Various researches have revealed that whenever we hear an object, we retrieve it using an image from our brain. For instance, if I ask you “Do you like apples?” . You won’t think of the alphabets “a”, “p”, “p”,”l”,”e”, rather you will recall all relevant information regarding apple using the image of an apple. This is how possibly our data processing in our brain work. Of course it is complicated and highly efficient. Now if ask you “What is a database?”, you will mostly think of a collection of tables related to each other. If the same question was posed to a person in 1990s, possibly he would have only thought of a single big table from which they retrieve all the information.But today we have really moved on from this simplistic definition of databases.
This article will help you understand what type of database exist in this industry currently. I also did an interesting exercise of plotting these database types in a tree structure with a time axis. This will help you visualize how database definition and application changed with time.
Evolution of Database Management System
We are too used to timelines on Facebook. I thought it will be a good idea to start this article on a similar line. Following is a tree which will help you map all types of popular database management system in a timeline:
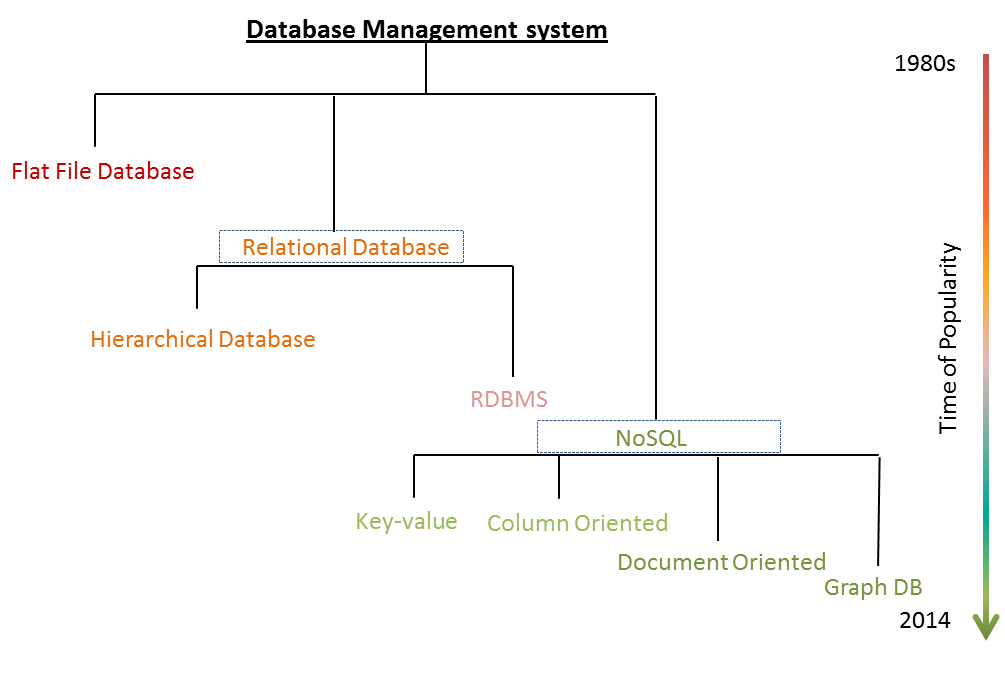
The timeline varies from 1980s to current date and is not exhaustive of all forms of data management systems. However, we will be able to cover most of the popular data management system.
Flat File Database
This is probably the easiest to understand but at present rarely used. You can think of this as a single huge table. Such type of datasets were used long back in 1990s, when data was only used to retrieve information in case of concerns. Very primitive analytics were possible on these database.
Relational Database
Soon people starting realizing that such tables will be almost impossible to store on a longer run. The Flat File brought in a lot of redundant data at every entry. For instance, if I want to make a single data-set with all products purchased at a grocery store with all information of the customer and product, we will have every single row consisting of all customer and product information. Wherever we have a repeat product or customer, we have repeat data. People thought of storing this as different tables and define a hierarchy to access all the data, which will be called as hierarchical database.
Hierarchical Database is very similar to your folder structure on the laptop. Every folder can contain sub-folder and each sub-folder can still hold more sub-folders. Finally in some folders we will store files. However, every child node (sub-folder) will have a single parent (folder or sub-folder). Finally, we can create a hierarchy of the dataset :
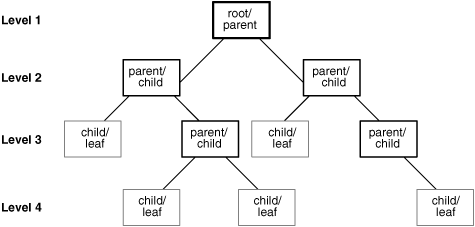 Hierarchical databases, however can solve many purposes, its applications are restricted to one-to-one mapping data structures. For example, it will work well if you are using this data structure to show job profile hierarchy in a corporate. But the structure will fail if the reporting becomes slightly more complicated and a single employee reports to many managers. Hence, people thought of database structures which can have different kinds of relations. This type of structure should allow one-to-many mapping. Such table came to be known as Relational database management system (RDBMS).
Hierarchical databases, however can solve many purposes, its applications are restricted to one-to-one mapping data structures. For example, it will work well if you are using this data structure to show job profile hierarchy in a corporate. But the structure will fail if the reporting becomes slightly more complicated and a single employee reports to many managers. Hence, people thought of database structures which can have different kinds of relations. This type of structure should allow one-to-many mapping. Such table came to be known as Relational database management system (RDBMS).
Following is an example RDBMS data structure :
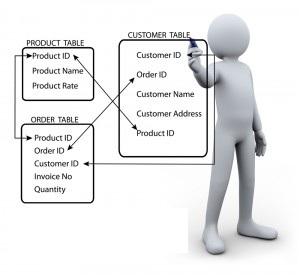
As you see from the above diagram, there are multiple keys which can help us merge different data sets in this data base. This kind of data storage optimizes disc space occupied without compromising on data details. This is the data base which is generally used by the analytics industry. However, when the data looses a structure, such data base will be of no help.
NoSQL Database
NoSQL is often known as “Not Only SQL”. When people realized that unstructured text carry tonnes of information which they are unable to mine using RDBMS, they started exploring ways to store such datasets. Anything which is not RDBMS today is loosely known as NoSQL. After social networks gained importance in the market, such database became common in the industry. Following is an example where it will become very difficult to store the data on RDBMS :
Facebook stores terabytes of additional data every day. Let’s try to imagine the structure in which this data can be structured :
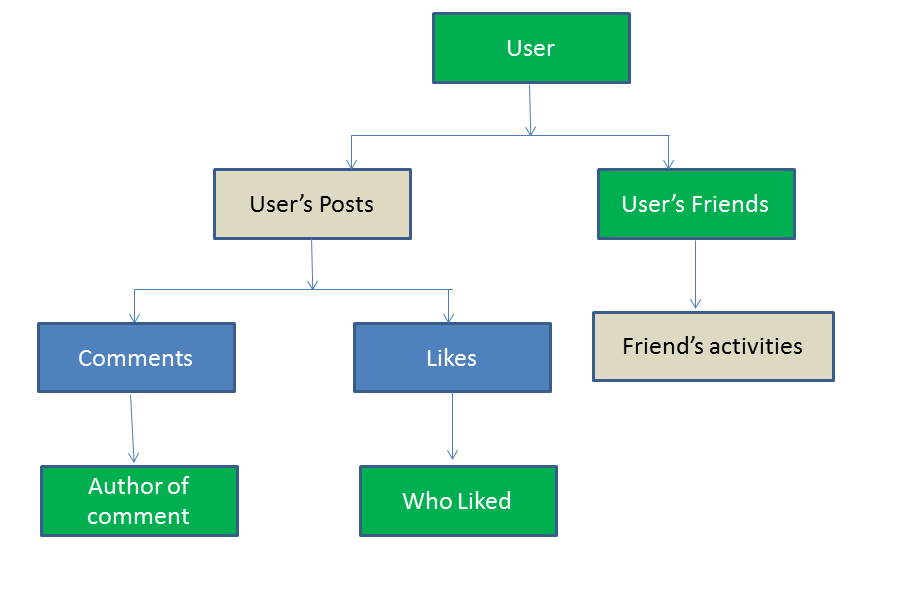 In the above diagram, same color box fall into same category object. For example the user, user’s friends, who liked and Author of comments all are FB users. Now if we try to store the entire data in RDBMS, for executing a single query which can be just a response of opening home page, we need to join multiple tables with trillions of row together to find a combined table and then run algorithms to find the most relevant information for the user. This does not look to be a seconds job for sure. Hence we need to move from tabular understanding of data to a more flow (graph) based data structure. This is what brought NoSQL structures. We will discuss NoSQL databases in our next article. We will also compare various types of NoSQL databases to understand the fitment of these databases.
In the above diagram, same color box fall into same category object. For example the user, user’s friends, who liked and Author of comments all are FB users. Now if we try to store the entire data in RDBMS, for executing a single query which can be just a response of opening home page, we need to join multiple tables with trillions of row together to find a combined table and then run algorithms to find the most relevant information for the user. This does not look to be a seconds job for sure. Hence we need to move from tabular understanding of data to a more flow (graph) based data structure. This is what brought NoSQL structures. We will discuss NoSQL databases in our next article. We will also compare various types of NoSQL databases to understand the fitment of these databases.
End Notes
Databases form the foundation of analytics industry. Even if we don’t know each one of them in detail, we should have an overview of the entire spectrum of databases. In this article we discussed the popular types of datasets and how the need of databases evolved with time. In the next article we will continue the same discussion and take it a step further by understanding types of NoSQL databases.
Did you find the article useful? Share with us your experiences with different types of databases. Do let us know your thoughts about this article in the box below.
If you like what you just read & want to continue your analytics learning, subscribe to our emails, follow us on twitter or like our facebook page.
Tavish Srivastava, co-founder and Chief Strategy Officer of Analytics Vidhya, is an IIT Madras graduate and a passionate data-science professional with 8+ years of diverse experience in markets including the US, India and Singapore, domains including Digital Acquisitions, Customer Servicing and Customer Management, and industry including Retail Banking, Credit Cards and Insurance. He is fascinated by the idea of artificial intelligence inspired by human intelligence and enjoys every discussion, theory or even movie related to this idea.




You guys are doing a great job, every time I visit your blog I am clear on few more things be it the career decisions or the actual analytic concepts. The blog posts are to the point and concise.
Good One....I liked this
I am an Analytics student and looking forward to your next article. Great for learning .. Appreciate if you could include more use cases and examples for various types of NOSql DBS. Thanks
Very informative...
sure