Nowadays, organizations are looking for multiple solutions to deal with big data and related challenges. One such solution is Snowflake, an ultimate cloud-based data warehouse platform gaining attention for its innovative features like data sharing, data cleansing, separation of computing and storage, support for multi-cloud infrastructure environments, etc. If you’re preparing for the Snowflake interview, you landed at the right blog. Here we discuss the most frequently asked Snowflake interview questions into three levels: Beginner, Intermediate, and Expert.
Learning Objectives
Here is what we’ll learn by reading this guide thoroughly:
- A common understanding of what a Snowflake is and its role in the technical era.
- Knowledge of the unique architecture of Snowflake, along with reasons behind its popularity.
- An understanding of the data storage process in Snowflake.
- An understanding of Snowpipe and Snowflake Schema.
- Insights into concepts like Time Travel or Data Retention Period in Snowflake.
Overall, by reading this guide, we will gain a comprehensive understanding of Snowflake to store data and interact with that. We will be equipped with the knowledge and ability to use this technique effectively.
This article was published as a part of the Data Science Blogathon.
Table of contents
- Facts Around Snowflake
- Snowflake Interview Questions
- Q1. What do you mean by Snowflake Cloud Data Warehouse?
- Q2. Explain the Unique Architecture of Snowflake.
- Q3. Is Snowflake an ETL Tool? If Yes, then Name Some ETL Tools which are Compatible With Snowflake.
- Q4. Explain What Type of Database Snowflake is.
- Q5. Explain the Primary Reasons Behind the Success of Snowflake.
- Q6. Explain the Data Storage Process in Snowflake.
- Q7. Explain the Possible Ways to Access the Snowflake Cloud Data Warehouse.
- Q8. What Do you Mean By the Term Snowpipe in Snowflake?
- Q9. Describe Snowflake Schema And State The Difference Between Star Schema And Snowflake Schema.
- Q10. Explain the Concept of Snowflake Time Travel and the Data Retention Period.
- Q11. Explain the Concept of “Stages” in Snowflake.
- Q12. Is there any Possible Way to Get Data After the Retention Period in Snowflake?
- Q13. Explain the Data Security Features in Snowflake.
- Q14. What is the best way to remove a string that is an anagram of an earlier string from an array?
- Conclusion
Facts Around Snowflake
Before jumping to the Interview Questions for beginners, let’s see some interesting facts about the Snowflake industry:
- Around 6000 global customers are served by Snowflake, of which 488 belong to Global 2000 and 241 belong to Fortune 500.
- Multiple top MNCs are allied with Snowflake, for example, Amazon Web Services, Informatica, Qlik, Talend, Cognizant, etc.
- Snowflake is gaining market popularity by providing cloud support, Near-Zero management, and a broad ecosystem to integrate, irrespective of the programming languages and frameworks.
These facts are enough to depict that Snowflake is attaining momentum as the best cloud data warehouse solution. So, let’s rush with the detailed interview questions!
Snowflake Interview Questions
Q1. What do you mean by Snowflake Cloud Data Warehouse?
Snowflake is a cloud-based data warehouse solution implemented as a SaaS(Software as a service, a cloud-based technology providing software to users). It is built on the top of Google Cloud infrastructures, AWS (Amazon Web Services), and Microsoft Azure to provide industries with flexible, scalable, highly concurrent, and profitable storage solutions while hosting BI (Business Intelligence) solutions.
Snowflake is far from pre-existing Big Data technologies like Hadoop; it works on a new SQL database query engine with a unique cloud-based architecture. Initially, this cloud-based data warehouse solution was on Amazon Web Service to load and analyze huge volumes of data. Hence, Snowflake can offer all the features of an industry analytics database along with many remarkable features, for example, the ability of Snowflake to spin up any number of virtual warehouses, which signifies that without any risk of contention, a user can operate an unlimited number of independent workloads against the same data.

Snowflake revolutionized the data warehousing industry by providing a centralized system to consolidate all data. It is a centralized platform for securely sharing and consuming real-time and shared data. It comprises a unique architecture that separates calculation and storage, which is not allowed by traditional methods.
Q2. Explain the Unique Architecture of Snowflake.
Snowflake is truly a SaaS offering, and its architecture is a hybrid of shared-disk and shared-nothing database architecture in order to mix the best features of both techniques. The shared disk is a common storage device shared by all computing nodes and the shared-nothing is storage space where each computing node has its private memory. Now, like a shared-disk architecture, Snowflake utilizes a centralized data repository for persistent data. Like the shared-nothing architectures, it uses massively parallel computing (MPP) clusters for query processing, where each node holds the pieces of the complete dataset locally. To work with Snowflake, we didn’t require any specific software, hardware, ongoing maintenance, tuning, etc.
The architecture of Snowflake is built with these three key layers:
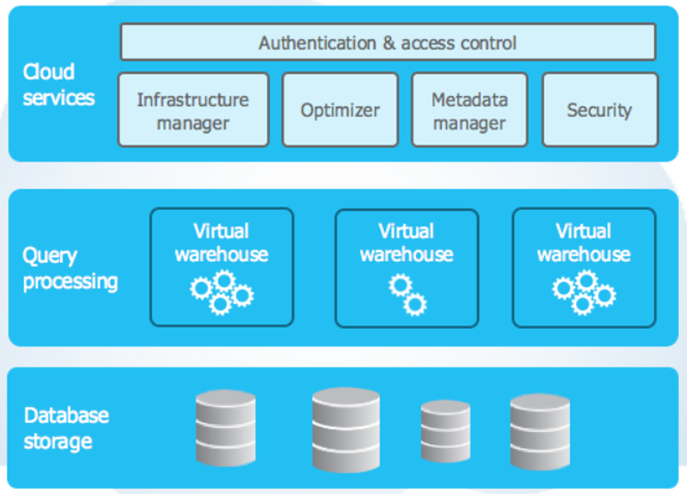
- Data Storage Layer: As soon as the data is loaded into Snowflake, the data storage layer identifies that data into a specific format like compressed, columnar, or optimized format. It also stores the optimized data in cloud storage.
- Query Processing Layer: Virtual warehouses are used in this query processing layer to execute the queries. These warehouses are independent Massively Parallel Processing compute clusters composed of various compute nodes that Snowflake assigns from cloud providers. The performance of virtual warehouses is independent of each other because they do not share their computing resources with each other.
- Cloud Services Layer: This layer acts as a coordinator and manages all activities across the Snowflake. It offers various administrative services like authentication, access control, metadata management, infrastructure management, query parsing, and query optimization.
Q3. Is Snowflake an ETL Tool? If Yes, then Name Some ETL Tools which are Compatible With Snowflake.
Snowflake is an ETL(Extract, Transform, and Load) tool that helps data engineers focus more on essential data strategy and pipeline improvement initiatives. It performs the following steps to prove it’s an ETL tool:
Step 1: Extract
Initially, it extracts the data from the source and creates the files in various formats like JSON, CSV, XML, etc.
Step 2: Transform
It loads data into a stage that can be internal (managed by Snowflake) or external (Microsoft Azure blob, Amazon S3 bucket, Google Cloud).
Step 3: Load
With the help of COPY INTO command, data gets copied into the Snowflake database tables. Some best ETL tools compatible with Snowflake are:
- Matillion
- Blendo
- Hevo Data
- StreamSets
- Etleap
- Apache Airflow, etc.
Q4. Explain What Type of Database Snowflake is.
Snowflake is a columnar-stored relational database built entirely on the SQL(Structured Query Language) database. It stores data in a columnar format and is compatible with tools like Excel and Tableau. As expected in a SQL database, Snowflake contains its query tool, provides role-based security, supports multi-statement transactions, etc.
Snowflake offers the most standardized version of SQL for powerful relational database querying, i.e., ANSI.
Q5. Explain the Primary Reasons Behind the Success of Snowflake.
When it comes to the success of Snowflake technology, various aspects help in gaining a market presence; some include:
- It assists various technological areas such as BI(business intelligence), data integration, advanced data analytics, security, and data governance.
- Snowflake provides simplicity to data processing and offers extendable computing power.
- Snowflakes support advanced design architectures and offer cloud infrastructure that is ideal for dynamic and instant usage developments.
- There are various predetermined features supported by Snowflake like data cloning, data sharing, separation of computing and storage, and directly scalable computing.
- Snowflake is suitable for various applications such as raw marts, data lakes with data warehouses, ODS with staged data, and data marts with acceptable and processed data.
Q6. Explain the Data Storage Process in Snowflake.
As soon as the data is loaded into Snowflake, it automatically identifies the format of data(i.e., compressed, optimized, columnar format) and stores the data in various micro partitions internally compressed. The optimized data is stored in a columnar format in the cloud storage, and Snowflake manages all aspects of storing this data, like the file’s structure, size, statistics, compression, and metadata.
Instead of the traditional row format, the snowflake stores the data in columnar format, improving the database performance and allowing us to run the analytical queries. Columnar databases are more accurate in terms of business analytics and Intelligence, and they offer faster column-level operations with a need for very few resources. Customers or users can’t directly access the data objects stored by Snowflake. They have to run SQL query operations on Snowflake to view the data.
Q7. Explain the Possible Ways to Access the Snowflake Cloud Data Warehouse.
To access the Snowflake data warehouse, we can choose any of the below possible ways:
- Snowflake has ODBC(Open database connectivity, a driver for connecting to Snowflake) and JDBC(Java database connectivity, a driver that enables a Java application to interact with a database) drivers, which allow many applications (like Tableau) to connect to it.
- A web-based user interface can be used to access all aspects of Snowflake management that can be accomplished with SQL and the command line, for example: creating and managing users and various account-level objects.
- We can use SnowSQL, a python-based command-line client that can access all parts of Snowflake management by connecting Snowflake to Windows, Linux, and macOS.
- Native connectors like Python or Spark libraries for developing programs and applications that connect to Snowflake and perform standard operations.
- To link the applications, we can also use third-party connectors like ETL tools (e.g., Informatica) and BI tools (e.g., ThoughtSpot) to Snowflake.
Q8. What Do you Mean By the Term Snowpipe in Snowflake?
Snowpipe is a continuous data ingestion service offered by Snowflake to load data in minutes as soon as files are added to a stage and submitted for ingestion. Using the serverless compute approach of Snowpipe, Snowflake maintains load capacity and assures appropriate compute resources to fulfill customer demand. In simple terms, Snowpipe offers a “pipeline” to load data from new files in micro-batches (organizing data into small groups) as soon as it becomes available(in very less time), which helps in analyzing the data efficiently. To ensure that only new data is processed, Snowpipe uses a combination of filenames and file checksums.

Basically, to load the data, we have to run the COPY command defined in a connected pipe. Instead of manually running COPY statements on a schedule to load large batches, we use Snowpipe, which is a named, first-class Snowflake object containing a COPY command. In the COPY command, we have to specify the location of the data files (i.e., a stage) and the target table.
Benefits of Snowpipe:
- Snowpipe offers real-time insights by eliminating roadblocks.
- Snowpipe is a cost-effective and user-friendly technique that does not need specific management and offers high flexibility and resilience.
Q9. Describe Snowflake Schema And State The Difference Between Star Schema And Snowflake Schema.
A Snowflake schema is nothing but a logical grouping of database objects like tables, database views, etc., that describes how data is organized in Snowflake. It is a dimension-added extension of a Star Schema, consisting of a fact table centralized and linked to multiple dimensions, which links to other dimension tables via many-to-one relationships. Snowflake schemas are powerful due to their structured data offerings and small disk space usage. Snowflake offers a complete set of DDL (Data Definition Language) commands to create and maintain the schemas. People consider Snowflake and Star Schemas identical, but the difference exists in dimensions. Let’s see the differences!

- Star Schema: As the name suggests, star schema has the appearance of a star which is made up of one fact table and several associated dimension tables. Star schema does not employ normalization, i.e., the same values are repeated within a table, leading to low query complexity and high data redundancy.
- Snowflake Schema: Snowflake schema is also made up of one fact table associated with many dimension tables, which is related to other dimension tables, but the fact table is centralized here. A snowflake schema is a bottom-up model that provides fully normalized data structures, leading to a higher query complexity than a star schema but having a minimal data redundancy level.
Q10. Explain the Concept of Snowflake Time Travel and the Data Retention Period.
Time travel is a fantastic feature offered by Snowflake to access the historical data available in the data warehouse of Snowflake at any moment in the specified period. To understand it in a better way, suppose you have a critical database of a hospital, and you accidentally delete a table named Patient, now this loss of information can affect the lives of many people, but using time travel, it is possible to go back ten minutes in time to access the data you lost. You can easily access the data that has been altered or deleted via Snowflake Time Travel within a specific period. Through this tool, we can perform the following tasks:
- For analyzing/examining the data manipulations and utilization over a defined period.
- Restoring data-associated objects like tables, schemas, and databases that may have been lost unintentionally.
- It can back up and duplicate data (clones) from essential points in history.

Data retention period: It is an important aspect of Snowflake Time Travel that sets a time limit beyond which you can’t perform the above actions, and the data moves into Snowflake Fail-safe. As soon as the data in a table is modified(i.e., deletion or altering of an object occurs), the Snowflake saves the previous data state. Now, the data retention period specifies the number of days that this past data is kept, and, as an output, Time Travel operations (SELECT, CREATE, CLONE, UNDROP, etc.) can be executed on it. By default, the retention period is enabled for all Snowflake accounts, and its standard value is 24 hours.
Q11. Explain the Concept of “Stages” in Snowflake.
Stages are nothing but the data storage locations in Snowflake. If the data to be imported into Snowflake is stored within the Snowflake only, then it is referred to as Internal stages(Consisting of the table stage, user stage, and the internally named stage). On the other hand, if data gets imported into different cloud areas, like AWS S3, Azure, or GCP, then it is considered the External stage.
Q12. Is there any Possible Way to Get Data After the Retention Period in Snowflake?
Yes, even after the expiration of the retention period, we can access the data in the Snowflake with the help of the Fail-Safe concept. The fail-safe feature of Snowflake enables us to retrieve the historical data to a default period of 7 days, which begins after the time travel retention period ends. Data recovery option through fail-safe is enabled only after all other recovery options have been exhausted and can be performed under best-effort conditions. Generally, Snowflake uses this feature to recover data that has been lost due to extreme operational failures. To complete data recovery, Fail-safe might take several hours to several days.

Q13. Explain the Data Security Features in Snowflake.
To ensure data security, Snowflake facilitates us with a default end-to-end encryption (E2EE) at no additional cost and encrypts all customer data. Snowflake offers pure transparency of data security with customers and facilitates them with best-in-class key management. Its offerings are:
- With the usage of Snowflake-managed keys, all data of customers get encrypted.
- Transport Layer Security(TLS) protects communication and data transfer between clients and the server.
- Depending upon the cloud region, customers can choose the location where their data is stored.
Q14. What is the best way to remove a string that is an anagram of an earlier string from an array?
To remove a string from an array that is an anagram of an earlier string, you can follow these steps in a programming language like Python:
- Initialize an empty dictionary to store the frequency of characters in the earlier strings.
- Iterate through the array of strings.
- For each string, sort its characters and check if the sorted string exists as a key in the dictionary.
- If it does, then it is an anagram of an earlier string. Skip it and continue to the next string.
- If it is not an anagram, add its sorted version as a key to the dictionary with a value of True (or any value).
- Append the current string to a new array (or list) that will store the strings that are not anagrams of earlier strings.
- Once the iteration is complete, the new array will contain only the strings that are not anagrams of any earlier strings.
Code
def remove_anagram_strings(strings):
earlier_strings_dict = {}
non_anagram_strings = []
for string in strings:
sorted_string = ''.join(sorted(string))
if sorted_string not in earlier_strings_dict:
earlier_strings_dict[sorted_string] = True
non_anagram_strings.append(string)
return non_anagram_strings
# Example usage:
array_of_strings = ["listen", "silent", "hello", "hit", "litens"]
result = remove_anagram_strings(array_of_strings)
print(result) # Output: ['hello', 'hit', 'litens']Q15. What do we need to do to create temporary tables?
To create temporary tables in Snowflake, you need to follow these steps:
- Database and Schema Selection: First, ensure you are connected to the appropriate database and schema where you want to create the temporary table.
- Temporary Keyword: Use the “TEMPORARY” keyword before the “CREATE TABLE” statement to specify that the table should be temporary.
- Table Definition: Define the table’s structure, including column names, data types, and any constraints, just like you would for a regular table.
- Create the Table: Execute the “CREATE TABLE” statement with the temporary keyword and table definition to create the temporary table.
Code
-- Connect to the desired database and schema
USE DATABASE my_database;
USE SCHEMA my_schema;
-- Create a temporary table
CREATE TEMPORARY TABLE temp_table (
id INT,
name VARCHAR,
age INT
);Conclusion
Mastering Snowflake interview questions is crucial to building a successful career in data analytics and warehousing. Aspiring data professionals can gain a competitive advantage by enrolling in the Analytics Vidhya BlackBelt program. This comprehensive program equips learners with the expertise to confidently tackle Snowflake interviews, providing in-depth knowledge and hands-on experience with Snowflake’s powerful capabilities. Don’t miss this opportunity to excel in your data career journey. Join the Analytics Vidhya BlackBelt program today and unlock exciting opportunities in data analytics and Snowflake expertise.
I am a tech enthusiast, a student, and a learner. I am a critical reader and a lover of words who finds writing blogs interesting. I possess the capability to research and learn new technologies quickly.







thanks for valuable info gcp training in hyderabad