Overview
- Recommendation engines are ubiquitous nowadays and data scientists are expected to know how to build one
- Word2vec is an ultra-popular word embeddings used for performing a variety of NLP tasks
- We will use word2vec to build our own recommendation system. Curious how NLP and recommendation engines combine? Let’s find out!
Introduction
Be honest – how many times have you used the ‘Recommended for you’ section on Amazon? Ever since I found out a few years back that machine learning powers this section – I have been hooked. I keep an eye on that section each time I log into Amazon.
There’s a reason companies like Netflix, Google, Amazon, Flipkart, etc. spend millions perfecting their recommendation engine. It is a powerful acquisition channel and enhances the customer’s experience.
Let me use a recent example to showcase their power. I went to a popular online marketplace looking for a recliner. There were hundreds of them. From Traditional two-position recliners to Push-Back Liners; from Power Lift Recliner to the Wall Hugger one. I liked most of them and I clicked on a leatherette manual recliner:

Notice the different kinds of information presented on this page. The left half of the image contains the pictures of the product from different angles. The right half contains a few details about the product and a section of similar products.
This is my favorite part of the image. The website is recommending me similar products and it saves me the effort to manually go and browse similar armchairs.
In this article, we are going to build our own recommendation system. But we’ll approach this from a unique perspective. We will use Word2vec, an NLP concept, to recommend products to users. It’s a very exciting tutorial so let’s dive straight in.
I have covered a few concepts in this article that you should be aware of. I recommend taking a look at these two articles to get a quick refresher:
- Understanding and coding Neural Networks From Scratch in Python and R
- Comprehensive Guide to building a Recommendation Engine from scratch (in Python)
Table of Contents
- Introduction to word2vec – Vector Representation of Words
- How are word2vec Embeddings Obtained?
- Training Data Preparation
- Obtaining word2vec Embeddings
- Applying word2vec Model on Non-Textual Data
- Case Study: Using word2vec for Online Product Recommendation
Introduction to word2vec – Vector Representation of Words
We know that machines struggle to deal with raw text data. In fact, it’s almost impossible for machines to deal with anything except for numerical data. So representing text in the form of vectors has always been the most important step in almost all NLP tasks.
One of the most significant steps in this direction has been the use of word2vec embeddings, introduced to the NLP community in 2013. It completely changed the entire landscape of NLP.
These embeddings proved to be state-of-the-art for tasks like word analogies and word similarities. word2vec embeddings were also able to achieve tasks like King – man +woman ~= Queen, which was considered an almost magical result.
Now, there are two variants of a word2vec model — Continuous Bag of Words and Skip-Gram model. In this article, we will use the Skip-Gram model.
Let’s first understand how word2vec vectors or embeddings are calculated.
How are word2vec Embeddings Obtained?
A word2vec model is a simple neural network model with a single hidden layer. The task of this model is to predict the nearby words for each and every word in a sentence. However, our objective has nothing to with this task. All we want are the weights learned by the hidden layer of the model once the model is trained. These weights can then be used as the word embeddings.
Let me give you an example to understand how a word2vec model works. Consider the sentence below:

Let’s say the word “teleport” (highlighted in yellow) is our input word. It has a context window of size 2. This means we are considering only the 2 adjacent words on either side of the input word as the nearby words.
Note: The size of the context window is not fixed, it can be changed as per our requirement.
Now, the task is to pick the nearby words (words in the context window) one-by-one and find the probability of every word in the vocabulary of being the selected nearby word. Sounds straightforward, right?
Let’s take another example to understand the entire process in detail.
Training Data Preparation
We need a labeled dataset to train a neural network model. This means the dataset should have a set of inputs and an output for every input. You might have a few pressing questions at this point:
- Where to find such dataset?
- What does this dataset contain?
- How big is this data? etc.
Well – I have good news for you! We can easily create our own labeled data to train a word2vec model. Below I will illustrate how to generate this dataset from any text. Let’s use a sentence and create training data from it.
Step 1: The yellow highlighted word will be our input and the words highlighted in green are going to be the output words. We will use a window size of 2 words. Let’s start with the first word as the input word.

So, the training samples with respect to this input word will be as follows:
| Input | Output |
| we | must |
| we | become |
Step 2: Next, we will take the second word as the input word. The context window will also shift along with it. Now, the nearby words are “we”, “become”, and “what”.

The new training samples will get appended to the previous ones as given below:
| Input | Output |
| we | must |
| we | become |
| must | we |
| must | become |
| must | what |
We will continue with these steps until the last word of the sentence. In the end, the complete training data from this sentence will look like this:
| Input | Output |
| we | must |
| we | become |
| must | we |
| must | become |
| must | what |
| become | we |
| become | must |
| become | what |
| become | we |
| what | must |
| what | become |
| what | we |
| what | wish |
| we | become |
| we | what |
| we | wish |
| we | to |
| wish | what |
| wish | we |
| wish | to |
| wish | teach |
| to | we |
| to | wish |
| to | teach |
| teach | wish |
| teach | to |
We have extracted 27 training samples out of a single sentence. Got to love it! This is one of the many things that I like about working with unstructured data – creating a labeled dataset out of thin air.
Obtaining word2vec Embeddings
Now, let’s say we have a bunch of sentences and we extract training samples from them in the same manner. We will end up with training data of considerable size.
Suppose the number of unique words in this dataset is 5,000 and we wish to create word vectors of size 100 each. Then, with respect to the word2vec architecture given below:
- V = 5000 (size of vocabulary)
- N = 100 (number of hidden units or length of word embeddings)
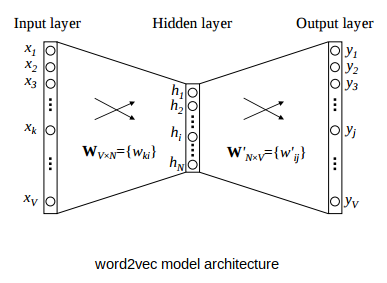
The inputs would be the one-hot-encoded vectors and the output layer would give the probability of being the nearby word for every word in the vocabulary.

Once this model is trained, we can easily extract the learned weight matrix WV x N and use it to extract the word vectors:

As you can see above, the weight matrix has a shape of 5000 x 100. The first row of this matrix corresponds to the first word in the vocabulary, the second to the second, and so on.
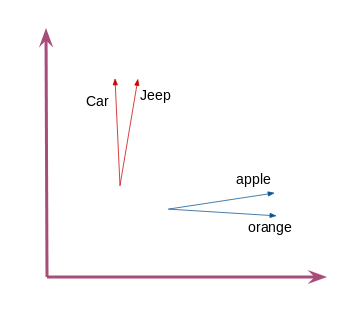
That is how we get the fixed size word vectors or embeddings by word2vec. Similar words in this dataset would have similar vectors, i.e. vectors pointing towards the same direction. For example, the terms “car” and “jeep” would have similar vectors as these words:
This was a high-level overview of how word2vec is used in NLP.
Before we proceed to the implementation part – let me ask you a question. How can we use word2vec for a non-NLP task such as product recommendation? I’m sure you’ve been wondering that since you read this article’s topic. So let’s finally solve the puzzle.
Applying word2vec Model on Non-Textual Data
Can you guess the fundamental property of a natural language that word2vec exploits to create vector representations of text?
It is the sequential nature of the text. Every sentence or phrase has a sequence of words. In the absence of this sequence, we would have a hard time understanding the text. Just try to interpret the sentence below:
“these most been languages deciphered written of have already”
There is no sequence in this sentence. It becomes difficult for us to grasp it and that’s why the sequence of words is so important in any natural language. This very property got me thinking about data other than text that has a sequential nature as well.
One such data is the purchases made by the consumers on E-commerce websites. Most of the time there is a pattern in the buying behavior of the consumers. For example, a person involved in sports-related activities might have an online buying pattern similar to this:
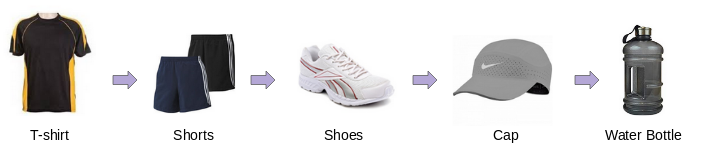
Purchase history of the consumer
If we can represent each of these products by a vector, then we can easily find similar products. So, if a user is checking out a product online, then we can easily recommend him/her similar products by using the vector similarity score between the products.
But how do we get a vector representation of these products? Can we use the word2vec model to get these vectors?
We surely can! Just imagine the buying history of a consumer as a sentence and the products as its words:

Taking this idea further, let’s work on online retail data and build a recommendation system using word2vec embeddings.
Case Study: Using word2vec in Python for Online Product Recommendation
Let’s set up and understand our problem statement.
We are asked to create a system that automatically recommends a certain number of products to the consumers on an E-commerce website based on the past purchase behavior of the consumers.
We are going to use an Online Retail Dataset that you can download from this link.
Let’s fire up our Jupyter Notebook and quickly import the required libraries and load the dataset.
Python Code:
import pandas as pd
import numpy as np
import random
from tqdm import tqdm
from gensim.models import Word2Vec
import matplotlib.pyplot as plt
#%matplotlib inline
import warnings;
warnings.filterwarnings('ignore')
df = pd.read_excel('Online Retail.xlsx')
print(df.head())
Here is the description of the fields in this dataset:
- InvoiceNo: Invoice number. a unique number assigned to each transaction
- StockCode: Product/item code. a unique number assigned to each distinct product
- Description: Product description
- Quantity: The quantities of each product per transaction
- InvoiceDate: Invoice Date and time. The day and time when each transaction was generated
- CustomerID: Customer number. a unique number assigned to each customer
df.shape
Output: (541909, 8)
The dataset contains 541,909 transactions. That is a pretty good number for us to build our model.
Treat Missing Data
# check for missing values df.isnull().sum()

Since we have sufficient data, we will drop all the rows with missing values.
# remove missing values df.dropna(inplace=True)
Data Preparation
Let’s convert the StockCode to string datatype:
df['StockCode']= df['StockCode'].astype(str)
Let’s check out the number of unique customers in our dataset:
customers = df["CustomerID"].unique().tolist() len(customers)
Output: 4372
There are 4,372 customers in our dataset. For each of these customers, we will extract their buying history. In other words, we can have 4,372 sequences of purchases.
It is a good practice to set aside a small part of the dataset for validation purposes. Therefore, I will use the data of 90% of the customers to create word2vec embeddings. Let’s split the data.
We will create sequences of purchases made by the customers in the dataset for both the train and validation set.
Build word2vec Embeddings for Products
Since we are not planning to train the model any further, we are calling init_sims( ) here. This will make the model much more memory-efficient:
model.init_sims(replace=True)
Let’s check out the summary of “model”:
print(model)
Output: Word2Vec(vocab=3151, size=100, alpha=0.03)
Our model has a vocabulary of 3,151 unique words and their vectors of size 100 each. Next, we will extract the vectors of all the words in our vocabulary and store it in one place for easy access.
Output: (3151, 100)
Visualize word2vec Embeddings
It is always quite helpful to visualize the embeddings that you have created. Over here, we have 100-dimensional embeddings. We can’t even visualize 4 dimensions let alone 100. What in the world can we do?
We are going to reduce the dimensions of the product embeddings from 100 to 2 by using the UMAP algorithm. It is popularly used for dimensionality reduction.

Every dot in this plot is a product. As you can see, there are several tiny clusters of these data points. These are groups of similar products.
Start Recommending Products
Congratulations! We are finally ready with the word2vec embeddings for every product in our online retail dataset. Now, our next step is to suggest similar products for a certain product or a product’s vector.
Let’s first create a product-ID and product-description dictionary to easily map a product’s description to its ID and vice versa.
# test the dictionary products_dict['84029E']
Output: [‘RED WOOLLY HOTTIE WHITE HEART.’]
I have defined the function below. It will take a product’s vector (n) as input and return top 6 similar products:
Let’s try out our function by passing the vector of the product ‘90019A’ (‘SILVER M.O.P ORBIT BRACELET’):
similar_products(model['90019A'])
Output:
[(‘SILVER M.O.P ORBIT DROP EARRINGS’, 0.766798734664917),
(‘PINK HEART OF GLASS BRACELET’, 0.7607438564300537),
(‘AMBER DROP EARRINGS W LONG BEADS’, 0.7573930025100708),
(‘GOLD/M.O.P PENDANT ORBIT NECKLACE’, 0.7413625121116638),
(‘ANT COPPER RED BOUDICCA BRACELET’, 0.7289256453514099),
(‘WHITE VINT ART DECO CRYSTAL NECKLAC’, 0.7265784740447998)]
Cool! The results are pretty relevant and match well with the input product. However, this output is based on the vector of a single product only. What if we want to recommend products based on the multiple purchases he or she has made in the past?
One simple solution is to take the average of all the vectors of the products the user has bought so far and use this resultant vector to find similar products. We will use the function below that takes in a list of product IDs and gives out a 100-dimensional vector which is a mean of vectors of the products in the input list:
Recall that we have already created a separate list of purchase sequences for validation purposes. Now let’s make use of that.
len(purchases_val[0])
Output: 314
The length of the first list of products purchased by a user is 314. We will pass this products’ sequence of the validation set to the function aggregate_vectors.
aggregate_vectors(purchases_val[0]).shape
Output: (100, )
Well, the function has returned an array of 100 dimensions. It means the function is working fine. Now we can use this result to get the most similar products:
similar_products(aggregate_vectors(purchases_val[0]))
Output:
[(‘PARTY BUNTING’, 0.661663293838501),
(‘ALARM CLOCK BAKELIKE RED ‘, 0.640213131904602),
(‘ALARM CLOCK BAKELIKE IVORY’, 0.6287959814071655),
(‘ROSES REGENCY TEACUP AND SAUCER ‘, 0.6286610960960388),
(‘SPOTTY BUNTING’, 0.6270893216133118),
(‘GREEN REGENCY TEACUP AND SAUCER’, 0.6261675357818604)]
(‘ALARM CLOCK BAKELIKE RED ‘, 0.640213131904602),
(‘ALARM CLOCK BAKELIKE IVORY’, 0.6287959814071655),
(‘ROSES REGENCY TEACUP AND SAUCER ‘, 0.6286610960960388),
(‘SPOTTY BUNTING’, 0.6270893216133118),
(‘GREEN REGENCY TEACUP AND SAUCER’, 0.6261675357818604)]
As it turns out, our system has recommended 6 products based on the entire purchase history of a user. Moreover, if you want to get product suggestions based on the last few purchases, only then also you can use the same set of functions.
Below I am giving only the last 10 products purchased as input:
similar_products(aggregate_vectors(purchases_val[0][-10:]))
Output:
[(‘PARISIENNE KEY CABINET ‘, 0.6296610832214355),
(‘FRENCH ENAMEL CANDLEHOLDER’, 0.6204789876937866),
(‘VINTAGE ZINC WATERING CAN’, 0.5855435729026794),
(‘CREAM HANGING HEART T-LIGHT HOLDER’, 0.5839680433273315),
(‘ENAMEL FLOWER JUG CREAM’, 0.5806118845939636)]
Feel free to play around this code and try to get product recommendations for more sequences from the validation set. I would be thrilled if you can further optimize this code or make it better.
Full code is available here.
End Notes
I had a great time writing this article and sharing my experience of working with word2vec for making product recommendations. You can try to implement this code on similar non-textual sequence data. Music recommendation can be a good use case, for example.
This experiment has inspired me to try other NLP techniques and algorithms to solve more non-NLP tasks. Feel free to use the comments section below if you have any doubts or want to share your feedback.
Data Scientist at Analytics Vidhya with multidisciplinary academic background. Experienced in machine learning, NLP, graphs & networks. Passionate about learning and applying data science to solve real world problems.





Hello. Great work indeed! I have one concern though. Purchases with the same products, but in different order should be turned into the same vectors since they are identical baskets after all. In your case, you consider them different. Do you think that this might be a issue?
thanks for this very well presented article.
After extracting the word vectors # extract all vectors X = model[model.wv.vocab] X.shape It is visualised using the UMAP. How it is used in the product recommendations ? How the X vectors are used in the products ? products = train_df[["StockCode", "Description"]] # remove duplicates products.drop_duplicates(inplace=True, subset='StockCode', keep="last") # create product-ID and product-description dictionary products_dict = products.groupby('StockCode')['Description'].apply(list).to_dict()