Do you understand how does logistic regression work? If your answer is yes, I have a challenge for you to solve. Here is an extremely simple logistic problem.
X = { 1,2,3,4,5,6,7,8,9,10}
Y = {0,0,0,0,1,0,1,0,1,1}
Here is the catch : YOU CANNOT USE ANY PREDEFINED LOGISTIC FUNCTION!
Why am I asking you to build a Logistic Regression from scratch?
Here is a small survey which I did with professionals with 1-3 years of experience in analytics industry (my sample size is ~200).
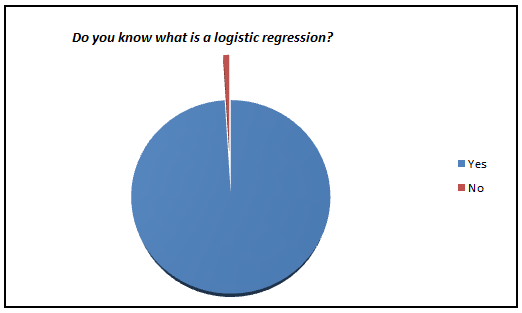
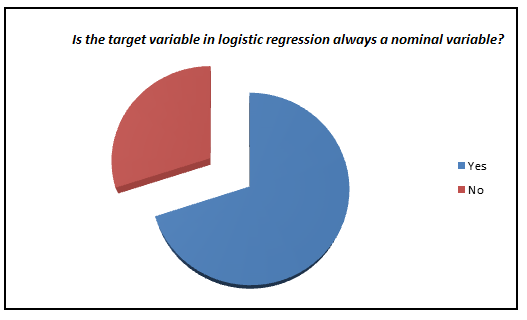
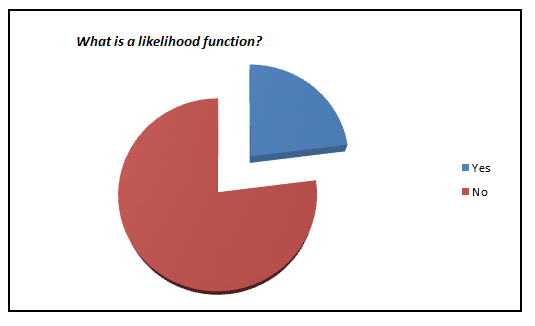
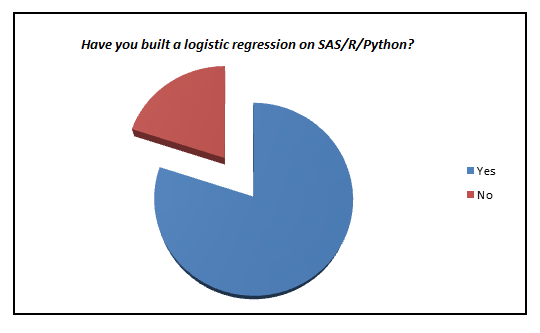
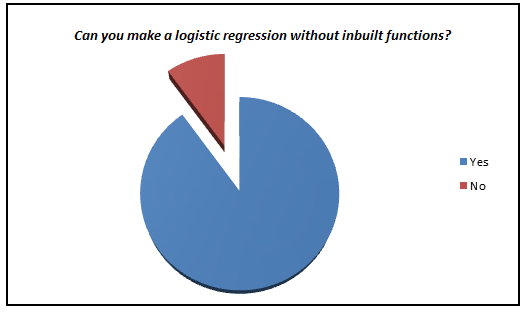
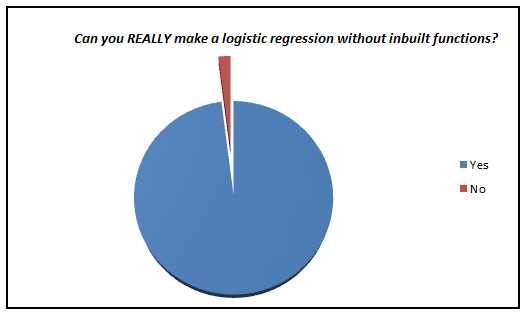
I was amazed to see such low percent of analyst who actually knows what goes behind the scene. We have now moved towards a generation where we are comfortable to see logistic regression also as a black box. In this article, I aim to kill this problem for once and all. The objective of the article is to bring out how logistic regression can be made without using inbuilt functions and not to give an introduction on Logistic regression.
Refreshers of mathematics terminology
Logistic regression is an estimation of Logit function. Logit function is simply a log of odds in favor of the event. This function creates a s-shaped curve with the probability estimate, which is very similar to the required step wise function. Here goes the first definition :
Logit Function:
Logistic regression is an estimate of a logit function. Here is how the logit function looks like: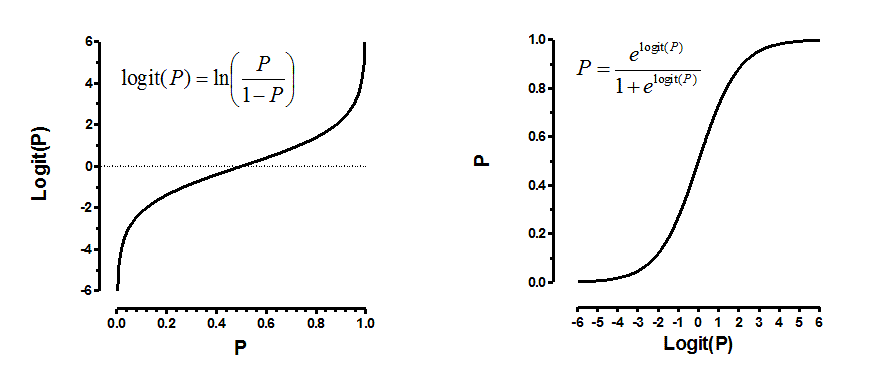
Now that you know what we are trying to estimate, next is the definition of the function we are trying to optimize to get the estimates of coefficient. This function is analogous to the square of error in linear regression and is known as the likelihood function. Here goes our next definition.
Likelihood Function
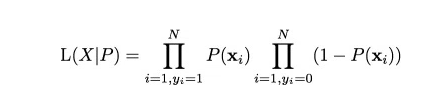
Given the complicated derivative of the likelihood function, we consider a monotonic function which can replicate the likelihood function and simplify derivative. This is the log of likelihood function. Here goes the next definition.
Log Likelihood
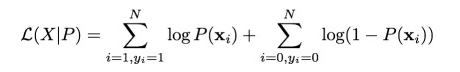
Finally we have the derivatives of log likelihood function. Following are the first and second derivative of log likelihood function.
Derivative of Likelihood Function
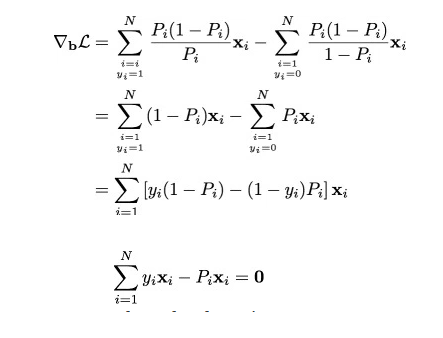
Hessian Matrix (second derivative)
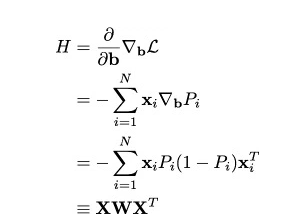
Finally, we are looking to solve the following equation.
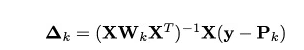
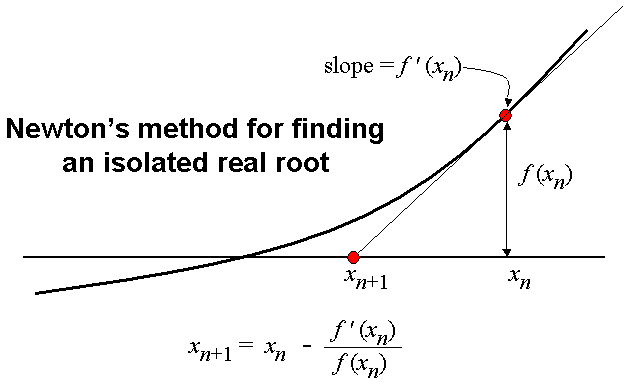
As we now have all the derivative, we will finally apply the Newton Raphson method to converge to optimal solution. Here is a recap of Newton Raphson method.
Newton Raphson Method
The Code
Here is a R code which can help you make your own logistic function
Let’s get our functions right.
#Calculate the first derivative of likelihood function given output (y) , input (x) and pi (estimated probability)
calculateder <- function(y,x,pi) {
derv <- y*x - pi*x
derv_sum <- sum(derv)
return(derv_sum)
}
#Calculate the likelihood function given output(y) and pi
calculatell <- function(y,pi) {
ll <- 1
ll_unit <- 1:length(y)
for (i in 1:length(y)){
ll_unit[i] <- ifelse(y[i] == 1,pi[i],1-pi[i])
ll = ll_unit[i]*ll
}
return(ll)
}
#Calculate the value of pi (predictions on each observation) given x_new(input) and estimated betas
findpi <- function(x_new,beta){
pi <- 1:nrow(x_new)
expon <- 1:nrow(x_new)
for (i in 1:nrow(x_new)){
expon[i] <- 0
for (j in 1:ncol(x_new)){
expo <- x_new[i,j] * beta[j]
expon[i] <- expo + expon[i]}
pi[i] <- exp(expon[i])/(1+exp(expon[i]))
}
return(pi)
}
#Calculate the matrix W with all diagnol values as pi
findW <- function(pi){
W <- matrix(0,length(pi),length(pi))
for (i in 1:length(pi)){
W[i,i] <- pi[i]*(1-pi[i])
}
return(W)
}
# Lets now make the logistic function given list of required inputs
logistic <- function(x,y,vars,obs,learningrate,dif) {
beta <- rep(0, (vars+1))
bias <- rep(1, obs)
x_new <- cbind(bias,x)
derivative <- 1:(vars+1)
diff <- 10000
while(diff > dif) {
pi <- findpi(x_new,beta)
pi <- as.vector(pi)
W <- findW(pi)
derivative <- (solve(t(x_new)%*%W%*%as.matrix(x_new))) %*% (t(x_new)%*%(y - pi))
beta = beta + derivative
diff <- sum(derivative^2)
ll <- calculatell(y,pi)
print(ll)
}
return(beta)
}
# Time to test our algorithm with the values we mentioned at the start of the article x <- 1:10 y <- c(rep(0, 4),1,0,1,0,1,1) a <- logistic(x,y,1,10,0.01,0.000000001) calculatell(y,findpi(x_new,a)) #Log Likelihood = 0.01343191 data <- cbind(x,y) data <- as.data.frame(data) mylogit <- glm(y ~ x, data = data, family = "binomial") mylogit preds <- predict(mylogit, newdata = data,type ="response") calculatell(data$y,preds) #Log Likelihood = 0.01343191 #Isn't this amazing!!!
End Notes
This might seem like a simple exercise, but I feel that this is extremely important before you start using Logistic as a black box. As an exercise you should try making these calculations using a gradient descent method. Also, for people conversant with Python, here is a small challenge to you – can you write a Python code for the larger community and share it in comments below?
Did you find this article useful? Have you tried this exercise before? I’ll be happy to hear from you in the comments section below.
If you like what you just read & want to continue your analytics learning, subscribe to our emails, follow us on twitter or like our facebook page.
Tavish Srivastava
26 Jun, 2020
Tavish Srivastava, co-founder and Chief Strategy Officer of Analytics Vidhya, is an IIT Madras graduate and a passionate data-science professional with 8+ years of diverse experience in markets including the US, India and Singapore, domains including Digital Acquisitions, Customer Servicing and Customer Management, and industry including Retail Banking, Credit Cards and Insurance. He is fascinated by the idea of artificial intelligence inspired by human intelligence and enjoys every discussion, theory or even movie related to this idea.








Excellent Write up Tavish
Finally the most hurting thorn for a beginner has been pricked out... Thank you Tavish for such a simple and useful explanation of Logistic regression.
This is good stuff. I took up your challenge to build a logistic regression from scratch in Python. Here is my attempt. It seems to work fine. Let me know your thoughts. # Step 1: defining the likelihood function def likelihood(y,pi): import numpy as np ll=1 ll_in=range(1,len(y)+1) for i in range(len(y)): ll_in[i]=np.where(y[i]==1,pi[i],(1-pi[i])) ll=ll*ll_in[i] return ll # Step 2: calculating probability for each observation def logitprob(X,beta): import numpy as np rows=np.shape(X)[0] cols=np.shape(X)[1] pi=range(1,rows+1) expon=range(1,rows+1) for i in range(rows): expon[i]=0 for j in range(cols): ex=X[i][j]*beta[j] expon[i]=ex+expon[i] with np.errstate(divide='ignore', invalid='ignore'): pi[i]=np.exp(expon[i])/(1+np.exp(expon[i])) return pi # Step 3: Calculate the W diagonal matrix def findW(pi): import numpy as np W=np.zeros(len(pi)*len(pi)).reshape(len(pi),len(pi)) for i in range(len(pi)): print i W[i,i]=pi[i]*(1-pi[i]) W[i,i].astype(float) return W # Step 4: defining the logistic function def logistic(X,Y,limit): import numpy as np from numpy import linalg nrow=np.shape(X)[0] bias=np.ones(nrow).reshape(nrow,1) X_new=np.append(X,bias,axis=1) ncol=np.shape(X_new)[1] beta=np.zeros(ncol).reshape(ncol,1) root_diff=np.array(range(1,ncol+1)).reshape(ncol,1) iter_i=10000 while(iter_i>limit): print iter_i, limit pi=logitprob(X_new,beta) print pi W=findW(pi) print W print X_new print (Y-np.transpose(pi)) print np.array((linalg.inv(np.matrix(np.transpose(X_new))*np.matrix(W)*np.matrix(X_new)))*(np.transpose(np.matrix(X_new))*np.matrix(Y-np.transpose(pi)).transpose())) print beta print type(np.matrix(np.transpose(Y-np.transpose(pi)))) print np.matrix(Y-np.transpose(pi)).transpose().shape print np.matrix(np.transpose(X_new)).shape root_diff=np.array((linalg.inv(np.matrix(np.transpose(X_new))*np.matrix(W)*np.matrix(X_new)))*(np.transpose(np.matrix(X_new))*np.matrix(Y-np.transpose(pi)).transpose())) beta=beta+root_diff iter_i=np.sum(root_diff*root_diff) ll=likelihood(Y,pi) print beta print beta.shape return beta
Hi, nice effort. Can you please provide a guide for building logistic regression in sas , it would be really helpful.Thanks in advance.
Hi Tavish, is there any package in R which will take my function as input and build the curve for the same ? Like if I give my logistic function as input then any package in R which can develop a curve for that. ? any idea/guess would be appreciated. Thanks.
Hi, I did not understand the use of second derivative and newton rhapson method here. Thanks for your explanation.