My father always hesitates while making big ticket transaction online. He is always scared of machine making an error. Just imagine that you transfer your entire financial asset from your one account to other and because of some data error, it gets transferred to someone else’s account. However, I do not hesitate even by for a second making any kind of transactions online. What has triggered such big difference in our perceptions. Probably the reason is the high accuracy in such transactions which I have witnessed since my early age. What makes these infinite number of transactions done in banks, with airlines, with E-commerce such accurate?
To a great extent this is because of RDBMS, which strictly adheres to ACID (atomicity, consistency, isolation, and durability) principles. But with time because of the high pressure of growing data, we have begun using NoSQL databases. NoSQL eliminates the need of a schema, hence pushing the data handling capacity by a huge margin by compromising on ACID. However, with accurate supporting applications in place, NoSQL provide a good combination of high data handling capacity with good accuracy. In this article we will discuss popular NoSQL databases.
Image Credit : http://www.tomsitpro.com
Full form of NoSQL?
NoSQL actually has no full form or even an actual meaning. The term was coined accidentally at an event by Johan Oskarsson to discuss open-source distributed network. The “#NoSQL” was just a twitter hash tag to organize this meeting. Then a few database people at this meeting found this hashtag appropriate to name these non relational database. We really do not have any strict definition for NoSQL. However, following are some common features of NoSQL databases :
1. They are not relational
2. Mostly open-source
3. They are all cluster-friendly
4. They are schema less
5. They emerged out of 21st century Web world
However, we often refer to NoSQL as schema less, this does not mean that these database do not adhere to any kind of schema. For example consider the following NoSQL expression :
Tab1[“Revenue” ] * Tab1[“Total count”]
NoSQL has an implicit schema, which might not be constant throughout the database. Such thing is both a boon and a curse. The base thing is whenever we want to modify a field we need to understand this implicit schema. The good thing is that with a changing schema it asks for much lesser effort to append this database compared to RDBMS. Also RDBMS is not great with a distributed network which is not the case with NoSQL.
Types of NoSQL databases
However, in literature NoSQL has been broken down into 4 major types, I found a very interesting way suggested by Martin Fowler to categorize NoSQL. Based on the way NoSQL stores data, it is primarily of two types :
1. Aggregate based Database
2. Graph based Database
The primary difference between the two is that in aggregate type, database tries to store all the information for a particular ID (this can be an individual or transaction or product etc.) as a single object. Whereas graph type follows the exact opposite philosophy. Graph type database tries to cut the data into highly granular information and stores them with all the shared relations or edges. We will discuss the aggregate based databases, which are more common today, in this article.
Aggregate based Databases
Let’s take an example to understand this concept of aggregate based database. Following is how an article on analyticsvidhya looks like :
 If we were using RDBMS to store our data for Analytics Vidhya, we would have created relational tables. One can be for Author related information, other can be about the article related information and even other can correspond to each categories. But when we open an article, we need all these informations together. Hence, we are more interested in aggregate information and not such granular information. However, granular information could have given me a better scope of analysis, for this purpose I might be more interested in minimizing the loading time of webpage. Hence, we need a database in which this entire information is stored at a single place. This can be termed as aggregate oriented databases.
If we were using RDBMS to store our data for Analytics Vidhya, we would have created relational tables. One can be for Author related information, other can be about the article related information and even other can correspond to each categories. But when we open an article, we need all these informations together. Hence, we are more interested in aggregate information and not such granular information. However, granular information could have given me a better scope of analysis, for this purpose I might be more interested in minimizing the loading time of webpage. Hence, we need a database in which this entire information is stored at a single place. This can be termed as aggregate oriented databases.
Key-value Databases / Document Databases :
Key-value Databases and Document Databases are very similar. You can think of Document Databases as a nested form of Key-value databases. Following is a simple key-value database :
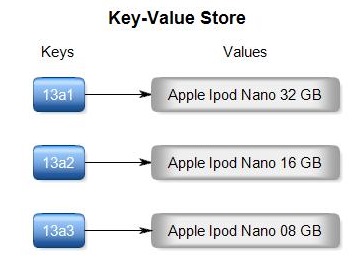
Image Credit: http://nosql.rishabhagrawal.com
Now if I want to fetch information on Ipod 16 GB, I just need to provide the ket “13a2” to the database. Following is how a document database will look like :

Note that at every document we have aggregate information on that id. Link this back to our analyticsvidhya example. In our case we will have all author name, title name etc. as key-value pairs on every document. Now I can pull the entire document in one go, as it is stored at the same object.
Column-oriented Databases :
Imagine that you have a RDBMS orders table with 1 Million rows and 100 columns. Now you want to pull all the customer names with orders of more than $500. You essentially need command on only two columns, but to do this query you will essentially have to browse through all 100 columns. Column oriented databases give a solution to this problem. A detailed discussion on this type of database is out of scope for this article, but what you need to understand is just the underlying concept. Following is a simple example of row-oriented and column-oriented database :
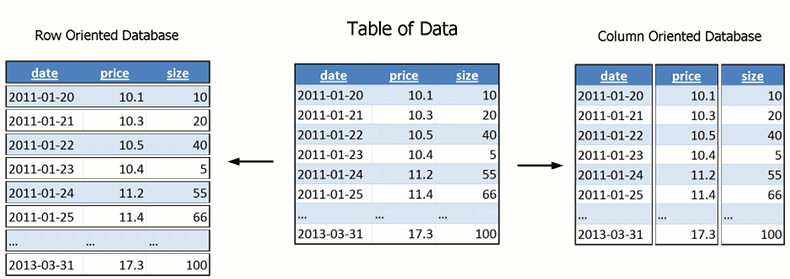
Image Credit: www.timestored.com
Column-oriented database stores each column at separate location which enables us to only reach out to those columns which are of need to us. This makes queries much faster in search and filter operations.
End Notes
NoSQL databases are extending our limits to store and analyze data. With such schema less structures they also enable us to change variables/attributes at any point in time. They are exceptionally fast to execute queries on these aggregate entities. However, this statement comes with a caption that in case the operation has to be done not on the the aggregate level of table, it becomes more complicated as compared to RDBMS. For instance, if we have data stored for each order in NoSQL aggregate database. Any query which has to do something with these order id will be exceptionally fast. But in case you need information on customer or product level, these tables might not be very efficient. For such processes you will need to write MapReduce queries. Hence, it all depends on the type of use as to which database will suit you more.
Did you find the article useful? Share with us your experiences with different types of NoSQL databases. Do let us know your thoughts about this article in the box below.
If you like what you just read & want to continue your analytics learning, subscribe to our emails, follow us on twitter or like our facebook page.
Tavish Srivastava, co-founder and Chief Strategy Officer of Analytics Vidhya, is an IIT Madras graduate and a passionate data-science professional with 8+ years of diverse experience in markets including the US, India and Singapore, domains including Digital Acquisitions, Customer Servicing and Customer Management, and industry including Retail Banking, Credit Cards and Insurance. He is fascinated by the idea of artificial intelligence inspired by human intelligence and enjoys every discussion, theory or even movie related to this idea.







Nice Article Tavish... Thanks
Got the glimpse of NoSQL database. Interesting part is two classification of NoSQL with respect to storage. Aggregated(Key-Value, Document, Column) & Graph. It Helps !
[…] NoSQL databases have inadvertently been at the forefront of this shift in the domain of distributed […]