Overview
- Here are 6 challenging open-source data science projects to level up your data scientist skillset
- There are some intriguing data science projects, including how to put deep learning models into production and a different way to measure artificial intelligence, among others
- Each data science project comes with end-to-end code so you can download that and get started right now!
Introduction
When was the last time you took up a data science project outside your daily work? I’m certainly guilty of not doing this regularly. We tend to get caught up in our professional lives and slip up on the learning front.
That’s a step we simply cannot afford to miss! Data science is one of the fastest-growing industries right now thanks to the unprecedented rise in data and computational power. There’s no excuse to not know what the latest techniques and frameworks are in your space, whether than’s Natural Language Processing (NLP), computer vision, or something else.
And the best way to learn, practice and apply these state-of-the-art techniques is through data science projects.

This article is the perfect place for you to begin. I have put together six challenging yet powerful open source data science projects to help you hone and fine-tune your skillset. I have provided the end-to-end code as well for each project so you can download it right now and start working on your own machine!
This article is part of our monthly data science project series. We pick out the latest open source projects from GitHub and bring them straight to you. This is the 23rd edition of the series and we are grateful to our community for the overwhelming response that keeps this series going. Here’s the complete list of projects we have published this year so far:
Here are the 6 Data Science Projects We’ve Picked from GitHub (November Edition)

Open Source Deep Learning Projects
Kaolin – PyTorch Library for Accelerating 3D Deep Learning Research
I haven’t come across a lot of work on 3D deep learning. That’s why I found this GitHub repository quite fascinating. The possibilities of 3D deep learning are tantalizing and potentially unique. Think about it – 3D imaging, geospatial analysis, architecture, etc. – so many data points at play!
Kaolin is a PyTorch library that aims to accelerate the research in 3D deep learning. The PyTorch library provides efficient implementations of 3D modules for use in deep learning systems – something I’m sure all you industry veterans will appreciate.

We get a ton of functionality with Kaolin, including loading and preprocessing popular 3D datasets, evaluating and visualizing 3D results, among other things.
What I especially like about Kaolin is that the developers have curated multiple state-of-the-art deep learning architectures to help anyone get started with these projects. You can read more about Kaolin and how it works in the official research paper here.
And if you’re new to deep learning and PyTorch, don’t worry! Here are a few tutorials (and a course) to get you on your way:
- A Beginner-Friendly Guide to PyTorch and How it Works from Scratch
- Get Started with PyTorch – Learn How to Build Quick & Accurate Neural Networks (with 4 Case Studies!)
- Computer Vision using Deep Learning 2.0 Course
Production-Level Deep Learning
Putting your machine learning model into production is a challenging task most aspiring data scientists aren’t prepared for. The majority of courses don’t teach it. You won’t find a lot of articles and blogs about it. But knowing how to put your model into production is a key skill every organization wants a data scientist to possess.
Now take that up a notch for deep learning models. It is a tricky and challenging task. You’ve built a robust deep learning model, sure, but what’s next? How do you get that to the end user? How can you deploy a deep learning model?
That’s where this Production-Level Deep Learning project comes in. We need several different components to deploy a production-level deep learning system:

The GitHub repository I have linked above contains toolsets and frameworks along with a set of best practices deep learning experts follow. I really like the way each step in the full-stack deep learning pipeline is mapped and summarized succinctly. I’ll be referring back to it whenever I’m working on deploying deep learning models in the foreseeable future.
I recommend checking out the below articles to get a taste of data engineering and why even data scientists need to acquire this skill:
- Become a Data Engineer with this Comprehensive List of Resources
- Tutorial to deploy Machine Learning Models in Production as APIs (using Flask)
3D Ken Burns Implementation using PyTorch
Deep learning has made us all artists. No longer do we need expensive equipment to edit images and videos, computer vision and techniques like GANs bring creativity right to our doorstep.
“The Ken Burns effect is a type of panning and zooming effect used in video production from still imagery.”
Creating a Ken Burns effect manually is time-consuming and honestly quite complex. Existing methods require a lot of input images taken from multiple angles. Not ideal. So in this project, the developers have created “a framework that synthesizes the 3D Ken Burns effect from a single image, supporting both a fully automatic mode and an interactive mode with the user controlling the camera”.

And no surprise to see that the implementation is in PyTorch, is it? You need to get on board the PyTorch bandwagon now to harness its full potential and give your deep learning career a major boost.
Open Source Artificial Intelligence (AI), NLP and Other Data Science Projects
Plato – Tencent’s Graph Computing Framework
Graphs have become an important part of the machine learning lifecycle in recent times. They are an effective and efficient method of analyzing data, building recommendation systems, mining social networks, etc. In short – they are super useful.
In fact, we at Analytics Vidhya are big proponents of graphs and have a collection of useful articles you can read about here.
Plato is a framework for distributed graph computation and machine learning. It has been developed by the folks at Tencent and open-sourced recently. Plato is a state-of-the-art framework that comes with incredible computing power. While analyzing billions of nodes, Plato can reduce the computing time from days to minutes (that’s the power of graphs!).
So, instead of relying on several hundred servers, Plato can finish its tasks on as little as ten servers. Tencent is using Plato on the WeChat platform as well (for all you text savvy readers).
Here’s a comparison of Plato against Spark GraphX on the PageRank and LPA benchmarks:

You can read more Plato here. If you’re new to graphs and are wondering how they tie into data science, here’s an excellent article to help you out:
Transformers v2.2 – with 4 New NLP Models!
HuggingFace is the most active research group I’ve seen in the NLP space. They seem to come up with new releases and frameworks mere hours after the official developers announce them – it’s incredible. I would highly recommend following HuggingFace on Twitter to stay up-to-date with their work.
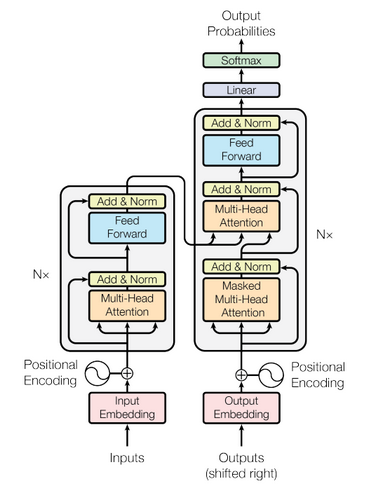
Their latest release is Transformers v2.2.0 that includes four new NLP models (among other new features):
- ALBERT (PyTorch and TensorFlow): A Lite version of BERT
- CamamBERT (PyTorch): A French Language Model
- GPT2-XL (PyTorch and TensorFlow): A GPT-2 iteration by OpenAI
- DistilRoberta (PyTorch and TensorFlow)
As always, we have the tutorials for the latest state-of-the-art NLP frameworks:
- How do Transformers Work in NLP?
- Demystifying BERT: A Comprehensive Guide to the Ground-Breaking NLP Framework
- OpenAI’s GPT-2: A Simple Guide to Build the World’s Most Advanced Text Generator in Python
ARC – Abstraction and Reasoning Corpus (AI Benchmark)
This is a slightly different project from what I typically include in these articles. But I feel it’s an important one given how far away we still are from even getting close to artificial general intelligence.
ARC, short for Abstraction and Reasoning Corpus, is an artificial general intelligence benchmark that aims to emulate a “human-like form of general fluid intelligence”. This idea and the research behind it has been done by François Chollet, the author of the popular Keras framework.

Mr. Chollet, in his research paper titled “On the Measure of Intelligence“, provides an updated definition of intelligence based on Algorithmic Information Theory. He also proposes a new set of guidelines to showcase what a general AI benchmark should be. And the ARC is that benchmark based on these guidelines.
I think its a really important topic that will spur a lot of debate in the community. That’s a healthy thing and will hopefully lead to even more research on the topic and perhaps a big step forward in the artificial general intelligence space.
This GitHub repository contains the ARC dataset along with a browser-based interface to try solving the tasks manually. I’ve mentioned a couple of resources below to help you understand what AI is and how it works:
End Notes
So, which open source project did you find the most relevant? I have tried to diversify the topics and domains as much as possible to help you expand your horizons. I have seen our community embrace the deep learning projects with the enthusiasm of a truly passionate learner – and I hope this month’s collection will help you out further.
Personally, I will be digging deeper into François Chollet’s paper on measuring intelligence as that has really caught my eye. It’s rare that we get to openly read about benchmarking artificial general intelligence systems, right?
I would love to hear from you – let me know your ideas, thoughts, and feedback in the comments section below. Also, just wanted to reiterate the key links I have mentioned throughout the article:
- Applied Machine Learning – Beginner to Professional
- Natural Language Processing (NLP) using Python
- Computer Vision using Deep Learning 2.0
Senior Editor at Analytics Vidhya.Data visualization practitioner who loves reading and delving deeper into the data science and machine learning arts. Always looking for new ways to improve processes using ML and AI.







I would like to know more about the projects which are must to go through for data scientists
Good projects to practice, can i have projects on tensow flow related please
This is really interesting, thanks for taking the time to put this together @pranav.