Top Data Lakes Interview Questions
This article was published as a part of the Data Science Blogathon.
Introduction
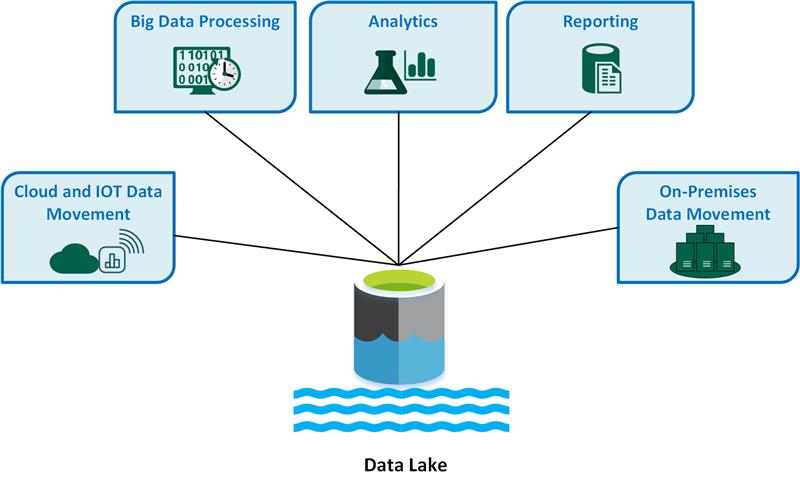
A data lake is a centralized repository for storing, processing, and securing massive amounts of structured, semi-structured, and unstructured data. It can store data in its native format and process any type of data, regardless of size. Data Lakes are an important concept in Data Engineering and Database Management Systems and are an important topic for interview questions. Organizations that want a single location to store all of their data for easy access and analysis frequently use data lakes.
( Source: https://learn.microsoft.com/en-us/azure/architecture/data-guide/scenarios/data-lake)
A data lake is a scalable and secure platform that enables enterprises to ingest any data from any system at any speed—even if the data originates on-premises, in the cloud, or on edge computing systems; store any type or volume of data in full fidelity; process data in real-time or batch mode; and analyze data using SQL, Python, R, etc.
Data Lakes Interview Questions
Now, let us check some Data Lake Interview Questions.
1. Why do we need a Data Lake?
Data is typically saved in raw form without being fine-tuned or structured first. It can then be scrubbed and optimized for the intended purpose: a dashboard for interactive analytics, downstream machine learning, or analytics applications. Finally, the data lake infrastructure provides users and developers self-service access to siloed information. It also allows your data team to collaborate on the same information, which can then be curated and secured for the appropriate team or operation. It is now a critical component for businesses migrating to modern data platforms to scale their data operations and machine learning initiatives. For this reason, Data lakes are important.
2. How are Data Lakes different from Data Warehouses?
While data lakes and warehouses store data, they are optimized for different purposes. Consider them complementary rather than competing tools, as businesses may require both. On the other hand, data warehouses are frequently ideal for the repeatable reporting and analysis common in business practices, such as monthly sales reports, sales tracking by region, or website traffic.
( Source: https://www.educba.com/data-lake-vs-data-warehouse/)
3. What are the advantages of using a Data Lake?
A data lake is a cost-effective and scalable way to store large amounts of data. A data lake can also provide access to data for analytics and decision-making.
4. Why do big tech companies use and invest in Data Lakes?
Data Lake is a big data technology that allows businesses to store large amounts of data centrally. This data is then accessible and analyzed by various departments within the company, allowing for better decision-making and a more comprehensive view of the company’s data.
5. How can Data Lakes be used for Data and Analytics?
Data Lakes are a critical component of any organization’s data strategy. Data lakes make organizational data from various sources available to end-users, such as business analysts, data engineers, data scientists, product managers, executives, etc. In turn, these personas use data insights to improve business performance cost-effectively. Indeed, many types of advanced analytics are currently only possible in data lakes.
6. Where should the metadata of a Data Lake be stored?
The metadata for a data lake should be kept centrally and easily accessible to all users. This ensures that everyone can find and use the metadata when needed.
7. What distinguishes the Data Lakehouse from a Data Lake?
A data lake is a central repository for almost any raw data. Structured, unstructured, and semi-structured data can all be dumped into a data lake quickly before being processed for validation, sorting, summarisation, aggregation, analysis, reporting, or classification.
A data lake house is a more recent data management architecture that combines data lakes’ flexibility, open format, and cost-effectiveness with data warehouses’ accessibility, management, and advanced analytics support.
Lakehouse addresses the fundamental issues that turn data lakes into data swamps. It includes ACID transactions to ensure consistency when multiple parties read or write data simultaneously. It supports DW schema architectures such as star/snowflake schemas and directly offers strong governance and auditing mechanisms on the data lake.
8. Can we deploy and run a data lake on the cloud?
Yes, a data lake can be deployed and run in the cloud. One option is using a cloud-based data management platform, such as Amazon Web Services (AWS) Data Pipeline. This platform can collect, process, and store data from various sources, including on-premises and cloud-based data sources. A cloud-based data warehouse, such as Amazon Redshift, is another option for deploying a data lake in the cloud. This platform can store data from various sources, including on-premises data centers and cloud-based data sources.
9. What are the various types of metadata for a Data Lake?
A data lake can contain three types of metadata: structure metadata, business metadata, and technical metadata. Structure metadata describes the data’s organization, business metadata describes the data’s meaning, and technical metadata describes how the data was generated.
10. Why is data governance important?
The process of ensuring that data is accurate, consistent, and compliant with organizational standards and regulations is known as data governance. It is significant because it ensures that data is high quality and can be used to make sound decisions.
11. What are the challenges of a Data Lake?
Data governance, quality, and security are the primary challenges associated with implementing a data lake solution. Data governance ensures that the data in the data lake is accurate, consistent, and by applicable regulations. Data quality is the process of ensuring that data is clean and usable for its intended purpose. Data security is the protection of data from unauthorized access and misuse.
12. What are a Data Lake’s security and privacy compliance requirements?
There are ways to ensure compliance with security and privacy requirements when using a data lake. One method is to encrypt all data stored in the data lake. Another approach is to use role-based access controls to limit who has access to what data. Finally, activity logs can be created to track who is accessing data and when.
Conclusion
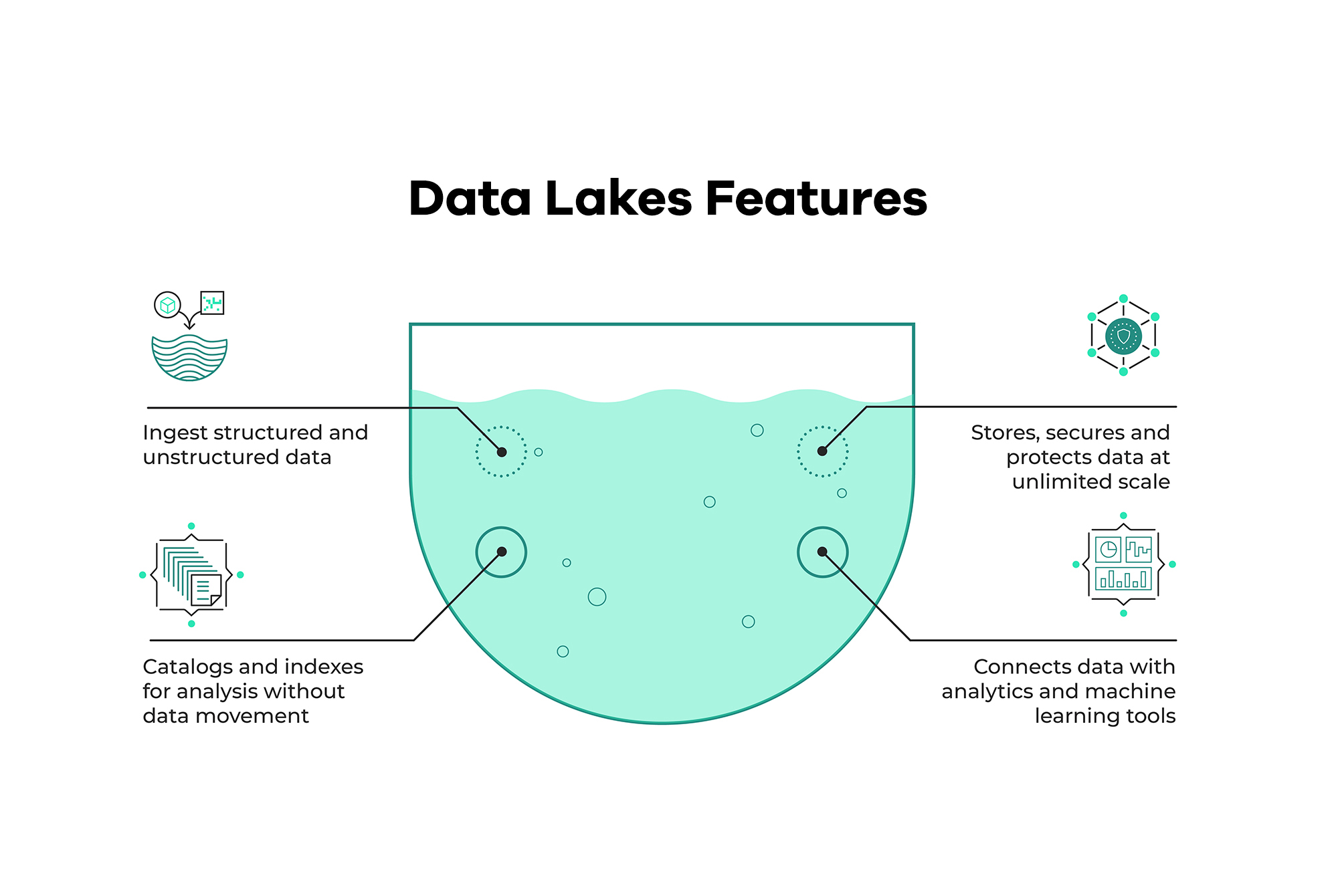
We had a look at some important Data Lake interview questions and answers. These will help you in your Data Engineering interviews. Using data lakes, data scientists can access, prepare, and analyze data more quickly and accurately. This vast pool of data, available in various non-traditional formats, allows analytics experts to access the data for various use cases such as sentiment analysis or fraud detection.
( Source: https://lakefs.io/data-lakes/)
Key Takeaway
- Business intelligence users are excited about data lakes because of their ability to handle velocity and variety. There is now the possibility of combining processed data with subjective data available on the internet.
- Data lakes are useful in advanced predictive analytics applications and regular organisational reporting, especially when multiple data formats are involved.
- The most serious risk of data lakes is a lack of security and access control. Because some data may have privacy and regulatory implications, data can be placed in a lake without any oversight.
Data Lakes are significant in modern Data Architecture, and we looked at some data lake interview questions.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Prateek is a final year engineering student from Institute of Engineering and Management, Kolkata. He likes to code, study about analytics and Data Science and watch Science Fiction movies. His favourite Sci-Fi franchise is Star Wars. He is also an active Kaggler and part of many student communities in College.








