One of the best ways I’ve learned machine learning is by benchmarking myself against top data scientists in competitions. It revealed that success isn’t about superior algorithms or better machines—winners often use the same algorithms and even basic laptops like a MacBook Air. What sets them apart is their skill in feature creation and selection. They excel at creating variables that uncover hidden business insights and choosing the right ones for predictive models. These skills require practice and creativity, as some people have a knack for spotting trends that others miss. Ultimately, it’s an art honed through experience.
In this article, I will focus on one of the 2 critical parts of getting your models right – feature selection Methods. I will discuss in detail why feature selection and its Methods plays such a vital role in creating an effective predictive model.
If you are interested in exploring the concepts of feature engineering, feature selection and dimentionality reduction, check out the following comprehensive courses –
Read on!
Table of contents
What is Feature Selection Methods?
Feature selection methods help in picking the most important factors from a bunch of options to build better models in machine learning. There are three main types: Filter methods check each feature’s stats, like how much it relates to what we want to predict. Wrapper methods test different combinations of features to see which works best for a specific model. Embedded methods pick the best features while training the model itself. Each type has its pros and cons, and the choice depends on factors like dataset size and complexity. Ultimately, these methods help improve model accuracy, prevent overfitting, and make results easier to understand.
Importance of Feature Selection Methods in Machine Learning
Machine learning works on a simple rule – if you put garbage in, you will only get garbage to come out. By garbage here, I mean noise in data.
This becomes even more important when the number of features are very large. You need not use every feature at your disposal for creating an algorithm. You can assist your algorithm by feeding in only those features that are really important. I have myself witnessed feature subsets giving better results than complete set of feature for the same algorithm. Or as Rohan Rao puts it – “Sometimes, less is better!”
Not only in the competitions but this can be very useful in industrial applications as well. You not only reduce the training time and the evaluation time, you also have less things to worry about!
Top reasons to use feature selection are:
- It enables the machine learning algorithm to train faster.
- It reduces the complexity of a model and makes it easier to interpret.
- It improves the accuracy of a model if the right subset is chosen.
- It reduces overfitting.
Next, we’ll discuss various methodologies and techniques that you can use to subset your feature space and help your models perform better and efficiently. So, let’s get started.
Filter Methods

Filter methods are generally used as a preprocessing step. The selection of features is independent of any machine learning algorithms. Instead, features are selected on the basis of their scores in various statistical tests for their correlation with the outcome variable. The correlation is a subjective term here. For basic guidance, you can refer to the following table for defining correlation co-efficients.

- Pearson’s Correlation: It is used as a measure for quantifying linear dependence between two continuous variables X and Y. Its value varies from -1 to +1. Pearson’s correlation is given as:
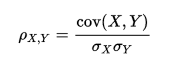
- LDA: Linear discriminant analysis is used to find a linear combination of features that characterizes or separates two or more classes (or levels) of a categorical variable.
- ANOVA: ANOVA stands for Analysis of variance. It is similar to LDA except for the fact that it is operated using one or more categorical independent features and one continuous dependent feature. It provides a statistical test of whether the means of several groups are equal or not.
- Chi-Square: It is a is a statistical test applied to the groups of categorical features to evaluate the likelihood of correlation or association between them using their frequency distribution.
One thing that should be kept in mind is that filter methods do not remove multicollinearity. So, you must deal with multicollinearity of features as well before training models for your data.
Wrapper Methods

In wrapper methods, we try to use a subset of features and train a model using them. Based on the inferences that we draw from the previous model, we decide to add or remove features from your subset. The problem is essentially reduced to a search problem. These methods are usually computationally very expensive.
Some common examples of wrapper methods are forward feature selection, backward feature elimination, recursive feature elimination, etc.
- Forward Selection: Forward selection is an iterative method in which we start with having no feature in the model. In each iteration, we keep adding the feature which best improves our model till an addition of a new variable does not improve the performance of the model.
- Backward Elimination: In backward elimination, we start with all the features and removes the least significant feature at each iteration which improves the performance of the model. We repeat this until no improvement is observed on removal of features.
- Recursive Feature elimination: It is a greedy optimization algorithm which aims to find the best performing feature subset. It repeatedly creates models and keeps aside the best or the worst performing feature at each iteration. It constructs the next model with the left features until all the features are exhausted. It then ranks the features based on the order of their elimination.
One of the best ways for implementing feature selection with wrapper methods is to use Boruta package that finds the importance of a feature by creating shadow features.
It works in the following steps:
- Firstly, it adds randomness to the given data set by creating shuffled copies of all features (which are called shadow features).
- Then, it trains a random forest classifier on the extended data set and applies a feature importance measure (the default is Mean Decrease Accuracy) to evaluate the importance of each feature where higher means more important.
- At every iteration, it checks whether a real feature has a higher importance than the best of its shadow features (i.e. whether the feature has a higher Z-score than the maximum Z-score of its shadow features) and constantly removes features which are deemed highly unimportant.
- Finally, the algorithm stops either when all features get confirmed or rejected or it reaches a specified limit of random forest runs.
For more information on the implementation of Boruta package, you can refer to this article :
For the implementation of Boruta in python, refer can refer to this article.
Embedded Methods

Embedded methods combine the qualities’ of filter and wrapper methods. It’s implemented by algorithms that have their own built-in feature selection methods.
Some of the most popular examples of these methods are LASSO and RIDGE regression which have inbuilt penalization functions to reduce overfitting.
- Lasso regression performs L1 regularization which adds penalty equivalent to absolute value of the magnitude of coefficients.
- Ridge regression performs L2 regularization which adds penalty equivalent to square of the magnitude of coefficients.
For more details and implementation of LASSO and RIDGE regression, you can refer to this article.
Other examples of embedded methods are Regularized trees, Memetic algorithm, Random multinomial logit.
Difference between Filter and Wrapper methods
The main differences between the filter and wrapper methods for feature selection are:
- Filter methods measure the relevance of features by their correlation with dependent variable while wrapper methods measure the usefulness of a subset of feature by actually training a model on it.
- Filter methods are much faster compared to wrapper methods as they do not involve training the models. On the other hand, wrapper methods are computationally very expensive as well.
- Filter methods use statistical methods for evaluation of a subset of features while wrapper methods use cross validation.
- Filter methods might fail to find the best subset of features in many occasions but wrapper methods can always provide the best subset of features.
- Using the subset of features from the wrapper methods make the model more prone to overfitting as compared to using subset of features from the filter methods.
Walkthrough example
Let’s use wrapper methods for feature selection and see whether we can improve the accuracy of our model by using an intelligently selected subset of features instead of using every feature at our disposal.
We’ll be using stock prediction data in which we’ll predict whether the stock will go up or down based on 100 predictors in R. This dataset contains 100 independent variables from X1 to X100 representing profile of a stock and one outcome variable Y with two levels : 1 for rise in stock price and -1 for drop in stock price.
To download the dataset, click here.
Let’s start with applying random forest for all the features on the dataset first.
library('Metrics')
library('randomForest')
library('ggplot2')
library('ggthemes')
library('dplyr')
#set random seed
set.seed(101)
#loading dataset
data<-read.csv("train.csv",stringsAsFactors= T)
#checking dimensions of data
dim(data)
## [1] 3000 101
#specifying outcome variable as factor
data$Y<-as.factor(data$Y)
data$Time<-NULL
#dividing the dataset into train and test
train<-data[1:2000,]
test<-data[2001:3000,]
#applying Random Forest
model_rf<-randomForest(Y ~ ., data = train)
preds<-predict(model_rf,test[,-101])
table(preds)
##preds
## -1 1
##453 547
#checking accuracy
auc(preds,test$Y)
##[1] 0.4522703Now, instead of trying a large number of possible subsets through say forward selection or backward elimination, we’ll keep it simple by using the top 20 features only to build a Random forest. Let’s find out if it can improve the accuracy of our model.
Let’s look at the feature importance:
importance(model_rf)
#MeanDecreaseGini
##x1 8.815363
##x2 10.920485
##x3 9.607715
##x4 10.308006
##x5 9.645401
##x6 11.409772
##x7 10.896794
##x8 9.694667
##x9 9.636996
##x10 8.609218
…
…
##x87 8.730480
##x88 9.734735
##x89 10.884997
##x90 10.684744
##x91 9.496665
##x92 9.978600
##x93 10.479482
##x94 9.922332
##x95 8.640581
##x96 9.368352
##x97 7.014134
##x98 10.640761
##x99 8.837624
##x100 9.914497
Applying Random forest for most important 20 features only
model_rf<-randomForest(Y ~ X55+X11+X15+X64+X30
+X37+X58+X2+X7+X89
+X31+X66+X40+X12+X90
+X29+X98+X24+X75+X56,
data = train)
preds<-predict(model_rf,test[,-101])
table(preds)
##preds
##-1 1
##218 782
#checking accuracyauc(preds,test$Y)##[1] 0.4767592
So, by just using 20 most important features, we have improved the accuracy from 0.452 to 0.476. This is just an example of how feature selection makes a difference. Not only we have improved the accuracy but by using just 20 predictors instead of 100, we have also:
- increased the interpretability of the model.
- reduced the complexity of the model.
- reduced the training time of the model.
Feature Selection Methods: Useful Tricks & Tips
Here are some useful tricks and tips for feature selection:
- Understand Your Data: Before selecting features, thoroughly understand your dataset. Know the domain and the relationships between different features.
- Filter Methods: Use statistical measures like correlation, chi-square, or mutual information to rank features based on their relevance to the target variable.
- Wrapper Methods: Employ algorithms like Recursive Feature Elimination (RFE) or Forward/Backward Selection, which select subsets of features based on the performance of a specific machine learning algorithm.
- Embedded Methods: Some machine learning algorithms inherently perform feature selection during training. Examples include LASSO (L1 regularization) and tree-based methods like Random Forests.
- Dimensionality Reduction: Techniques like Principal Component Analysis (PCA) or t-distributed Stochastic Neighbor Embedding (t-SNE) can reduce the dimensionality of your data while retaining most of the information.
- Feature Importance: For tree-based algorithms like Random Forest or Gradient Boosting Machines (GBM), you can use the built-in feature importance attribute to select the most important features.
- Domain Knowledge: Leverage domain expertise to identify features that are likely to be important. Sometimes, features that seem irrelevant on the surface might be crucial when considering domain-specific insights.
- Regularization: Regularization techniques like LASSO (L1 regularization) penalize the absolute size of the coefficients, effectively performing feature selection by driving some coefficients to zero.
- Cross-Validation: Perform feature selection within each fold of cross-validation to ensure that your feature selection process is not biased by the specific dataset splits.
- Ensemble Methods: Combine the results of multiple feature selection methods to get a more robust set of selected features.
End Notes
I believe that his article has given you a good idea of how you can perform feature selection Methods to get the best out of your models. These are the broad categories that are commonly used for feature selection. I believe you will be convinced about the potential uplift in your model that you can unlock using feature selection and added benefits of feature selection.
Saurav is a Data Science enthusiast, currently in the final year of his graduation at MAIT, New Delhi. He loves to use machine learning and analytics to solve complex data problems.






Thanks for the nice Article. 1. How does feature selection reduce overfitting? 2. How is feature importance normalized ? ( Pearson correlation gives value between -1 and 1 , LDA could have a different range )
Hi Arun. Glad you liked the article. 1. Using only the relevant features for creating your model helps you reduce the noise which comes from irrelevant features which might lower the bias but will increase the variance and thus over-fit your training set. In other words, selecting only the relevant set of features makes your model generalized. 2. Yeah, that an might pose a problem to put the importance of different filter methods onto the same scale. What can be done in this case is to choose a threshold for every test and pick out the top x% of features based on the results separately. Hope it helps.
Great article ! What is the best practice for feature selection when there are missing values in dataset ? Are there feature selection methods when there are missing values ?
Hey Mileta. Thanks! The term "best" that you have used in your question is subjective the data that you behold and the problem statement that you are looking at. There are algorithms like GBM which can deal with missing values internally in its R implementation. Although, I'll suggest you to impute the missing values first and then go for feature selection. You might find the following resources useful for missing value imputation: https://www.analyticsvidhya.com/blog/2016/03/tutorial-powerful-packages-imputing-missing-values/ https://www.analyticsvidhya.com/blog/2016/01/12-pandas-techniques-python-data-manipulation/
Great article...,.Good way to revise as well...for people who might have lost touch...
Hey Preeti. Glad you liked it!