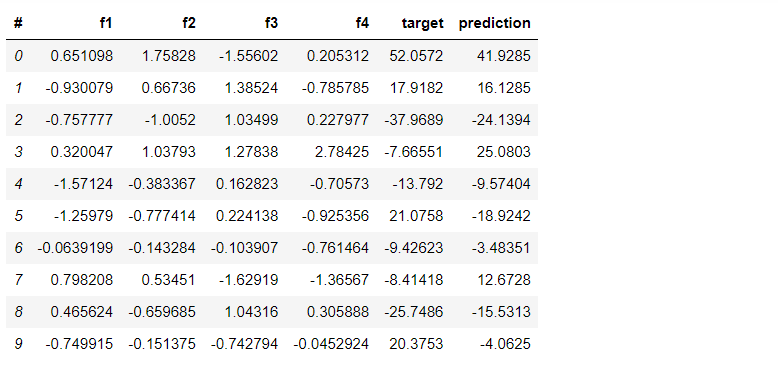
R2 score and MAE can be calculated as:
from sklearn.metrics import r2_score,mean_absolute_error print(r2_score(df_test['target'].values,df_test['prediction'].values)) print(mean_absolute_error(df_test['target'].values,df_test['prediction'].values))

Conclusion
In this article, we begin with a simple problem of how to load a large amount of data for preprocessing if we do not have a powerful enough machine. Then we have seen why we may have a large amount of data.
- Then we learned Subsampling techniques and how we can implement them.
- Next is Cloud Computing, but the major drawback of the Cloud is its cost.
- Finally, we learned the most feasible and important technique, i.e., Out of Core ML, and we have seen its implementation using the vaex library. Three ways to perform out-of-core ML are streaming data, extracting features, and training the model.
- Key takeaways:
- We may get a large amount of data on whether your system can handle it.
- There are various techniques available to handle such situations.
- The most feasible and optimum technique is Out of Core ML and how to implement it using the vaex library.
I hope I tried to explain the concept in simple language for better understanding. I highly appreciate your feedback and comments on this article. The data set used in implementation can be found in the reference links.
References:
1. https://www.youtube.com/watch?v=sRCuvcdvuzk&t=0s
2. https://www.youtube.com/watch?v=9e4nUuq2Hmg
3. https://github.com/campusx-official/vaex-demo
4. https://scikit-learn.org/0.15/modules/scaling_strategies.html
5. https://datagy.io/pandas-sample/
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Shekhar Kausalye
30 Sep, 2022







