How to Implement a Data Pipeline Using Amazon Web Services?
Introduction
The demand for data to feed machine learning models, data science research, and time-sensitive insights is higher than ever thus, processing the data becomes complex. To make these processes efficient, data pipelines are necessary. Data engineers specialize in building and maintaining these data pipelines that underpin the analytics ecosystem. In this blog, we will discuss the end-to-end guide on implementing a data pipelines using Amazon Web Services.
Learning Objectives
- Understanding the importance of Cloud computing in this era of data.
- Identifying what data pipelines are and their need in solving different problems.
- Developing knowledge about Amazon Web Services and their applications in different industries.
- To Construct an overview for implementing the data pipelines using AWS.
- Practically implementing end-to-end data pipelines using AWS.
This article was published as a part of the Data Science Blogathon.
Table of Contents
- What is Cloud Computing and its benefits?
- What are Amazon Web services?
- What are Data pipelines and the need for them?
- What is AWS Data Pipeline?
- Processes involved in implementing the AWS data pipeline?
- Practical Implementation of AWS Data Pipeline.
6.1 DynamoDB
6.2 Amazon Simple Storage Service (S3)
6.3 AWS Data Pipeline Service
6.4 Parameters
6.5 Schedule
6.6 IAM Roles
6.7 AWS Data Pipeline in Architect View - Conclusion
What is Cloud Computing and its Benefits?
Cloud Computing facilitates the delivery of on-demand resources through web-based tools and applications. Cloud computing can reduce the expensive infrastructure, thus giving businesses the leverage to pay for only the resources used.

Cloud computing allows the scalability of resources up and down based on business needs. Cloud Computing protects businesses from data loss and provides robust backup and recovery. Many cloud providers provide advanced security to help businesses to protect sensitive data and data breaches.
What are Amazon Web Services?
Amazon Web Services is a cloud computing platform that provides over 200 computing services that make up the cloud computing platform. Amazon Web Services offers different categories of services for storage, databases, analytics, deployment, and more.
The Major application of AWS includes the following:
- Storage and Backup:
- Amazon Simple Storage Service
- DynamoDB
- Amazon RDS
- Big Data Management and Analytics:
- Amazon EMR processes large amounts of data.
- Amazon Kinesis to analyze the data.
- AWS Glue to perform ETL ( Extract, Transform, Load ).
- Amazon Athena to query data, Amazon quick sight to visualize data.
- Artificial Intelligence
- Internet of Things
What are Data Pipelines and the Need for Them?
Data Pipelines includes repetitive steps to automate data movement from its source to its final destination, processing the information along the way. These pipelines are operated in data warehousing, analytics, and machine learning.
Due to the progress in technologies, the amount of raw data being generated is massive thus, processing, storing, and migrating data becomes very complex; data pipelines are required to make these processes efficient so that businesses can analyze these data to derive business value and improve their business.
What is AWS Data Pipeline?
AWS Data Pipelines is a cloud-based service that facilitates users to process, transfer, and access data between different AWS services, DynamoDB, and EMR, at designated time intervals. Automating these processes through AWS Data Pipeline facilitates easy and swift deployment of changes.
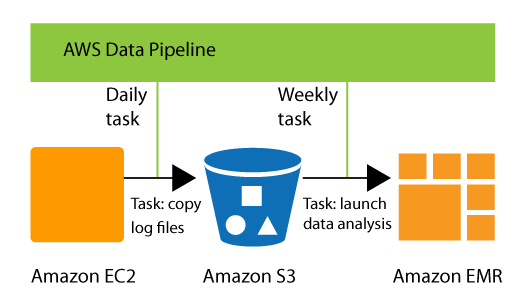
For example, We collect data from different data sources like DynamoDB and Amazon S3, then perform EMR analysis to get daily EMR results. AWS pipeline can vary depending on the specific needs and requirements of an application.
Processes Involved in Implementing the AWS Data Pipeline
- Identify and gather the source of data that will be used in the data pipeline.
- Define a Pipeline outlining the source and destination of the data, transformation, and the actions to be performed like data extraction and data movement.
- Create the Pipeline: Use the AWS Management Console, AWS CLI, or AWS SDKs to create the pipeline.
- Activate the Pipeline: use the AWS Data Pipeline Dashboard to keep track of its status, and fix any problems that may arise.
- Observe the Pipeline: Observe the pipeline check for errors and fix the issues, and track the progress of data processing.
- Optimize the Pipeline: Optimize the pipeline by testing and refining the processes and updating the pipeline as needed.
Practical Implementation of AWS Data Pipeline
DynamoDB
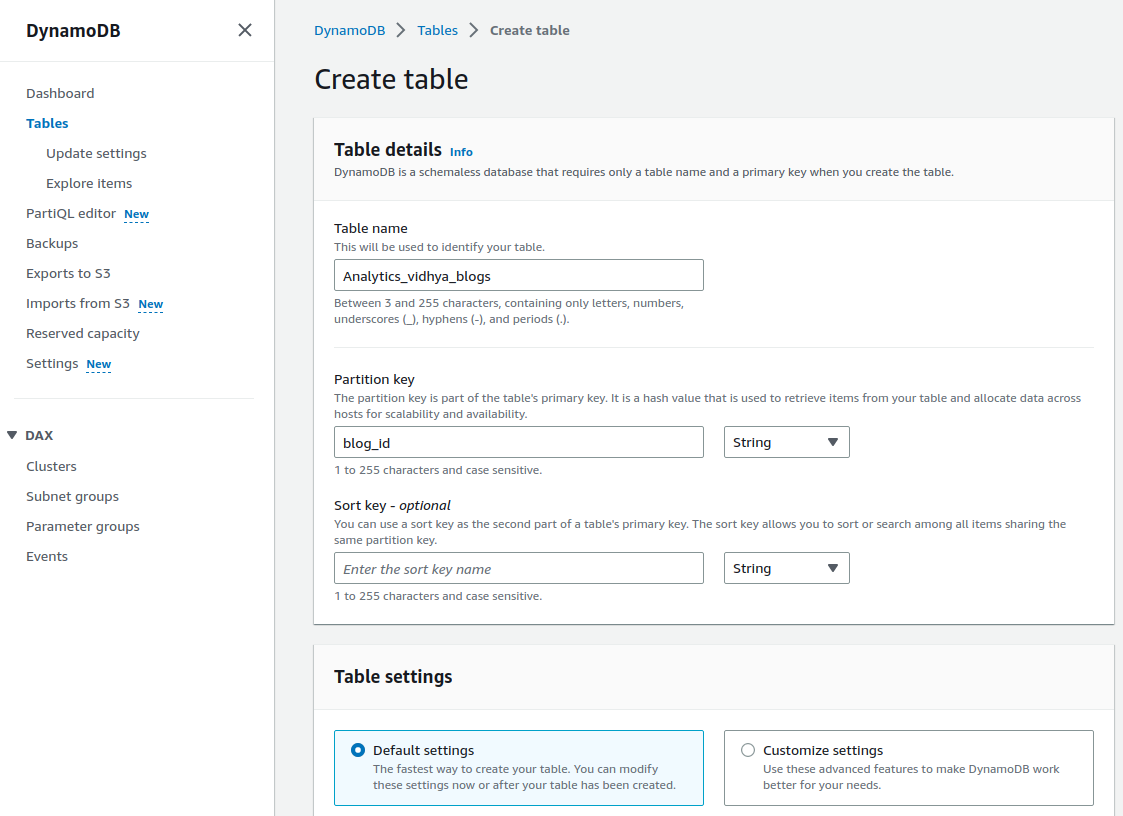
DynamoDB – DynamoDB is a NoSQL database service; create a table on it with a unique table name and a primary key. Create the table with the following configuration.
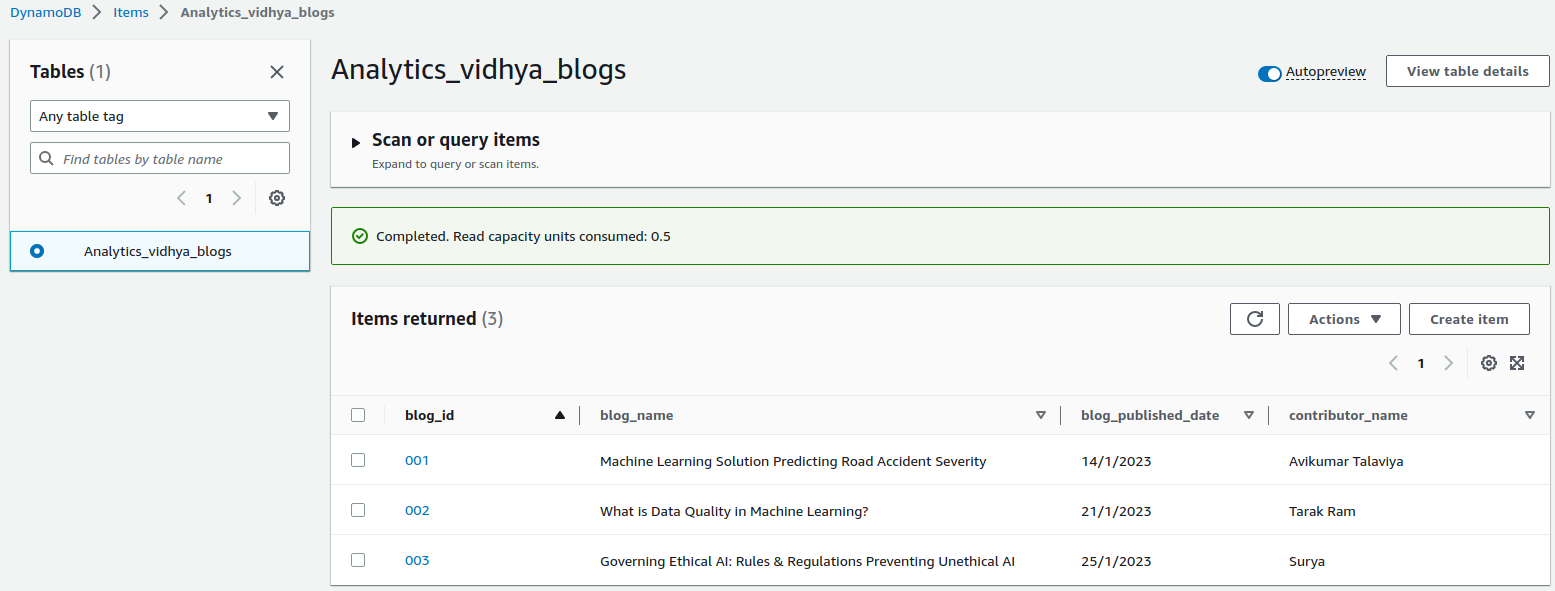
Adding Data to visualize the exporting of this DynamoDB table into an S3 bucket using the AWS Data pipeline.
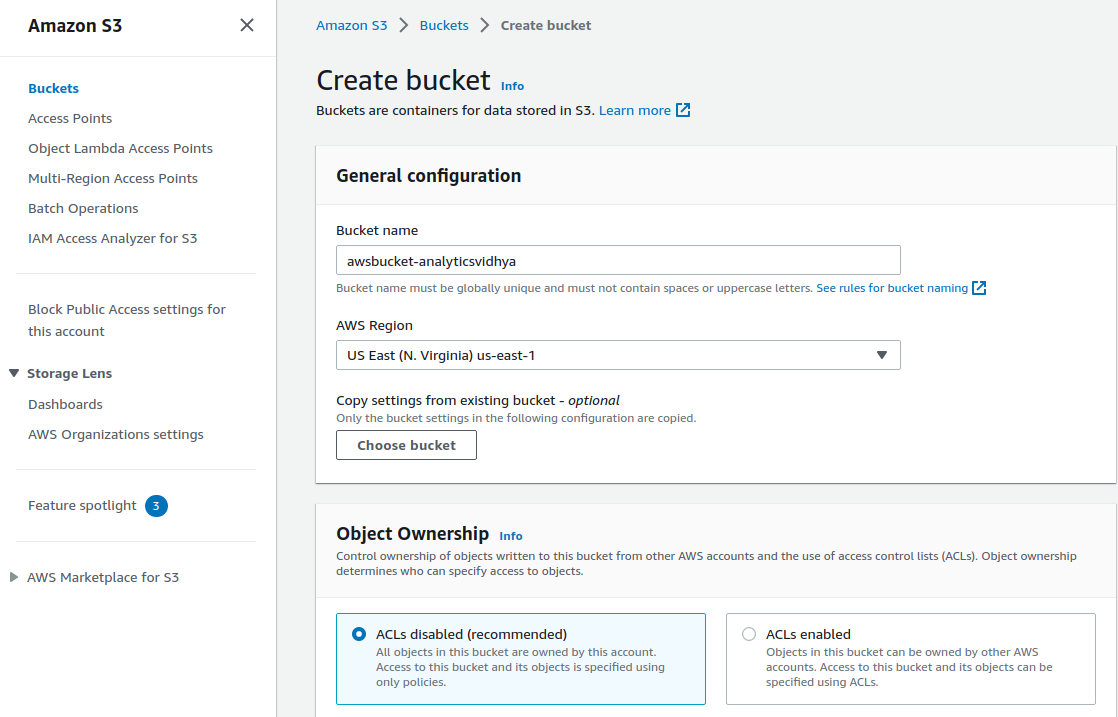
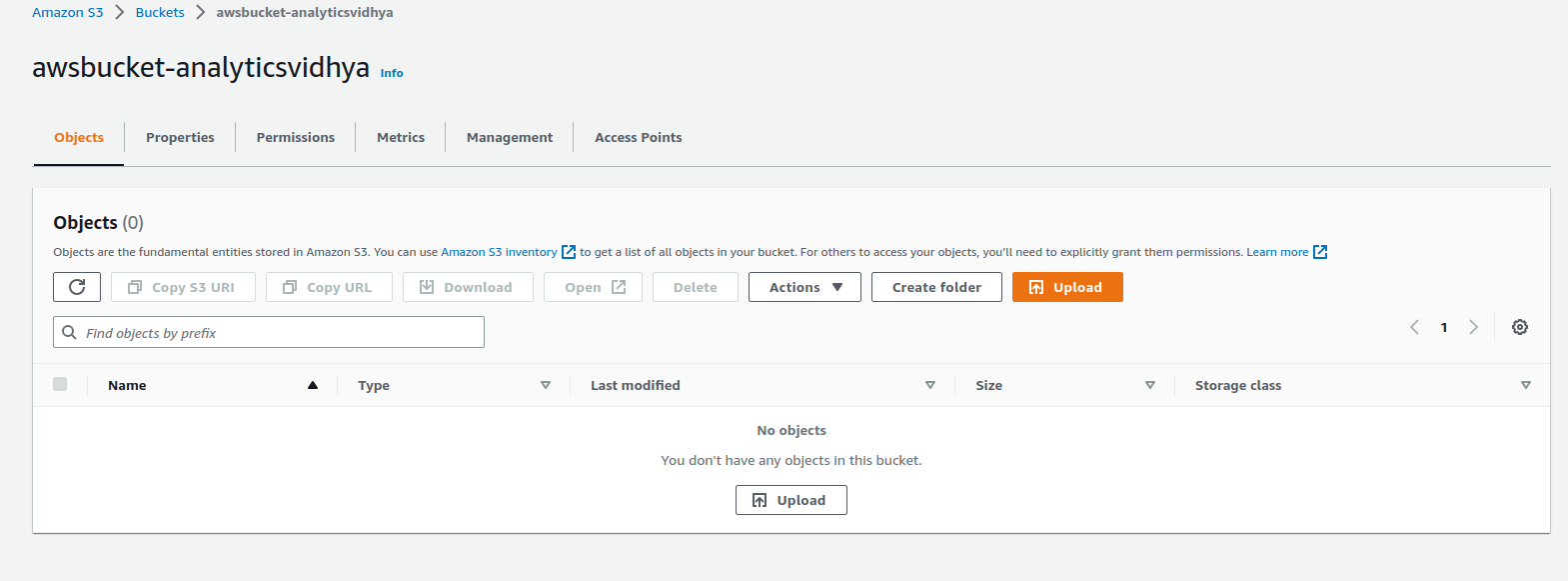
Amazon Simple Storage Service (S3)
- Create an Amazon simple S3 with a unique bucket name and select the AWS Region where the DynamoDB is deployed.
-
Create the Bucket.
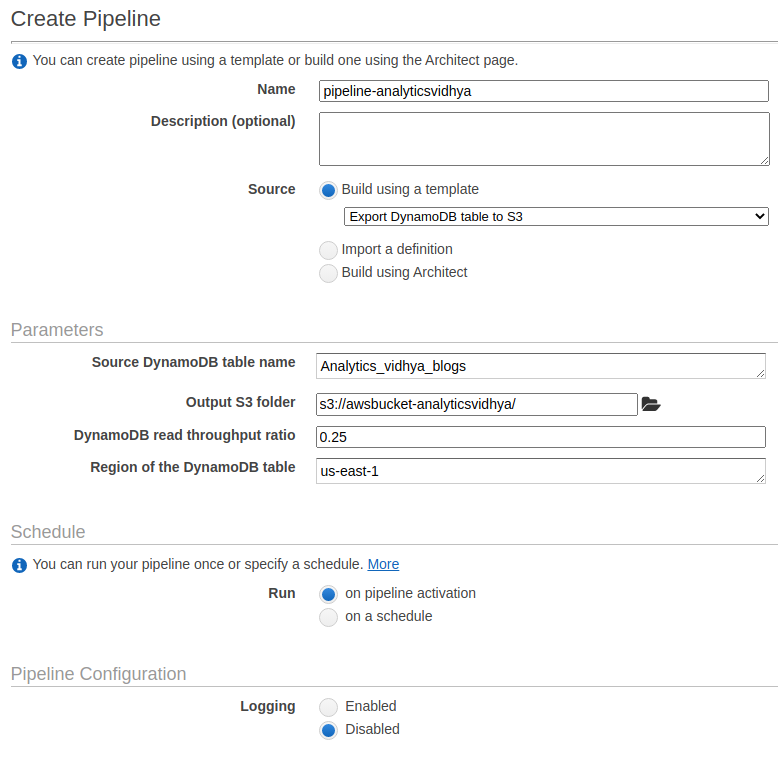
AWS Data Pipeline Service
- Create a Data pipeline with a suitable name and Description, which is optional.
- Choose the Source: We are exporting the DynamoDB table to a Simple storage service.
- Enter the name of DynamoDB that has been created.
Parameters
- Select the Simple storage service bucket folder that has been created.
- DynamoDB read throughput ratio can be the default.
- Select the Region for the dynamodb table.
Schedule
- Select between on a schedule or on pipeline activation
- Here we selected “ on pipeline activation ”.
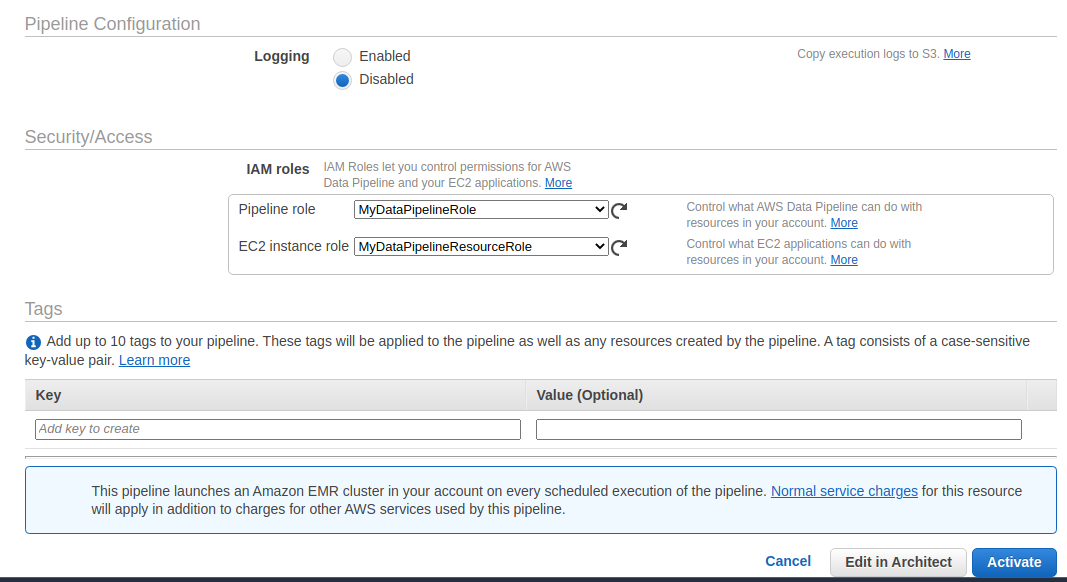
IAM Roles
AWS data pipeline requires 2 IAM roles as the following:
- The Pipeline role controls AWS Data pipeline access to AWS resources.
- The EC2 instance Role controls the application running on EC2 instances that have access to AWS resources.
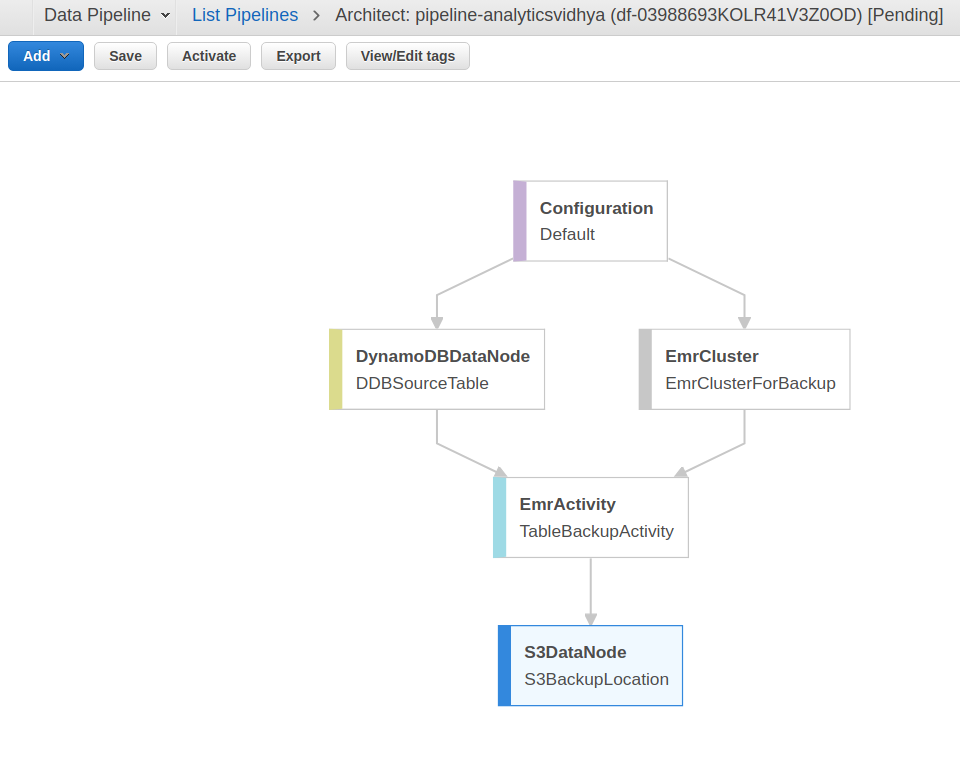
AWS Data Pipeline in Architect View
Activate the Pipeline

Two EC2 instances are deployed by the EMR cluster initiated by the pipeline.
The below image refers to the two EC2 instances

The below image refers to the EMR Cluster

After a few minutes, The exported data from the DynamoDB will be delivered to the S3 bucket we configured earlier. These data will further contribute to the processes.
Conclusion
In conclusion, AWS Data Pipeline is an efficient tool for transferring, processing, and altering data within AWS. Its automation capabilities and compatibility with multiple AWS services streamlines the data pipeline process, making it easy to deploy changes quickly. Whether you’re working with data warehousing, analytics, or machine learning, AWS Data Pipeline is a valuable tool that can help you manage your data more effectively. In short, AWS Data Pipeline is a must-have tool for those looking to optimize their data pipeline process.
Key Takeaways
- Understanding the basics of cloud computing and Amazon Web Services and its applications in today’s world.
- Learning about the importance of Data pipe in analyzing big data efficiently.
- Practically implementing data pipelines using Amazon Web Services.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.








