Overview
- Here are eight ambitious data science projects to add to your data science portfolio
- We have divided these projects into three categories – Natural Language Processing, Computer Vision, and others
Introduction
There are multiple ways of learning data science. We can go through courses, pour through books, or sift through articles. All of these lack one fundamental thing, however – practice.
It all comes down to how much conceptual knowledge are you applying on a daily basis. That is what will improve, enhance and build your data science career (and consequently your chances of landing a data science role).
Did you know that top tech behemoths open source a lot of their code on GitHub? It’s a brilliant way of applying and learning data science – pick up the open-source code, understand it, play around with it, and build your own model!

So in this article, I have put together eight ambitious data science projects for you to immediately get your hands on. I have broadly divided them into three categories – Natural Language Processing (NLP), Computer Vision, and others that don’t fall into the above two sections.
This article is part of the monthly GitHub project series we host on Analytics Vidhya. Here’s the full list for 2019 in case you missed out on some mind-blowing projects:
Our Pick of 8 Data Science Projects on GitHub (September Edition)

Natural Language Processing (NLP) Projects
NLP is booming right now. It is the hottest field in data science with breakthrough after breakthrough happening on a regular basis. I feel like I’m barely getting to grips with a new framework and another one comes along.
That’s not a bad thing though! It just means there’s more to learn and experiment with. So in that spirit, here are four cool projects on Natural Language Processing that will definitely get you excited!
PLMpapers – Collection of Research Papers on Pretrained Language Models
Pretrained models are all the rage these days. Most of us don’t have a GPU sitting idle at home (let alone several of them) so it’s simply not possible to code deep neural network models from scratch.
Enter pretrained models. These have become ubiquitous with the advent of transfer learning – the ability to train a model on one dataset and then adapt that model to perform different NLP functions on a different dataset. Pretrained models enable us to use an existing model and play around with it.
This GitHub repository is a collection of over 60 pretrained language models. These include BERT, XLNet, ERNIE, ELMo, ULMFiT, among others. Here’s a diagrammatic illustration of the papers you’ll find in this repository:

This is a jackpot of a repository in my opinion and one you should readily bookmark (or star) if you’re an NLP enthusiast. Here are a few resources and excellent in-depth tutorials on some of these language models:
- How do Transformers Work in NLP? A Guide to the Latest State-of-the-Art Models
- Demystifying BERT: A Comprehensive Guide to the Groundbreaking NLP Framework
- A Step-by-Step NLP Guide to Learn ELMo for Extracting Features from Text
- Tutorial on Text Classification (NLP) using ULMFiT and fastai Library in Python
- OpenAI’s GPT-2: A Simple Guide to Build the World’s Most Advanced Text Generator in Python
Text Mining on the 2019 Mexican Government Report – A Brilliant Application of NLP
I really like this project because it shows how a simple idea can produce powerful results. The Mexican government released its annual report on September 1st and the creator of this project decided to use simple NLP text mining techniques to unearth patterns and insights.
The first challenge, as the author has highlighted in the above link, was to extract all the text from the PDF file where the report was housed. He used a library called PyPDF2 to do this. The entire process is well documented in this project along with a step-by-step explanation plus Python code.
Check out this visualization generated using seaborn:

It’s simple yet powerful – it shows the number of mentions of each state in the annual report. I would perhaps have gone with a different color scheme to bring out the most frequently mentioned state but that’s a topic for another time.
If you’re interested in generating such visualizations yourself, make sure you check out our guide to mastering seaborn:
ALBERT – A Lite Version of BERT
If you haven’t heard of BERT till now, you really need to catch up! Developed by Google, the BERT framework transformed the NLP landscape overnight.
But the original BERT pretrained models are massive in size. We can’t simply unpack them, plug them into a model and expect them to run on our local machines (not unless you have a few GPUs lying around).
This led to the creation of ALBERT – a lite version of BERT for building language models. ALBERT achieves state-of-the-art performance for a lot of NLP tasks but with only 30% parameters (you read that right!). Here’s a comparison of the two frameworks on a few popular benchmarks:
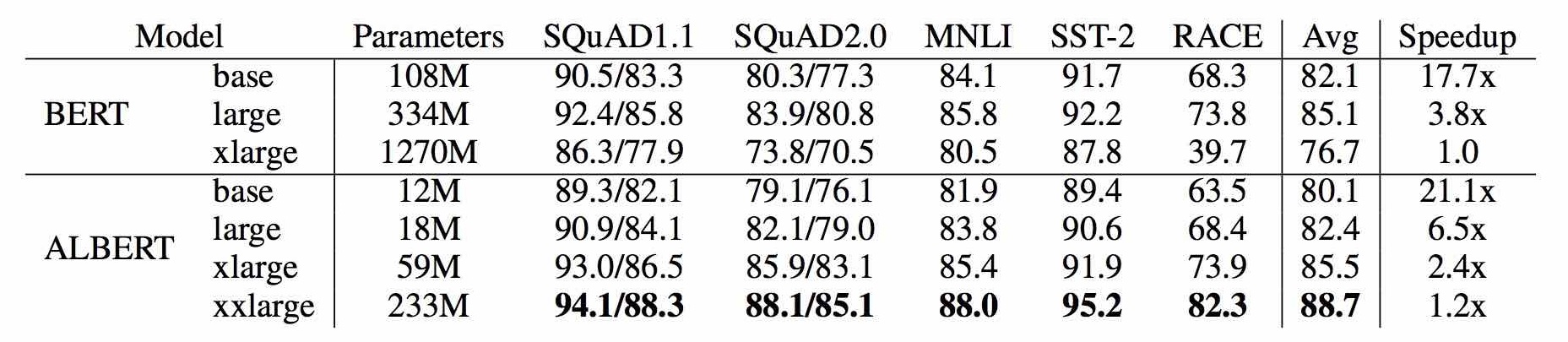
You can read the full research paper on ALBERT here. And here’s your one-stop guide to learning all about BERT and how to implement it on a real-world dataset in Python:
StringSifter – Automatically Rank Strings for Malware Analysis
This is one of the more fascinating data science projects on this list. I feel we as a community don’t spend enough time talking about cyber threats and how to use data science to build robust solutions.

StringSifter, pioneered by FireEye, “is a machine learning tool that automatically ranks strings based on their relevance for malware analysis”. What does that mean? Well, according to the developers, a malware program will often contain strings if it wants to perform operations like creating a registry key, copying a file to a specific location, etc.
This can help provide crucial insights that can help build robust malware detection programs. This is a topic you absolutely should read more on and I’ve collected two excellent articles to get you started:
- Using the Power of Deep Learning for Cyber Security (Part 1)
- Using the Power of Deep Learning for Cyber Security (Part 2)
Computer Vision Projects
Have you ever worked with image data before? How about videos? Well – you should learn how to. Advances in computer vision techniques mean there is a huge demand for specialists. But the supply is falling well short.
So you can brush up on your computer vision skills and start applying today! This is a great time to break through into this blooming field.
So make sure you check out the below two computer vision projects on GitHub to add to your portfolio. And if you’re new to the world of computer vision, I suggest taking the below comprehensive course:
Tiler – Build Images with Images
The ability to work with image data is being sought after quite a lot in the industry. It’s not really a surprise, is it? The number of images being uploaded and published these days is unprecedented. And this pace will only increase in the next few years.
Tiler is a really awesome tool that helps us create an image using all kinds of smaller images (tiles to be precise). As this repository says, “An image can be built out of circles, lines, waves, cross stitches, legos, Minecraft blocks, paper clips, letters, … The possibilities are endless!”.
You can check out some illustrated examples in the GitHub repository. Here’s one to whet your appetite:

So, go ahead and build your own images using other smaller images! And if you’re new to the world of images for machines, here are three beginner-friendly articles for you:
- 3 Beginner-Friendly Techniques to Extract Features from Image Data using Python
- 9 Powerful Tips and Tricks for Working with Image Data using skimage in Python
- Feature Engineering for Images: A Valuable Introduction to the HOG Feature Descriptor
DeepPrivacy – An Impressive Anonymization Technique for Images
Privacy is in short supply in today’s digital world. Every move we make and every touch of the screen is recorded, stored, analyzed and used to serve customized ads and offers (and many other things). One of the major downsides of this lack of privacy has been the manipulation of images.
I’m sure you must have heard of DeepFakes by now. For the uninitiated, it was the ability to manipulate a person’s expressions and facial muscles using just a few images. It’s still a problem as the algorithm behind the concept, called Generative Adversarial Networks (GANs), has continued to evolve.
That’s why I really like DeepPrivacy – a fully automatic anonymization technique for images. The GAN model behind DeepPrivacy never sees any privacy-sensitive information. It generates the image(s) considering the original pose of the person and the image background.

DeepPrivacy uses Mask R-CNN to generate information about the face. You can read the full research paper behind DeepPrivacy here.
And below are a couple of in-depth articles to help you get acquainted with GANs:
- Introductory Guide to Generative Adversarial Networks (GANs) and their promise!
- Top 5 Interesting Applications of GANs for Every Machine Learning Enthusiast
Other Useful Data Science Projects
TubeMQ – Storing and Transmitting Big Data (Tencent)
I’ve always been fascinated with how the top tech behemoths store and extract their data. What does it feel like when your data operations scale up 10000x? This kind of information isn’t usually made fully public.

That’s why we should be grateful to Tencent for open sourcing their distributed messaging queue (MQ) system called TubeMQ. It’s been in use since 2013 so that’s almost seven years of data operations available to us!
TubeMQ focuses “on high-performance storage and transmission of massive data in big data scenarios”. The user guide provides a step-by-step explanation of how to leverage TubeMQ for your organization.
DeepCTR – Torch
Ever worked on a click-through rate (CTR) problem? It’s intriguing and complex at the same time and it definitely takes a lot to unravel it.
DeepCTR is an easy-to-use package of deep learning-based CTR models. It comes with multiple component layers that we can use to build our custom models. You can use any model you want with model.fit() and model.predict(). I can see the sklearn fans smiling!
The original DeepCTR project was in TensorFlow. Now TF is great but it isn’t to everyone’s taste. And that’s how this DeepCTR-Torch repository was born. It provides the entire original DeepCTR code in PyTorch.
Install it right now via pip:
pip install -U deepctr-torch
If you’re entirely new to click-through rate prediction, I suggest going through the below guide:
End Notes
I fully expect to see more NLP projects filling up these monthly articles. I started this series back in January 2018 and I’m amazed at where we are right now in all aspects of data science, especially NLP.
In comparison, progress in computer vision has stalled a little bit but that’s only because we’ve crossed a lot of obstacles to get to the current state. I’m sure we’re one or two major developments away from opening the floodgates.
Are there any projects you feel I should include in this article? Or did you find any of the above projects useful in your work? I would love to hear from you in the comments section below.
Senior Editor at Analytics Vidhya.Data visualization practitioner who loves reading and delving deeper into the data science and machine learning arts. Always looking for new ways to improve processes using ML and AI.







Thank you for your help really important information given keep sharing it
great piece Pranav...I read all the Analytics Vidya pieces I get ajit ajit balakrishnan (founder rediff.com)
Nice article keep it up like this in your future.I hope you do best afford and make future bright.