Let’s do a simple exercise. You need to identify the subject and the sentiment in following sentences:
- Google is the best resource for any kind of information.
- I came across a fabulous knowledge portal – Analytics Vidhya
- Messi played well but Argentina still lost the match
- Opera is not the best browser
- Yes, like UAE will win the Cricket World Cup.
Was this exercise simple? Even if this looks like a simple exercise, now imagine creating an algorithm to do this? How does that sound?
The first example is probably the easiest, where you know “Google” is the subject. Also we see a positive sentiment about the subject. Automating the two components namely subject mining and sentiment mining are both difficult tasks, given the complex structure of English language.

Basic sentiment analysis is easy to implement because positive / negative word dictionary is abundantly available on internet. However, subject mining dictionaries are very niche and hence user needs to create his own dictionary to find the subject. In this article, we will talk about subject extraction and ways to automate it using Google API.
Also See: Basics of creating a niche dictionary
Why is subject extraction not a common analysis?
The most common projects using text mining are those with sentiment analysis. We rarely hear about subject mining analysis. Why is it so?
The answer is simple. Social media, the major source of unstructured data, does a good job with subject mapping. Users themselves make the subject of most comment very obvious by hash tagging. These hash tags help us search for a subject related comments on social media. And most of our analysis is based on a single subject which makes subject mining redundant. It would be awesome if we hash tag all our statements . In that case text mining would have become a cake walk because indirectly I am creating a structured text on social media. Only, if the world was ideal!
Hash tags could also help to find sarcasm to some extent. Consider the following tweet :
Indian batting line was just fine without Sachin. #Sarcasm #CWC2015 #Sachin #Indian-Cricket-Team
Think of this sentence without hash-tags. It would be incomplete and would give a different meaning. Mining for hash tag(#sarcasm) will indicate that the sentence is most probably a negative sentence. Also, multiple subjects can be extracted from the hash tags and added to this sentence.
Hopefully, you can now realize the importance of these hash tags in data management and data mining of social networks. They enable the social media companies to understand our emotions, preferences, behavior etc.
Why do we even need subject extraction?
However, social media do a good job with subject tagging, we still have a number of other sources of unstructured informations. For instance, consider the following example :
You run a grocery stores chain. Recently you have launched a co-branded card which can help you understand the buying patterns of your customers. Additionally this card can be used at other retail chains. Given, that you now will have transaction information of your customers at other retail chains, you will be in a better position to increase the wallet share of the customer at your store. For instance, if a customer buys all vegetables at your store but fruits at other, you might consider giving the customer a combo of fruits & vegetables.
In this scenario, you need to mine the name of retail store and some description around the type of purchase from the transaction description. No hash-tags or other clues, hence you need to do the hard work!
What are the challenges in subject extraction?
There are multiple other scenarios where you will need to do subject mining. Why do we call it a “hard work”? Here are the major challenges you might face while subject mining :
- Rarely do we find a ready-made dictionary to mine subjects.
- Creating a subject based dictionary is extremely manual task. You need to pull a representative sample then pull those keywords and find a mapping subject.
- Standardization of subjects is another challenge. For instance, take following transaction description :
- “Pizza Hut paid $50”
- “Pizzahut order for $30”
Now even if we build a system which can populate the first/first 2 words as the subject, we can’t find a common subject for the above two. Hence, we need to build a dictionary which can identify a common subject i.e. “Pizza Hut” for both these sentences.
Possible Framework to build a Subject Extraction Dictionary
There are two critical steps in building a subject mining dictionary:
- Find the keywords occurring frequently in the text. This has been covered in detail in this article.
- Create a mapping dictionary from these keywords to a standardized subject list.
For second part, here are the sub-steps you need to follow :
- Find the most frequent words in your text / tweets / comments. (assume a minimum threshold for a word to appear in the list).
- Find the most associated word with these frequently occurring word. (You again need to assume a minimum association threshold)
- Combine the frequently occurring words with associated words to find searchable pairs.
Now all we need to do is to match subjects for each of these pairs. We search pairs and not single words because we need enough context to search for the phrase. For example “Express” might mean “American Express” or “Coffee Express”, two words can give enough context whereas more than two words will make the dictionary too big.
Here are some examples of this process :
“Wall Mart has the best offers”
“Tesco stores are not good with discounts”
“New Wall Mart stores are supposed to open this year”
“Tesco Stores have the coolest loyalty programs and discounts”
Most Frequent words: After removing stop-words : 1. Wall 2. Mart 3.Tesco 4. Stores
Most Associated words: 1. Wall & Mart , 2. Mart & Wall , 3. Tesco & Stores , 4. Stores & Tesco
Now we’ll use these words to search for the right subject.
How to automate the process of Subject Extraction Dictionary Creation?
Second step of subject mining is creating keyword to subject pairs. This step is generally done manually, but let’s take a shot at automating this process. Here is what we intend to do :
- Pick up the keyword pairs found significant in the context (coming from last step).
- Google Search on this pair
- Pick the first 4 links which Google would give.
- If two of the first 4 links are same, we return back to the URL. In case the search is not unanimous, we return “No Match Found”.
Let’s first create a function which can retrieve the first four links from Google on a search and then find if we have a common link. Here is code to do the same :

Now, let’s create a list of keywords which our code can search. (Notice that each of these keywords are quite different but Google will help us standardize them)
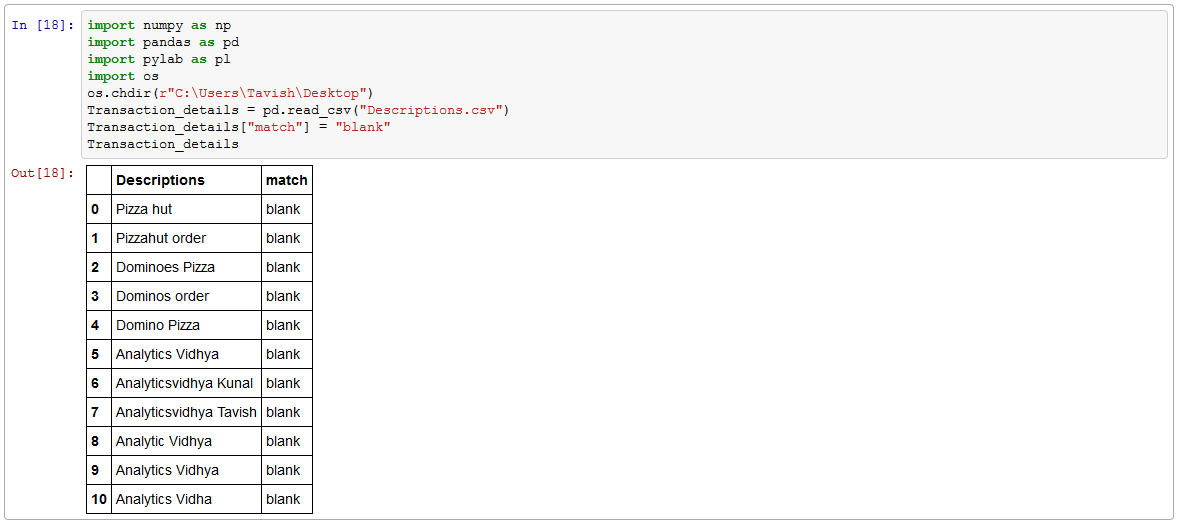
Its now time to test our function :
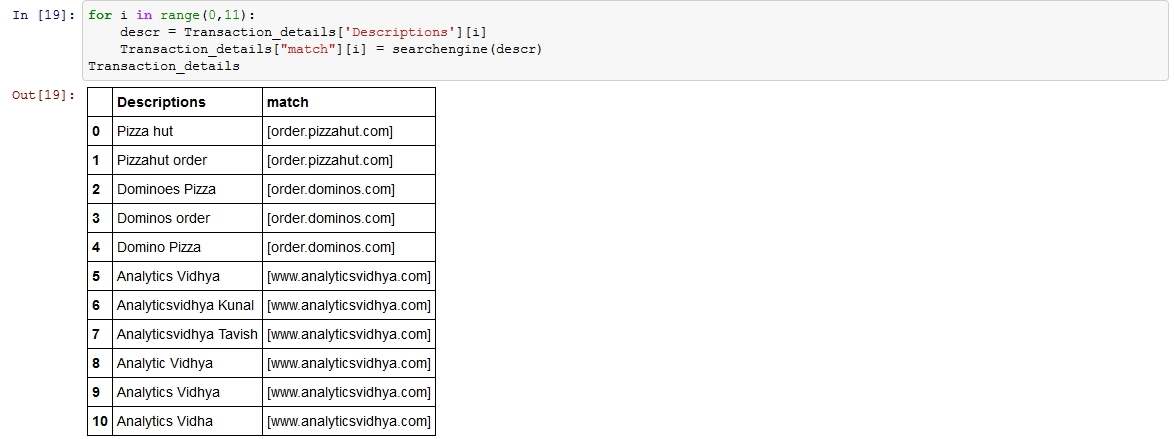
And Bingo! You see that our code was given different inputs but our code has done fairly well to spot the right set of subjects. Also notice that this dictionary is not limited by any scope of the subject. Two of its searches are Fast Food chains. Third one is an analytics website. Hence, we are creating a more generalized dictionary in this case. Now all we need to do is build rules using these keywords and map them to the matched links.
Here is the entire code :
[stextbox id=”grey”]import urllib
import json
import numpy as np
from urlparse import urlparse
from bs4 import BeautifulSoup
def searchengine(examplesearch):
encoded = urllib.quote(examplesearch)
rawData = urllib.urlopen('http://ajax.googleapis.com/ajax/services/search/web?v=1.0&q='+encoded).read()
jsonData = json.loads(rawData)
searchResults = jsonData['responseData']['results']
links = np.empty([4, 1], dtype="S25")
i = 0
for er in searchResults:
link = er['url']
link1 = urlparse(link).netloc
links[i,0]=link1
i = i + 1
target = "No Match found"
if links[0,0] == links[1,0] or links[0,0] == links[2,0] or links[0,0] == links[3,0]:
target = links[0,0]
if links[1,0] == links[2,0] or links[1,0] == links[3,0]:
target = links[1,0]
if links[2,0] == links[3,0] :
target = links[2,0]
return [target]
import numpy as np
import pandas as pd
import pylab as pl
import os
os.chdir(r"C:\Users\Tavish\Desktop")
Transaction_details = pd.read_csv("Descriptions.csv")
Transaction_details["match"] = "blank"
Transaction_details
for i in range(0,11): descr = Transaction_details['Descriptions'][i] Transaction_details["match"][i] = searchengine(descr) Transaction_details[/stextbox]
End Notes
The approach mentioned in this article can be used to create a generalized dictionary which is not restricted to any subject. Frequently, we use the super powers of Google to auto correct the input keywords to get the most appropriate results. If this result is unanimous, it tells us Google has found a decent match from the entire web world. This approach minimizes the human effort of creating such tedious subject extraction dictionaries.
Thinkpot: Can you think of more cases where Google API’s are used? Share with us useful links of related video or article to leverage Google API
Did you find the article useful? Do let us know your thoughts about this article in the box below.
If you like what you just read & want to continue your analytics learning, subscribe to our emails, follow us on twitter or like our facebook page.
Tavish Srivastava, co-founder and Chief Strategy Officer of Analytics Vidhya, is an IIT Madras graduate and a passionate data-science professional with 8+ years of diverse experience in markets including the US, India and Singapore, domains including Digital Acquisitions, Customer Servicing and Customer Management, and industry including Retail Banking, Credit Cards and Insurance. He is fascinated by the idea of artificial intelligence inspired by human intelligence and enjoys every discussion, theory or even movie related to this idea.







hi tavish, your approach is excellent and innovative. I used think of doing my compulsory project work on the impact of search suggestions google shows to us while we type our search string. I have a feeling that such suggestions distract the user from his original intended search/purpose. but, I'm unable to copy all those suggestions without really selecting each and everyone. Plz let me know that if there a way to get those suggestions through Google API? ( Though I have already completed my MBA, I'm still interested to know.)
Hi Sumalatha, It is possible to extract the entire page using Google API but the process is slightly more complex. It involves extracting text using BeautifulSoup. You can find multiple tutorials for the same. I will try to publish such article in future if we get enough requirement from people reading this article. Thanks, Tavish