Introduction
One of the books I read in initial days of my career was titled “What got you Here, Won’t Get You There”. While the book has been written quite a few years back, the learnings from the book still hold! In his book, Marshall Goldsmith explains that at times the habits which got us at our current place would hold us back from taking ourselves to the next level.
I saw this live in action (once again) in the hackathon we hosted last weekend! Close to 1200 data scientists across the globe participated in Black Friday Data Hack. It was a 72 hours data science challenge and I am sure every participant from the competition walked away as a winner – taking away a ton of learning or earning from it!
Even in such a short duration contest, all the toppers challenged themselves and took a path less traveled. And guess what, it paid off! Not only did they break away from other data scientists, but they were also able to come out with solutions which stood out from other solutions. More on this later!
The preparations:
Like always, we decided to experiment with ground rules in our hackathon. This time, we simplified the design (no surprises during the hackathon) and made sure that we put in extra efforts on making sure the dataset is good.
Over the coming days – multiple datasets were rejected, various problems were declared as “Not Good Enough”. Finally, we were able to get a dataset, which would have something for everyone. The beginners can perform basic exploration, while there was enough room for out of box thinking for advanced users.
The Competition:
With close to 1,050 registrations and 3 days to go, we launched the competition on midnight of 19th – 20th November. There was a positive feedback on the dataset with in an hour and people started taking stab at various approaches overnight.
During the 3 days, we saw close to 2,500 submissions and 162 people making attempts at the leaderboard. The race to the top and top 10 was tough! People were constantly flowing in and flowing out of the race.
The best part – there was constant learning for everyone in the process. Leaders happily shared the benchmark scripts. Newbies followed the cues and learnt the tricks of the trade.
At the end, the winners stood out for what they had done over three days (approaches in detail below). Here were the top 3 finishers:
- Jeeban Swain, Statistical Analyst, Walmart India (Winner)
- Nalin Pasricha, Investment Banker turned Data Scientist, Independent Consultant (2nd Position)
- Sudalai Rajkumar, Senior Data Scientist, Tiger Analytics (3rd Position)
Before I reveal their approaches, I’d want to thank these people for their immense co-operation and time. I know that they participate in these hackathons for the learning and the community and have always been helpful whenever I have asked them for any help. It’s great to connect with these people.
Also Read: Exclusive Interview with SRK, Kaggle Rank 25
Problem Statement
A retail company “ABC Private Limited” wants to understand the customer purchase behaviour (specifically, purchase amount) against various products of different categories. They have shared purchase summary of various customers for selected high volume products from last month.
The data set also contains customer demographics (age, gender, marital status, city_type, stay_in_current_city), product details (product_id and product category) and Total purchase_amount from last month.
Now, they want to build a model to predict the purchase amount of customer against various products which will help them to create personalized offer for customers against different products.
Evaluation Metric
The winner was judged on the basis of root mean squared error (RMSE). RMSE is very common and is a suitable general-purpose error metric. Compared to the Mean Absolute Error, RMSE punishes large errors.
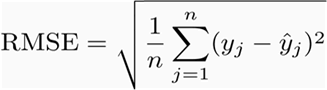
Download Data Set
For practice purpose, you can download the data set from here. This link will remain active till 29th November 2015.
Winning Strategies of this Competition
Winners used techniques like Deep Learning, Recommender, Boosting to deliver a winning model with least RMSE. Not many have used such approaches. Hence, it is interesting to acknowledge their implementation and performance. I’ve also shared their codes on our github profile. Below are the approaches, these winners used to secure their respective ranks:
Rank 3 – Sudalai Rajkumar a.k.a SRK (Used XGBoost in Python with some cool features)

SRK says:
Feature Engineering played a crucial role for me in this challenge. Since, all the given variables were categorical in nature, I decided to begin with label encoding. So, I label encoded all the given input variables. Then, built a XGBoost model using these features. I didn’t want it to end here. Therefore, in pursuit of improvement, I tried few other models as well (RandomForest, ExtraTrees etc). But, they failed to produce better results than GBM.
Then, I decided to do Feature Engineering. I created two types of encoding for all the variables and added them to the original data set:
1. Count of each category in the training set
2. Mean response per category for each of the variables in training set.
I learnt the second trick from Owen Zhang. Precisely, Slide no. 25 and 26 of his presentation on Tips for data science competitions. This turned out to be favorable for me. I tried it out and improved my score.
Finally, it was time for my finishing move, Ensemble. I built a model model which with weighted average of 4XGB models which had different subset of the above mentioned features as inputs.
Rank 2 – Nalin Pasricha (Used Matrix Factorization using Graphlab in Python)
Nalin says:
I started as a R users. But, I was determined to learn Python. This challenge was a perfect place to test myself. So, I took this challenge with Python. I knew I had a whole new world to explore, still I went ahead.
It seemed, Python didn’t turn out to be co-operative. I couldn’t install xgboost in Python. Then, I decided to find new ways.
As a result, I ended up trying several things which were new to me: Python, SFrames and Recommenders.
SFrames is similar to Pandas but is said to have some advantages over Pandas for large data sets. The only disadvantage is that, it is not so popular and well known. So, if you are stumped – Google doesn’t help.
Finally, I resorted to Recommenders. To get a recommender style solution, I used matrix factorization. The library I used was Graphlab.
I used matrix factorization because, this algorithm configured the data as a matrix containing the target variable, with user ids and product ids as rows and columns. It then filled the blanks in this matrix using factorization. Additionally, it also considered features of the users or products such as gender, product category etc. to improve the recommendation. These are called ‘side features’ in recommender jargon.
I found the recommender model to be extremely powerful, to an extent that I got second rank with this algorithm. Surprisingly, with NO feature engineering, minimal parameter tuning and cross-validation. I’m certainly hooked and plan to experiment more with other libraries of recommender algorithms.
I made 39 submissions in the contest. But, most of them were my failed attempts to get xgboost style results with linear models, random forests etc. Once I started using recommender models, my rank shot up with only a few high impact submissions. My final submission was an ensemble of three matrix factorization models, each with slightly different hyper-parameters.
For those new to recommenders, I suggest you to take this Coursera’s MOOC.
To learn more about graphlab, SFrames, recommenders and machine learning in general, I suggest you to take this course by University of Washington on Coursera.
Rank 1 – Jeeban Swain (Used Deep Learning and GBM in R)
Jeeban says:
Here is the approach I used in this competition:
Step 1: I considered all variables in the model by converting all of them into categorical features:
- User_ID – Categorical
- Product_ID- Categorical
- Gender – Categorical
- Age – Categorical
- Occupation – Categorical
- City_Category- Categorical
- Stay_In_Current_City_Years – Categorical
- Marital_Status – Categorical
- Product_Category_1 – Categorical
- Product_Category_2 – Categorical
- Product_Category_3 – Categorical
Step 2: Outlier and Missing Value treatment
- Missing value treatment was done with ‘Mode’ as all were categorical in nature.
- No Outlier Treatment
Step 3: Here is a table of all the algorithms which I tried, with their cross-validation scores:
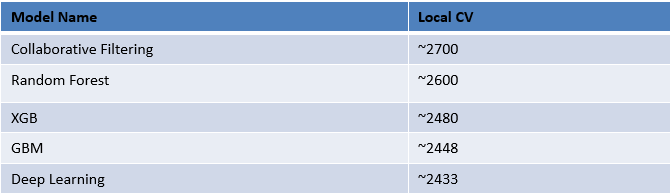
Note: Even though I have tried 5 different algorithms to solve this problem, I selected only two algorithms for my final submission (Deep Learning and GBM). My final model was ensemble of 3 DL and 2 GBM with Weighted Average.
Step 4: Here is my ensemble of 5 models:
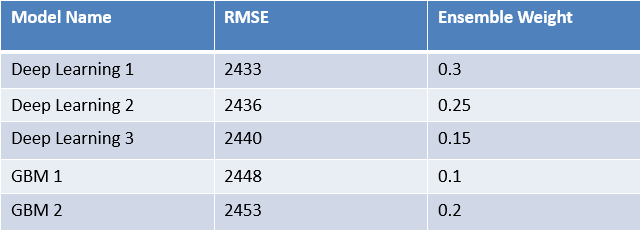
GBM Model
Note: I replaced all –ve predicted values from all the model as there were no negative purchase values in training set but my models had some negative values.
Feature Selection
I used only 3 variables for GBM model as model.as Product_ID,User_ID and Age were significant (shown below).
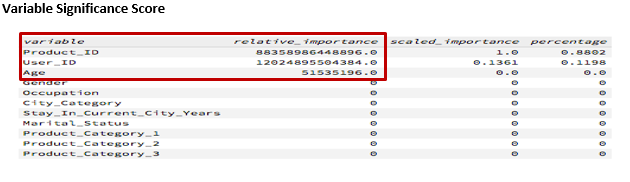
GBM Model validation score in H2O
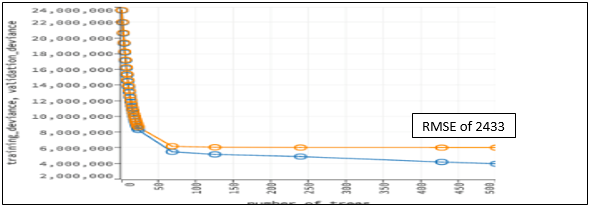
GBM Model Parameters
Most Important parameter in GBM in this case was nbin_cats=6000. This was basically for maximum number of levels in categorical variable. Here I have selected 6000 as User_ID and got 5891 unique values (you can use 5891 as well but less than that will not give you good result).
Even though I tuned my model on 70% of training sample and 30 % for validation, but for final submission I had rebuild the model on entire training set using these parameters. This has helped me to improve the score by 20 points.
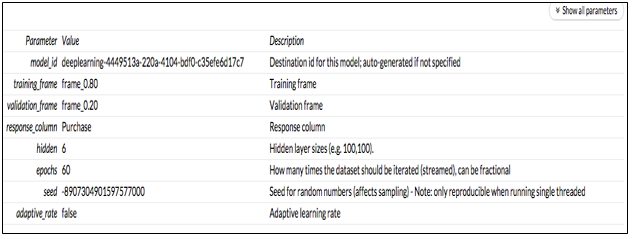
Deep Learning Model
All the variables considered for all Deep learning Model. My best score was from Deep Learning model with RMSE ~2433(Epochs=60 and layers=6) where I have created two more similar deep Learning model with hidden layers 6 and Epochs of (50, 90).
Note:Layers:6 and Epochs:60 has the lowest RMSE of 2433
Best Model Tuning Parameters

I really enjoyed participating in this competition. The adrenaline rush to improve my model in 72 hours kept me going. I learnt one thing. Till the time one doesn’t face challenges in your life, it becomes extremely difficult to reach the next level. It was indeed a challenging opportunity.
My learning and takeaways:
Like I said at the start, each of these winners did something which made them stand apart. They thought out of the box rather than just tuning parameters for a set of models and that helped them gain the ground. Here are a few things I would highlight as takeaways for myself and the participants:
- In any contest – its not over, until its over! During the contest, there were several points for people when people thought that they have reached the best solution. They thought it was difficult to improve further – but they were proved wrong again and again.
- Tool and machine are important, but winning takes much more than that. During the competition, there were several times when the language war started. A few people felt strongly that R is limiting over Python. A few people said their machines are not cut out for this dataset. If you look at the mix – the topper used R, the runner up was using Python for the first time and Rank 3 made it because of feature engineering. So, instead of calling out tool and machine as the reason for not making it – start focusing on what really matters.
- Try out as many approaches as possible. A lot of people believe that Data Science competitions can be won by creating ensembles of Random Forest and Boosting based models. If you think so, think again! A model like that would have likely took you to a top 10 this time, but you would not win.
- The only limitation you have is what you have thought for yourself. Look at Nalin – he inspires me for what he is doing. He has been an algorithmic trader for close to 12 years before taking up machine learning. How many of us would do that? He first learnt R and has made a top finish in our past hackathons. But, my respect for him doubled up this time. He was determined to find his way using Python and he did!
- Last but not the least, Keep learning!
End Notes
More than anything, you might have got huge inspiration from these people, their commitment and their unwillingness to give up. This is a great example for beginners trying to become successful in data science. Not many of us know to use Deep Learning and Graphlab in our models modeling. Hence, you must start practicing these techniques in order to develop your data science skills.
In this article, the winners of Black Friday Data Hack revealed their approaches which helped them to succeed in this challenge. The next challenge will be coming soon. Stay Tuned!
Did you like reading this article? Tell me one thing you are taking away from here? Share your opinions, suggestions in the comments section below.
If you like what you just read & want to continue your analytics learning, subscribe to our emails, follow us on twitter or like our facebook page.
Kunal Jain is the Founder and CEO of Analytics Vidhya, one of the world's leading communities of Al professionals. With over 17 years of experience in the field, Kunal has been instrumental in shaping the global Al landscape. His expertise spans diverse markets, from developed economies like the UK to emerging ones like India, where he has successfully led and delivered complex data-driven solutions. As a recognized thought leader, Kunal has empowered countless individuals to realize their Al ambitions through his visionary approach to Al education and community building. Before founding Analytics Vidhya, Kunal earned both his undergraduate and postgraduate degrees from IIT Bombay and held key roles at Capital One and Aviva Life Insurance across multiple geographies. His passion lies at the intersection of analytics, Al, and fostering a thriving community of data science professionals.




Awesome and inspiring article ! Especially i admired the way how one dared to think off using recommender for a traditional prediction problem !! Take 3 bows, AV masters !!! You are inspiring this and the generation to come..
unable to download the datasets
Sourabh, Regret the inconvenience caused. You should be able to download them now. Regards, Kunal
Hello Kunal, I really liked the article, but even more than the article, the commitment and dedication of the winners of the hackathon. You are absolutely right in saying that there are other things that matter more than the tools and machines used to solve the problems. I am still far away in my journey to understand all that was written in the article (I do commit myself to learn soon), but hats-off to all winners, especially Mr. Nalin for trying something out of the comfort zone in an important competition. Regards, Jigar