Introduction
Google says that BERT is a major step forward, one of the biggest improvements in the history of Search. It helps Google understand what people are looking for more accurately. Visual BERT mastery is special because it can understand words in a sentence by looking at the words before and after them. This helps it understand the meaning of sentences better. It’s like when we understand a sentence by considering all its words.

BERT helps computers understand the meaning of text in different situations. For example, it can help classify text, understand people’s feelings in a message, answer recognised questions, and the names of things or people. Using BERT in Google Search shows how language models have come a long way and make our interactions with computers more natural and helpful.
Learning Objectives
- Learn what BERT stands for (Bidirectional Encoder Representations from Transformers).
- Knowledge of how BERT is trained on a large amount of text data.
- Understand the concept of pre-training and how it helps BERT develop language understanding.
- Recognize that BERT considers both the left and right contexts of words in a sentence.
- Use BERT in search engines to understand user queries better.
- Explore the masked language model and next sentence prediction tasks used in BERT’s training.
This article was published as a part of the Data Science Blogathon.
Table of contents
What is Bert?
BERT stands for Bidirectional Encoder Representations from Transformers. It’s a special computer model that helps computers understand and process human language. It is an intelligent tool that can read and understand text like ours.
What makes BERT special is that it can understand the meaning of words in a sentence by looking at the words before and after them. It’s like reading a sentence and understanding what it means by considering all the words together.

BERT is trained using text from books, articles, and websites. This helps it learn patterns and connections between words. So, when we give BERT a sentence, it can figure out the meaning and context of each word based on its training.
This powerful ability of BERT to understand language is used in many different ways. It can also help with tasks like classifying text, understanding the sentiment or emotion in a message, and answering questions.
SST2 Dataset
Dataset Link: https://github.com/clairett/pytorch-sentiment-classification/tree/master/data/SST2
In this article, we will use the above dataset, which consists of sentences extracted from movie reviews. The value 1 represents a positive label, and the 0 represents a negative label for each sentence.

By training a model on this dataset, we can teach the model to classify new sentences as positive or negative based on the patterns it learns from the labeled data.
Models: Sentence Sentiment Classification
We aim to create a sentiment analysis model to classify sentences as positive or negative.
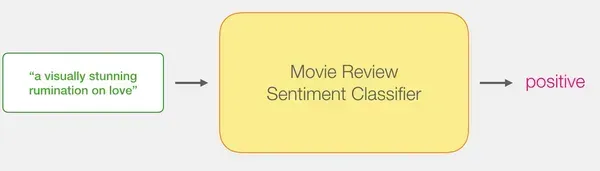

By combining the power of DistilBERT’s sentence processing capabilities with the classification abilities of logistic regression, we can build an efficient and accurate sentiment analysis model.

Generate Sentence Embeddings with DistilBERT: Utilize the pre-trained DistilBERT model to generate sentence embeddings for 2,000 sentences.

These sentence embeddings capture important information about the meaning and context of the sentences.
Perform Train/Test Split: Split the dataset into training and test sets.

Use the training set to train the logistic regression model, while the test set will be for evaluation.
Train the Logistic Regression Model: Utilize the training set to train the logistic regression model using scikit-learn.

The logistic regression model learns to classify the sentences as positive or negative based on the sentence embeddings.
By following this plan, we can leverage the power of DistilBERT to generate informative sentence embeddings and then train a logistic regression model to perform sentiment classification. The evaluation step allows us to assess the model’s performance in predicting the sentiment of new sentences.
How A Single Prediction is Calculated?
Here’s an explanation of how a trained model calculates its prediction using the example sentence “a visually stunning rumination on love”:
Tokenization: Each word in the phrase is divided into smaller components known as tokens. The tokenizer additionally inserts specific tokens such as ‘CLS’ at the start and ‘SEP’ at the end.

Token to ID Conversion: The tokenizer then replaces each token with its corresponding ID from the embedding table. The embedding table is a component that comes with the trained model and maps tokens to their numerical representations.
The shape of Input: After tokenizing and converting, DistilBERT transforms the input sentence into the proper shape for processing. It represents the sentence as a sequence of token IDs with the addition of unique tokens.

Note that you can perform all these steps, including tokenization and ID conversion, using a single line of code with the tokenizer provided by the library.

Flowing Through DistilBERT
Indeed, passing the input vector through DistilBERT follows a similar process as with BERT. The output would consist of a vector for each input token, where each vector contains 768 numbers (floats).

In the case of sentence classification, we focus only on the first vector, which corresponds to the [CLS] token. The [CLS] token is designed to capture the overall context of the entire sequence, so using only the first vector (the [CLS] token) for sentence classification in models like BERT works. The location of this token, its function in pre-training, and the pooling technique all contribute to its capacity to encode significant information for classification tasks. Furthermore, utilizing only the [CLS] token reduces computational complexity and memory requirements while allowing the model to make accurate predictions for a wide range of classification tasks. This vector is passed as the input to the logistic regression model.
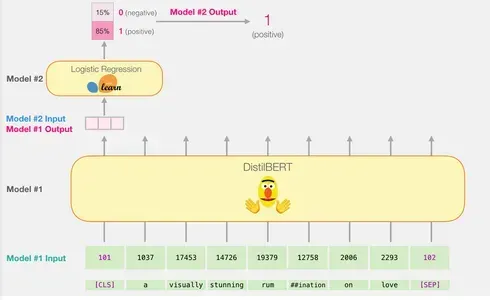
The logistic regression model’s role is to classify this vector based on what it learned during its training phase. We can envision the prediction calculation as follows:
- The logistic regression model takes the input vector (associated with the [CLS] token) as its input.
- It applies a set of learned weights to each of the 768 numbers in the vector.
- The weighted numbers are summed, and an additional bias term is added.
Finally, the summation result is passed through a sigmoid function to produce the prediction score.

The training phase of the logistic regression model and the complete code for the entire process will be discussed in the next section.
Implementation From Scratch
This section will highlight the code to train this sentence classification model.
Load the Library
Let’s start by importing the tools of the trade. We can use df.head() to look at the first five rows of the dataframe to see how the data looks.

Importing Pre-trained DistilBERT Model and Tokenizer
We will tokenize the dataset but with a slight difference from the previous example. Instead of tokenizing and processing one sentence at a time, we will process all the sentences together as a batch.
model_class, tokenizer_class, pretrained_weights = (ppb.DistilBertModel, ppb.DistilBertTokenizer,
'distilbert-base-uncased')
## Want BERT instead of distilBERT?
##Uncomment the following line:
#model_class, tokenizer_class, pretrained_weights = (ppb.BertModel, ppb.BertTokenizer,
'bert-base-uncased')
# Load pre-trained model/tokenizer
tokenizer = tokenizer_class.from_pretrained(pretrained_weights)
model = model_class.from_pretrained(pretrained_weights)
For example, let’s say we have a dataset of movie reviews, and we want to tokenize and process 2,000 reviews simultaneously. We will use a tokenizer called DistilBertTokenizer, a tool specifically designed for tokenizing text using the DistilBERT model.
The tokenizer takes the entire batch of sentences and performs tokenization, which involves splitting the sentences into smaller units called tokens. It also adds special tokens, like [CLS] at the beginning and [SEP] at the end of each sentence.
Tokenization
As a result, each sentence becomes a list of ids. The dataset consists of a list of lists (or a pandas Series/DataFrame). Shorter phrases must be padded with the token id 0 to make all the vectors the same length. Now we have a matrix/tensor that can be provided to BERT after the padding:
tokenized = df[0].apply((lambda x: tokenizer.
encode(x, add_special_tokens=True)))

Processing with DistilBERT
The padded token matrix is now turned into an input tensor, which we submit to DistilBERT.
input_ids = torch.tensor(np.array(padded))
with torch.no_grad():
last_hidden_states = model(input_ids)
The outputs of DistilBERT are stored in last_hidden_states after completing this step. Since we only considered 2000 instances, in our scenario, this will be 2000 (the number of tokens in the longest sequence from the 2000 examples) and 768 (the number of hidden units in the DistilBERT model).
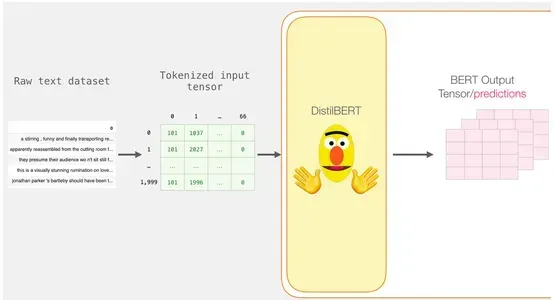
Unpacking the BERT Output Tensor
Let’s inspect the 3D output tensor’s dimensions and extract it. Assuming you have the last_hidden_states variable, which contains the DistilBERT output tensor.
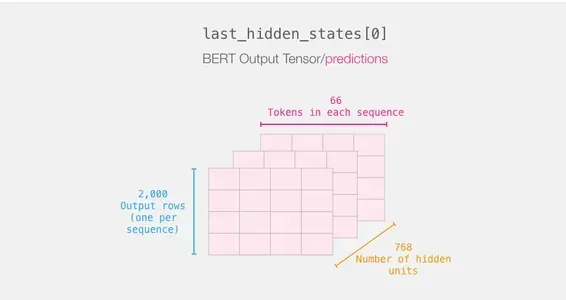
Recapping a Sentence’s Journey
Each row has a text from our dataset attached to it. To review the first sentence’s processing flow, picture it as follows:

Slicing the Important Part
We only choose that slice of the cube for sentence categorization since we are only interested in BERT’s result for the [CLS] token.

To obtain the 2d tensor we’re interested in from that 3d tensor, we slice it as follows:
# Slice the output for the first position for all the sequences, take all hidden unit outputs
features = last_hidden_states[0][:,0,:].numpy()Finally, the feature is a 2d numpy array that includes all of the sentences’ sentence embeddings from our dataset.

Apply Logistic Regression
We have the dataset needed to train our logistic regression model now that we have the output of BERT. The 768 columns in our first dataset comprise the characteristics and labels.

We may define and train our Logistic Regression model on the dataset after doing the conventional train/test split of machine learning.
labels = df[1]
train_features, test_features, train_labels, test_labels = train_test_split(features, labels)
Using this, the dataset is divided into training and test sets:

The Logistic Regression model is then trained using the training set.
lr_clf = LogisticRegression()
lr_clf.fit(train_features, train_labels)
After the model has been trained, we may compare its results to the test set:
lr_clf.score(test_features, test_labels)Which gives the model an accuracy of about 81%.
Conclusion
In conclusion, BERT is a powerful language model that helps computers understand human language better. By considering the context of words and training on vast amounts of text data, BERT can capture meaning and improve language understanding.
Key Takeaways
- BERT is a language model that helps computers understand human language better.
- It considers the context of words in a sentence, making it smarter in understanding meaning.
- BERT is trained on lots of text data to learn language patterns.
- It can be fine-tuned for specific tasks like text classification or question answering.
- BERT improves search results and language understanding in applications.
- It handles unfamiliar words by breaking them into smaller parts.
- TensorFlow and PyTorch are used with BERT.
BERT has improved applications like search engines and text classification, making them smarter and more helpful. Overall, BERT is a significant step in making computers understand human language more effectively.
Frequently Asked Questions
Q1. What are some language-related tasks that BERT can be used for?
A1: BERT can be used for various language-related tasks, including classifying text, understanding sentiment or emotion, answering questions, and recognizing named entities.
Q2. How is BERT utilized in Google Search and other applications?
A2: BERT is used in Google Search to understand user queries better and provide more relevant search results. It’s also employed in other applications to enhance language understanding and natural language processing tasks.
Q3. Describe the process of tokenization and token-to-ID conversion in BERT.
A3: Tokenization involves breaking down sentences into smaller units called tokens. Each token is then converted to its corresponding numerical ID using an embedding table. Special tokens like [CLS] (start) and [SEP] (end) are also added.
Q4. How does DistilBERT generate sentence embeddings?
A4: DistilBERT generates sentence embeddings by processing tokenized sentences through its model. The embedding corresponding to the [CLS] token is used as the sentence embedding, capturing the sentence’s overall meaning.
Q5. What is the role of logistic regression in the sentiment analysis model?
A5: Logistic regression is used to classify the sentence embeddings generated by DistilBERT as either positive or negative sentiment. It applies learned weights to the embeddings, sums them up, adds a bias term, and passes the result through a sigmoid function to produce a prediction score.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Kajal Kumari
26 Aug, 2023







