
Source – Unsplash
You must often receive birthday notifications from Facebook, like “Amit Pathak and 4 others have their birthday today”. What is so special about this notification? When you look closely at all these birthday notifications, you will find that the name of the person mentioned in the notifications pane (Amit Pathak for the above example) will be a good friend of yours as compared to the other people who have their birthdays today. How does Facebook know that? Let us unearth the relationship between Facebook and Big Data.
Facebook Facts
Before we start, let’s look at some Facebook statistics that will blow your mind.

Source – medium.com
- Since its debut in 2004, Facebook has seen yearly increases in active users and time spent on the site. It remains the most popular social media network, with around 2.45 billion monthly active users.
- The Facebook demographic with the fastest growth rate is users over 65.
- Around 1.79 billion users visit Facebook daily.
- Facebook Stories are used by 300 million people daily, whereas Instagram Stories are used by 500 million users daily and have over 2 million advertisers.
- On Facebook, there are over 10 million groups.
- Every day, over 500 Terabytes of data are produced.
So it’s not a bad idea for us to use the relationship between Facebook and Big Data as a study topic. The only platforms that receive more visitors than Facebook is Google and YouTube.
The Relationship Between Facebook and Big Data
A report from McKinsey & Co. stated that by 2009, companies with more than 1,000 employees already had more than 200 terabytes of data from their customers’ lives. Facebook tracks each and every activity of a user right from the login time, active hours, photos and videos liked, posts, story updates, games you play, ads you click, searches you make, profiles visited, comments, shares, tags, places visited, current location, pages followed, pages liked, friend requests sent, friend requests accepted, a flashback of posts, stories and many more. One can draw a lot of information from the collected, stored, processed, and analyzed data. Facebook can, at times, understand you better than your therapist. With every passing second, the data and the rate at which the data is being generated keep increasing at an unprecedented rate.
The Business Relationship Between Facebook and Big Data
But the question remains: “What does Facebook do with all the data generated ?”

The major source of earnings for Facebook is advertisements. A wider audience watches Facebook ads, which is why the platform is one of the preferred choices of many social media marketers. Facebook understands users’ behaviour based on the data and then classifies them into certain advertisement categories to be shown. This way, the user might be a little less annoyed by seeing the advertisement of their preferred domains. Also, the media marketing people will be glad to know that their advertisement reaches the target audience. A pretty good business relationship, isn’t it? A few years ago, Facebook introduced the profile picture badge. Users start putting badges showing support to a particular side, be their political interests, sports team, or events happening in their country or worldwide. These interests speak a lot about a person and help to match them to a set of advertisement categories.
The Technical Big Data
With all the enormous amounts of data being generated by Facebook daily, most of the data is unstructured in nature. With the help of deep learning methodology and AI, Facebook is bringing a structure for these unstructured data and learning the behaviour of users on its platform while simplifying the relationship between Facebook and big data. For example, identifying the image category the user has uploaded and identifying his or her current mood, likes and dislikes, and interests using the corresponding caption and the mood.
Facebook’s DeepText
Facebook is making use of DeepText to analyze the text on its platform. These texts include status updates, captions, and your searches. The technology focuses on how the words are being used. It plans to use this technology on its messenger platform, where messenger platform can work more like your own personal assistant. For example, you type “I want a ride,” and it might show up a few options in Ola or Uber rides that you can take. But a more concrete approach their DeepText technologies looks at is to provide suggestions for texts like “Get me a ride to my office in the next half an hour.” Facebook is always working to advance the technology behind DeepText, which is currently in the early phases of development.
Facebook’s DeepFace
We have seen how we get suggestions for tagging our friends in our photos. Facebook uses its DeepFace technology to perform facial recognition and identify people in an image. The best thing about this technology is that it has already achieved more than 97 percent accuracy. It performs near equal to the human eye. The major reason for their success is the 9 layers of the neural network they have used to train the model with approximately 120 million human faces. This is by far the largest training data one has used for training a model for a facial recognition system. Every human face has 68 specific facial points that make a pattern. Their deep face tool goes for this 68 landmark testing of facial attributes.
The Architecture of Facebook’s Big Data platform
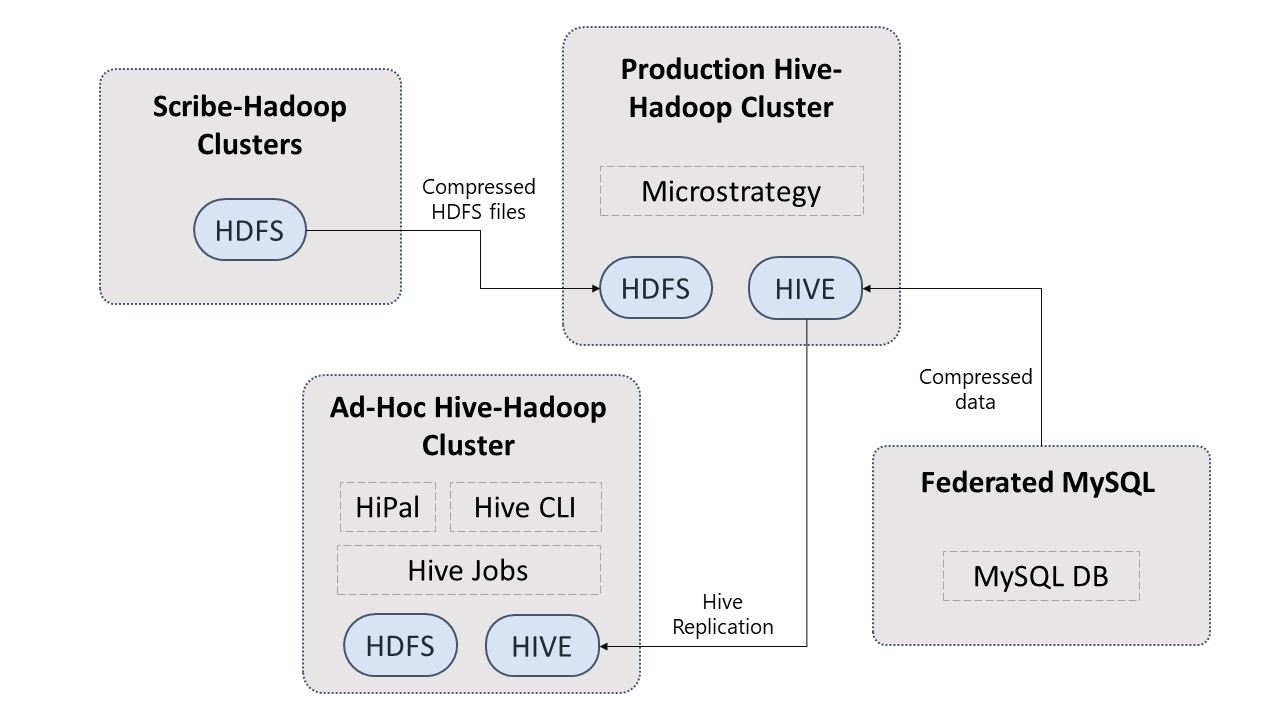
Facebook uses Hadoop HDFS Architecture. Facebook collects data from two sources:
- User data is stored in the federated MySQL layer, and web servers produce event-based log data.
- Web server data is gathered and sent to Scribe servers, which run in Hadoop clusters.
The Hadoop Distributed File System receives log data aggregated by the Scribe servers (HDFS). Periodically, HDFS data is compressed before being sent to production Hive-Hadoop clusters for additional processing. The Production Hive-Hadoop cluster receives the Federated MySQL data, dumps, compresses, and moves it there.
Facebook uses two different clusters for data analysis.
- The Production Hive-Hadoop cluster is used to process tasks with severe deadlines.
- The ad hoc Hive-Hadoop cluster does lower-priority jobs and ad hoc analysis activities. The Ad hoc cluster receives data replication from the Production cluster.
The data analysis outcomes are saved to the Hadoop Hive cluster or, for Facebook users, to the MySQL tier. A graphical user interface (HiPal) or a command-line interface (Hive) is used to specify ad hoc analysis queries (Hive CLI). Facebook uses a Python framework to execute (Database) and schedule periodic batch jobs in the Production cluster.
Conclusion
Now more than ever, organizations are leveraging Big Data analytics to engage with their customers by understanding their behaviour more precisely. Some of the key takeaways from the article are –
- Facebook uses all the available user information with its deep neural network models and finds the target audience for a particular advertisement. This helps to serve the users’ advertisements more insightfully.
- Due to this, Facebook has emerged as one of the toughest competitors for Google Search Engine and Youtube in the digital marketing race.
- With the humungous amount of user data present with Facebook and continuously increasing, there are still a lot of other use cases we might see in the future from Facebook.
However, lately, Facebook has faced much backlash from users over privacy concerns. Facebook is known for tracking different user activities through which it can provide curated advertisements to the target audience. After Apple provided a security update that gives back the control to the user to provide consent to such applications before they can track them, it has been noticed that more than 70 percent of the users have not granted permission to the apps to track their activities. With such security concerns, it will be interesting to see how Facebook can target its users with the right advertisements.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Data Scientist with 6.5+ years of broad-based experience in building data-driven intensive applications with ideal architectures that are scalable. Proficient in predictive modelling, data analytics, and machine learning algorithms, as well as a Python scripting language. Experience with client-facing roles and capable of creating, developing, testing, and deploying highly adaptive applications and services.







Precise, to the point and crisp writing. The best part was that it was so simplified which makes it interesting for a non-tech person to read as well! Looking forward to more such articles!
Glad you liked it. Cheers!