This article was published as a part of the Data Science Blogathon.
 Source: https://cloudnesil.com/2019/08/20/aws-glue/
Source: https://cloudnesil.com/2019/08/20/aws-glue/Introduction
If you are familiar with databases, or data warehouses, you have probably heard the term “ETL.” As the amount of data at organizations grow, making use of that data in analytics to derive business insights grows as well. For the efficient management of these data, ETL (Extract, Transform, and Load) process is necessary.
AWS helps you perform ETL tasks, especially complex ones, with AWS Glue.
AWS Glue is simply a serverless ETL tool that helps you with the analysis and lets you enjoy the results in minutes. Moreover, you do not have to manage any cloud infrastructure, as it is an automatically managed service that’s fully maintained by AWS.
Now, why is it the choice of Data scientists and analysts?
As a cloud-based tool, it reduces costs and decreases the time spent creating ETL jobs. It also removes all the complex tasks associated with ETL data processing as it associates with various platforms for quick data analysis.
This article covers an overview of AWS Glue, why it is an effective tool in ETL data processing, Glue’s architecture and components, it’s working, and some of its use cases.
What Is AWS Glue?
AWS Glue is a serverless data integration service developed to extract, transform, and load data called the ETL process. Because it is a serverless service, users don’t have to manage infrastructure, configure, scale, or provision resources. Glue provides easy-to-use tools to create and follow up job tasks based on schedule, event triggers, or on-demand. AWS Glue provides visual and code-based interfaces to make data integration more manageable. With AWS Glue Studio, users can visually create, run, and monitor ETL workflows with just a few clicks.
Why Consider AWS Glue for ETL Data Processing?
- Automatic ETL Code Generation: By specifying the source and destination of data, AWS Glue can generate the code in Python or Scala for the entire ETL pipeline. This feature streamlines the data integration operations and allows users to parallelize heavy workloads.
- Only Pay for the Resources You Use: Glue is cost-effective, and users only have to pay for the resources they use. If the ETL jobs need more computing power from time to time but consume fewer resources, users don’t have to pay for the peak time resources outside of this time.
- Developer Endpoints: It is helpful for users who prefer to manually create and test their own custom ETL scripts. It can debug, edit and test autogenerated code. Using Developer Endpoints, custom readers, writers, or transformations can be created, which can further be imported as custom libraries into Glue ETL jobs.
- Automatic Schema Discover: Glue uses crawlers that parse the data and its sources or targets. Crawlers obtain schema-related information and store it in the data catalog, which helps to manage jobs. Hence, users don’t need to design the schema for their data individually to cater to the complex features of ETL processes.
AWS Glue’s Architecture
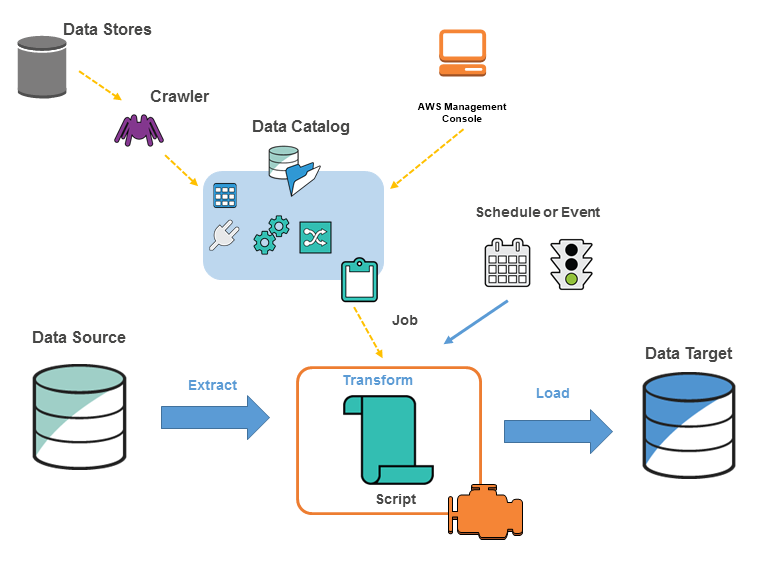
Source: https://docs.aws.amazon.com/glue/latest/dg/components-key-concepts.html
AWS Glue comprises many individual components, such as the Data Catalog, Job scheduling system, Crawlers, ETL Engine, Datastore, etc. Glue depends on the interaction between these components to develop and maintain ETL operations. The different components can be orchestrated through Glue workflows to get a functional data processing pipeline. Workflows define and visualize the order in which crawlers and jobs are supposed to be started to facilitate the data transformation.
The components of the Glue architecture are:
- Data Catalog: It holds the structure of the data and stores metadata needed for the system to work efficiently. It contains information in metadata tables, where each table points to a single data store. Data catalog stores information related to data, queries, schemas, data sources and destinations, partitions, etc.
- Job Scheduling System: It is responsible for starting jobs based on various events. The System deals with automating and chaining ETL pipelines by creating an execution schedule or event-based jobs triggering.
- Crawlers: It retrieves data from the source and build metadata tables in the Data Catalog after determining the schema. Crawlers explore several data repositories in a single encounter and decide the ideal schema for those data.
- ETL Engine: It handles ETL code generation in Python or Scala and allows code customization. Users can visually compose data transformation workflows and run them on Glue’s Apache Spark-based serverless ETL engine.
- Data Store: It denotes a data repository that keeps users’ data for a long period. Some of the data stores include AWS S3 buckets and other relational databases.
How Does AWS Glue Work?
First, the user has to determine the data source, which is used as input to a process or transformation. Data crawlers analyze and extract necessary information about data sources and targets. It classifies data to determine the format and associated properties of the raw data and groups data into tables or partitions. This data is sent and stored as metadata table definitions to the Glue Data Catalog. After Glue Data Catalog is completely categorized, the data will be ETL-ready, searchable, and queryable. Users can create a script, schedule ETL jobs, or set the trigger events for the jobs to start. While executing the task, the script will extract data from the data source, transform and load it to the data target. Hence the ETL (Extract, Transform, Load) process will be completed.
Data Sources Supported by AWS Glue

Use Cases
- Build Event-driven ETL Pipelines: AWS Glue is helpful while building event-driven ETL workflows. It allows developers to start AWS Glue workflows based on events delivered by Amazon EventBridge. This feature enables users to trigger a data integration workflow from any events from AWS services, SaaS providers, or custom applications. Users can start an ETL job by invoking AWS Glue ETL jobs through the AWS Lambda function whenever new data is available in Amazon S3.
- Non-native JDBC Data Sources: AWS Glue has native connectors to data stores using JDBC drivers, and you can use this in AWS or anywhere else on the cloud as long as there is IP connectivity. Using the JDBC protocol, Glue natively supports data stores like Amazon RDS and its variants, Amazon Redshift, etc. For data sources that Glue doesn’t natively support, like SAP Sybase, IBM DB2, Pivotal Greenplum, or other RDBMS, users can import custom database connectors into AWS Glue jobs from AWS S3.
- Data Transformation With Snowflake: AWS Glue has a fully managed environment that integrates easily with Snowflake’s data warehouse. With Snowflake and AWS Glue, users can benefit from optimized ETL processing that is easy to use and maintain. Together, these services manage data ingestion and transformation pipelines with more flexibility.
- Querying With Athena: When using Athena with the AWS Glue Data Catalog, users can use AWS Glue to create databases and tables (schema) to be queried in Athena. Otherwise, Athena can be used for schema creation which can then be used in Glue and related services. AWS Glue jobs help to transform data to a format that optimizes query performance in Athena. It is possible to push data outside of AWS to the Amazon S3 bucket in a suboptimal format for querying in Athena. Users can configure AWS Glue ETL jobs and run them automatically based on triggers.
Conclusion
In this article, we have explored AWS Glue, a cost-effective service that provides easy-to-use tools to sort, validate, categorize, clean, and move data stored in warehouses and data lakes. It works with ETL pipelines and is compatible with other AWS services. Moreover, it provides centralized storage and operates with semi-structured data.
Key Takeaways:
- AWS Glue is a serverless data integration service developed to extract, transform, and load data called ETL process.
- By specifying the source and destination of data, Glue can generate the code in Python or Scala for the entire ETL pipeline.
- AWS Glue architecture comprises Data Catalog, Job scheduling system, Crawlers, ETL Engine, Datastore, and so on.
- A data catalog holds the structure of the data and stores metadata needed for the system to work efficiently.
- Crawlers retrieve data from the source and build metadata tables in the Data Catalog after determining the schema.
- AWS Glue has a fully managed environment that integrates easily with Snowflake’s data warehouse.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.







