Introduction
GitHub repositories and Reddit discussions – both platforms have played a key role in my machine learning journey. They have helped me develop my knowledge and understanding of machine learning techniques and business acumen.
Both GitHub and Reddit also keep me abreast of the latest developments in machine learning – a MUST for anyone working in this field!
And if you’re a programmer, well – GitHub is like a temple for you. You can easily download the code and replicate it on your machine. This makes learning new ideas and building a diverse skillset even easier.

I am delighted to pick out the top GitHub repositories and Reddit discussions for this month. The Reddit threads I have featured deal with both the technical aspect of machine learning as well as the career-related one. This ability to combine the two is what separates machine learning experts from the amateurs.
Below are the monthly articles we have covered so far in this series:
So, let’s get the ball rolling for March!
GitHub Repositories

PyTorch Implementation of DeepMind’s BigGAN
If I had to pick one reason for my fascination with computer vision, it would be GANs (Generative Adversarial Networks). They were invented by Ian Goodfellow only a few years back and have blossomed into a whole body of research. The recent AI art you’ve been seeing on the news? It’s all powered by GANs.

DeepMind came up with the concept of BigGAN last year but we have waited a while for a PyTorch implementation. This repository includes pretrained models (128×128, 256×256, and 512×512) as well. You can install this in just one line of code:
pip install pytorch-pretrained-biggan
And if you’re interested in reading the full BigGAN research paper, head over here.
NVIDIA’s SPADE
The ability to work with image data is becoming a defining trait for anyone interested in deep learning. The advent and rapid bloom of computer vision algorithms has played a significant part in this transformation. It won’t surprise you to know that NVIDIA is one of the prime leaders in this domain.
Just check out their developments from 2018:
- Video-to-Video Translation Technique using PyTorch
- NVIDIA’s Machine Learning Model Converts a Standard Video into Stunning Slow Motion
- NVIDIA’s FastPhotoStyle Library Will Make you an Artist
And now, NVIDIA folks have come up with another stunning release – the ability to synthesize photorealistic images given an input semantic layout. How good is it? The below comparison provides a nice illustration:

SPADE has outperformed existing methods on the popular COCO dataset. The repository we have linked above will host the PyTorch implementation and pretrained models for this technique (be sure to bookmark/star it).
This video shows how beautifully SPADE works on 40,000 images scraped from Flickr:
SiamMask – Fast Online Object Tracking and Segmentation
This repository is based on the ‘Fast Online Object Tracking and Segmentation: A Unifying Approach‘ paper. Here’s a sample result using this technique:

Awesome! The technique, called SiamMask, is fairly straightforward, versatile and extremely fast. Oh, did I mention the object tracking is done in real-time? That certainly got my attention. This repository contains pretrained models as well to get you started.
The paper will be presented at the prestigious CVPR 2019 (Computer Vision and Pattern Recognition) conference in June. The authors have demonstrated their approach in the below video:
3-D Human Pose Detection
Have you ever worked on a pose detection project? I have and let me tell you – it is superb. It’s a testament to the progress we have made as a community in deep learning. Who would have thought 10 years ago we would be able to predict a person’s next body movement?
This GitHub repository is a PyTorch implementation of the ‘Self-Supervised Learning of 3D Human Pose using Multi-view Geometry‘ paper. The authors have pioneered a new technique called EpipolarPose, a self-supervised learning method for estimating a human’s pose in 3D.
The EpipolarPose technique estimates 2D poses from multi-view images during the training phase. It then uses epipolar geometry to generate a 3D pose. This, in turn, is used to train the 3D pose estimator. This process is illustrated in the above image.
This paper has also been accepted to the CVPR 2019 conference. It’s shaping up to be an excellent line-up!
DeepCamera – World’s First AutoML Deep Learning Edge AI Platform
This is a unique repository in many ways. It’s a deep learning model open sourced to protect your privacy. The entire DeepCamera concept is based on automated machine learning (AutoML). So you don’t even need any programming experience to train a new model.

DeepCamera works on Android devices. You can integrate the code with surveillance cameras as well. There’s a LOT you can do with DeepCamera’s code, including:
- Face recognition
- Face Detection
- Control from mobile application
- Object detection
- Motion detection
And a whole host of other things. Building your own AI-powered model has never been this easy!
Reddit Discussions

I have divided this month’s Reddit discussions into two categories:
- The technical side of machine learning
- The machine learning career (roles and jobs) related discussions
Let’s start with the technical aspect.
Want to Write a Machine Learning Research Paper? Here are a Few Tips and Best Practices
Data scientists are fascinated by research papers. We want to read them, code them and perhaps even write one from scratch. How cool would it be to present your own research paper at a top-tier ML conference?

I certainly fall in the ‘want to write a research paper’ category. This discussion, started by a research veteran, delves into the best practices we should follow when writing a research paper. There’s a lot of insight and experience here – a must-read for all of us!
Here’s the GitHub repository with all the best tips, tricks and ideas in one place. Treat these pointers as a set of guidelines, and not rules written in stone.
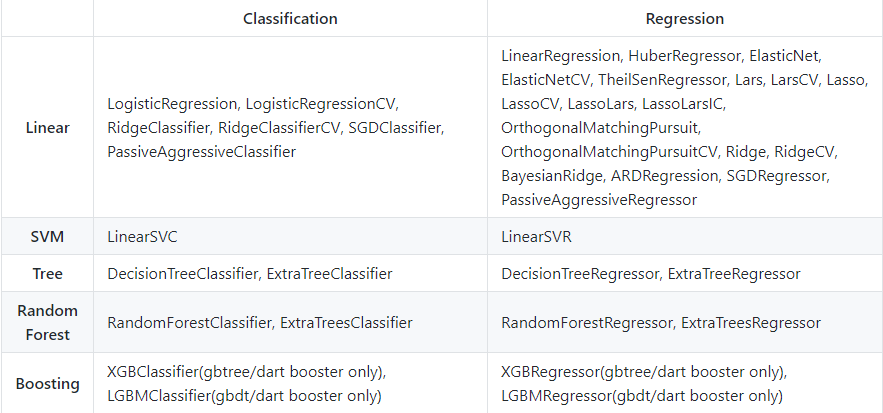
Ever Wondered how to use your Trained sklearn/xgboost/lightgbm Models in Production?
How do you put your trained machine learning models into production? How do you deploy them? These are VERY common questions you will face in your data science interview (and the job, of course). If you are not sure what this is, I strongly suggest reading about it NOW.
This discussion thread is about an open source library that converts your machine learning models into native code (C, Python, Java) with zero dependencies. You should scroll through the thread as there are a few common questions the author has addressed in detail.
You can find the full code in this GitHub repository. Below is the list of models this library currently supports:
Let’s switch focus now and go through some machine learning career discussions. These are applicable to ALL machine learning professionals, aspiring as well as established.
Automated Machine Learning will Radically Change Data Science Roles
Will the emergence of automated machine learning be a disadvantage to the field itself? That’s a question most of us have been wondering about. Most articles I come across predict all doom and gloom. Some even claim that data scientists won’t be required in 5 years!

Source: Themocracy
The author of this thread presents a wonderful argument against the general consensus. It is highly unlikely that data science will die out due to automation.
The discussion rightly argues that data science is not just about data modeling. That is only 10% of the whole process. An important part of the data science lifecycle is the human intuition behind the models. Data cleaning, data visualization and a hint of logic are what drives this entire process.
Here’s a gem, and a solid argument, that got my attention:
We developed all sorts of statistics software in the last century and yet, it hasn’t replaced statisticians.
Data Scientist Job Hunting Tips
Looking to land your first data science role? Finding it a daunting process? I’ve been there. It’s one of the biggest obstacles to overcome in our respective data science journeys.
That’s why I wanted to highlight this particular thread. It’s a really insightful discussion, where data science professionals and beginners discuss how to break into this field. The author of the post offers some in-depth thoughts on the data science job hunt process along with tips to clear each interview round.

One sentence that really stood out from this discussion:
Remember, the increase in interview requests and increased knowledge is not just a correlation, it’s a causation. As you’re applying, learn something new everyday.
We at Analytics Vidhya aim to help you land your first data science role. Check out the below awesome resources that will help you get started:
- Article – 7 Steps to crack your first Data Science Internship
- Article – 7-Step Process to Ace Data Science Interviews
- Comprehensive Course – Ace Data Science Interviews
Improving your Business Acumen as a Data Scientist
Domain knowledge – that key ingredient in the overall data scientist recipe. It’s often overlooked or misunderstood by aspiring data scientists. And that often translates to rejections in interviews. So how can you build up your business acumen to complement your existing technical data science skills?
This Reddit discussion offers quite a few useful ideas. The ability to translate your ideas and your results into business terms is VITAL. Most stakeholders you’ll face in your career will not understand technical jargon.
Here’s my favorite pick from the discussion:
You need to get to know your business partners better. Find out what they do day to day, what their processes are, how they generate the data you’re going to use. If you understand how they see X and Y, you’ll be better able to help them when they come to you with problems.
We at Analytics Vidhya strongly believe in building a structured thinking mindset. We have put together our experience and knowledge on this topic in the below comprehensive course:
This course contains various case studies which will also help you get an intuition of how businesses work and think.
End Notes
I especially enjoyed the Reddit discussions from last month. I urge you to learn more about how the production environment works in a machine learning project. It’s considered almost mandatory now for a data scientist so you can’t get away from it.
You should also take part in these Reddit discussions. Passive scrolling is good for gaining knowledge but adding your own perspective will help fellow aspirants too! This is an intangible feeling, but one you will cherish and appreciate the more experience you gain.
Which discussion did you find the most insightful? And which GitHub repository stood out for you? Let me know in the comments section below!








Great article
Thanks Prasanth!