
Introduction
Hyperparameter tuning or optimization is important in any machine learning model training activity. The hyperparameters of a model cannot be determined from the given datasets through the learning process. However, they are very crucial to control the learning process itself. These hyperparameters originate from the mathematical formulation of machine learning models. For example, the weights learned while training a linear regression model are parameters, but the learning rate in gradient descent is a hyperparameter. The performance of a model on a dataset significantly depends on the proper tuning, i.e., finding the best combination of the model hyperparameters.
Different techniques are available for hyperparameter optimization, such as Grid Search, Randomized Search, Bayesian Optimization, etc. Today we will discuss the method and implementation of the Randomized Search. Data scientists set the model hyperparameters to control the implementation aspect of the model. Once data scientists fix the values of a model’s hyperparameters, hyperparameters can be thought of as model settings. These settings need to be tuned for each problem because the best hyperparameters for one dataset will not be the best across all datasets.
What is a Randomized Search?

Source: Pexels
Grid Search and Randomized Search are two widely used techniques in Hyperparameter Tuning. Grid Search exhaustively searches through every combination of the hyperparameter values specified. In contrast to Grid Search, not all given parameter values are tried out in Randomized Search. Rather a fixed number of parameter settings is sampled from the specified distributions. Sampling without replacement is performed if all parameters are presented as a list. Sampling with replacement is used if at least one parameter is given as a distribution. How the sampling will be done in a Randomized Search can be specified beforehand. For each hyperparameter, either a distribution over possible values or a list of discrete values (to be sampled uniformly) can be specified. For the hyperparameters having continuous values, a continuous distribution should be specified to take full advantage of the randomization. The major benefit of this search is a decreased processing time.
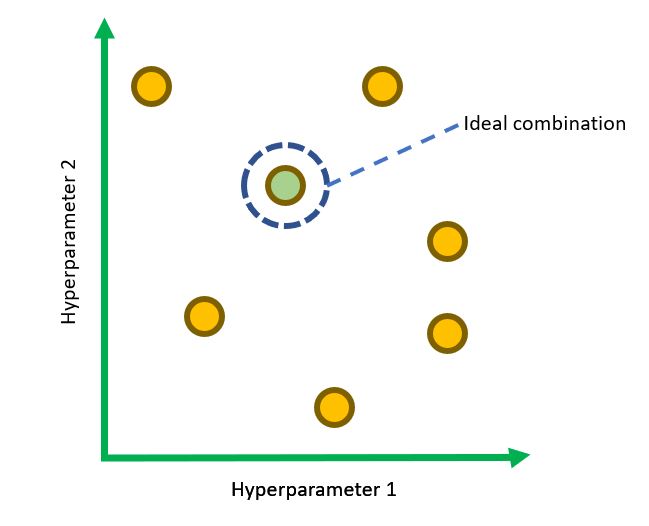
Example of Randomized Search space for tuning two hyperparameters
Python Implementation
Let’s see the Python-based implementation of Randomized Search. The scikit-learn module comes with some popular reference datasets, including the methods to load and fetch them easily. We will use the breast cancer Wisconsin dataset for binary classification. The breast cancer dataset is a classic and straightforward binary classification dataset.
The scikit-learn’s implementation of Randomized Search is called the RandomizedSearchCV function. Let’s see the important parameters of this function:
- estimator: An object of the scikit-learn model type.
- param_distributions: Dictionary with parameters names as keys and distributions or lists of parameters to search.
- scoring: a scoring strategy to evaluate the performance of the cross-validated model on the test set.
- n_iter: It specifies the number of combinations to try randomly. Selecting too low of a number will decrease our chance of finding the best combination.
Selecting too large of a number will increase the processing time. So, it trades off run time vs quality of the solution. - cv: In Randomized Search CV, “CV” stands for cross-validation, which is also performed during the optimization process. Cross-validation
is a resampling method used to test the model’s generalisation ability using out-of-the-sample data chunks? We can determine the cross-validation
splitting strategy by the “cv” value in this method.
From sklearn.datasets, we will use the load_breast_cancer method to load the breast cancer Wisconsin dataset. If return_X_y is made true, then it returns (data, target).
X, y = load_breast_cancer(return_X_y=True) print(X.shape)
Let’s use train_test_split to split the dataset into train and test sets:
X_train, X_test, y_train, y_test = train_test_split(X, y)
We will use Standard Scalar for preprocessing the data. You can see that training data is fit transformed and test data is only transformed.
ss = StandardScaler() X_train_ss = ss.fit_transform(X_train) X_test_ss = ss.transform(X_test)
First, we will use Random Forest Classifier without Randomized Search and with default values of hyperparameters.
clf = RandomForestClassifier() clf.fit(X_train_ss, y_train) y_pred = clf.predict(X_test_ss)
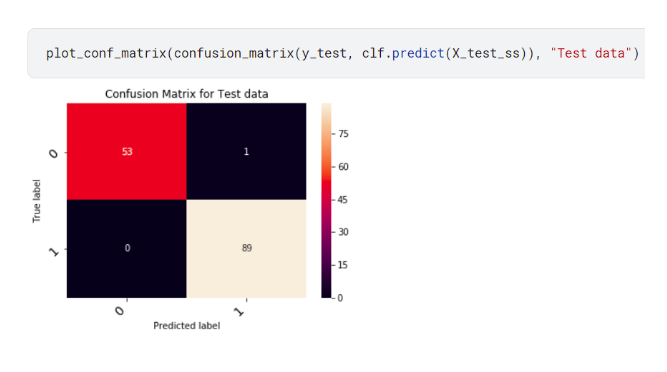
The accuracy score can be calculated on test data and a confusion matrix can be developed:
confusion_matrix(y_test, y_pred), "Test data") acc_rf = accuracy_score(y_test, y_pred) print(acc_rf)
We will use Random Forest Classifier with a Randomized Search to find out the best possible values of the hyperparameters. We are tuning five hyperparameters of the Random Forest classifier here, such as max_depth, max_features, min_samples_split, bootstrap, and criterion. Randomized Search will search through the given hyperparameters distribution to find the best values. We will also use 3 fold cross-validation scheme (cv = 3).
Once the training data is fit into the model, the best parameters from the Randomized Search can be extracted from the final result.
param_dist = {"max_depth": [3, 5],
"max_features": sp_randint(1, 11),
"min_samples_split": sp_randint(2, 11),
"bootstrap": [True, False],
"criterion": ["gini", "entropy"]}
# build a classifier clf = RandomForestClassifier(n_estimators=50)
# Randomized search
random_search = RandomizedSearchCV(clf, param_distributions=param_dist,
n_iter=20, cv=5, iid=False)
random_search.fit(X_train_ss, y_train)
print(random_search.best_params_)
The complete Python code can be found in this Kaggle Kernel. If you like the kernel and find the code useful, please comment and upvote it.
Conclusion
While Grid Search checks for every combination of the hyperparameters, it underperforms when we need to handle big datasets. Trying all the combinations of hyperparameters on big datasets is a tedious job. If there are m number of hyperparameters for a model and each hyperparameter if we test n number of values, then Grid Search checks for mxn combination. In Randomized Search, it is assumed that not all hyperparameters are equally important. Every iteration samples a random combination of the hyperparameters, and the chances of finding a good combination are higher. The key takeaways from this article are:
- In machine learning, hyperparameter optimization is crucial so that the model can be optimally trained on the given dataset. These are not learned through the learning process.
- Randomized Search offers lesser processing time than Grid Search.
- In Randomized Search, a fixed number of parameter settings is sampled from the specified distributions.
- Python scikit-learn library implements Randomized Search in its RandomizedSearchCV function. This function needs to be used along with its parameters, such as estimator, param_distributions, scoring, n_iter, cv, etc.
Randomized Search is faster than Grid Search. However, there is a trade-off between decreased processing time and finding the optimal combinations. Randomized Search method may not guarantee to find the optimal combination of hyperparameters.
What is your favorite hyperparameter tuning method, and why? Let me know in the comment section.
References
- https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.RandomizedSearchCV.html
- https://en.wikipedia.org/wiki/Hyperparameter_optimization
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion.







