Knowledge Graph: Data Science Technique to Mine Information from Text (with Python code)
Introduction
Examine doable tactics for reducing tension, increasing self-assurance, and cultivating wholesome relationships. Discover how to employ continuous learning, mindfulness, goal-setting, and knowledge graph python to help you reach your objectives. Whether your objective is greater purpose, job success, or emotional stability, this invaluable book will provide you the tools you need to overcome challenges. Prepare to welcome change, realize your full potential, and design the life you really want. This is where the journey to change starts.
Table of contents
What is a Knowledge Graph?
Let’s clarify something upfront – in this article, we’ll discuss “graphs” a lot. But we’re not referring to bar charts or pie charts. Instead, we’re diving into interconnected entities like people, locations, and organizations to build a knowledge graph python. This method involves Knowledge graph machine learning techniques and Python.

We can define a graph as a set of nodes and edges.
Take a look at the figure below:

Node A and Node B here are two different entities. These nodes are connected by an edge that represents the relationship between the two nodes. Now, this is the smallest knowledge graph python we can build – it is also known as a triple.
Knowledge Graph’s come in a variety of shapes and sizes. For example, the knowledge graph of Wikidata had 59,910,568 nodes by October 2019.
How to Represent Knowledge in a Graph?
Before we get started with building knowledge graph python, it is important to understand how information or knowledge is embedded in these graphs.
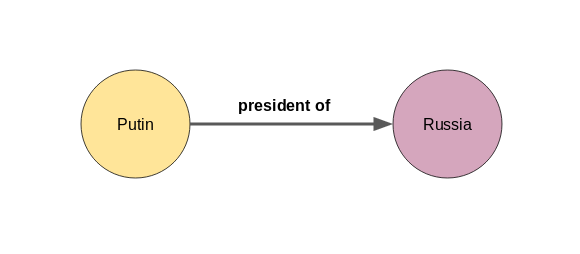
Let me explain this using an example. If Node A = Putin and Node B = Russia, then it is quite likely that the edge would be “president of”:
A node or an entity can have multiple relations as well. Putin is not only the President of Russia, he also worked for the Soviet Union’s security agency, KGB. But how do we incorporate this new information about Putin in the knowledge graph python above?
It’s actually pretty simple. Just add one more node for the new entity, KGB:
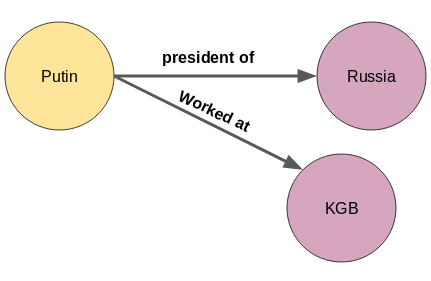
The new relationships can emerge not only from the first node but from any node in a knowledge graph as shown below:

Russia is a member of the Asia Pacific Economic Cooperation (APEC).
Identifying the entities and the relation between them is not a difficult task for us. However, manually building a knowledge graph is not scalable. Nobody is going to go through thousands of documents and extract all the entities and the relations between them!
That’s why machines are more suitable to perform this task as going through even hundreds or thousands of documents is child’s play for them. But then there is another challenge – machines do not understand natural language. This is where Natural Language Processing (NLP) comes into the picture.
To build a knowledge graph Python from the text, it is important to make our machine understand natural language. This can be done by using NLP techniques such as sentence segmentation, dependency parsing, parts of speech tagging, and entity recognition. Let’s discuss these in a bit more detail.
Sentence Segmentation
The first step in building a knowledge graph python is to split the text document or article into sentences. Then, we will shortlist only those sentences in which there is exactly 1 subject and 1 object. Let’s look at a sample text below:
“Indian tennis player Sumit Nagal moved up six places from 135 to a career-best 129 in the latest men’s singles ranking. The 22-year-old recently won the ATP Challenger tournament. He made his Grand Slam debut against Federer in the 2019 US Open. Nagal won the first set.”
Let’s split the paragraph above into sentences:
- Indian tennis player Sumit Nagal moved up six places from 135 to a career-best 129 in the latest men’s singles ranking
- The 22-year-old recently won the ATP Challenger tournament
- He made his Grand Slam debut against Federer in the 2019 US Open
- Nagal won the first set
Out of these four sentences, we will shortlist the second and the fourth sentences because each of them contains 1 subject and 1 object. In the second sentence, “22-year-old” is the subject and the object is “ATP Challenger tournament”. In the fourth sentence, the subject is “Nagal” and “first set” is the object:

The challenge is to make your machine understand the text, especially in the cases of multi-word objects and subjects. For example, extracting the objects in both the sentences above is a bit tricky. Can you think of any method to solve this problem?
Entities Extraction
The extraction of a single word entity from a sentence is not a tough task. We can easily do this with the help of parts of speech (POS) tags. The nouns and the proper nouns would be our entities.
However, when an entity spans across multiple words, then POS tags alone are not sufficient. We need to parse the dependency tree of the sentence. You can read more about dependency parsing in the following article.
Let’s get the dependency tags for one of the shortlisted sentences. I will use the popular spaCy library for this task:
Python Code:
Output:
The ... det
22-year ... amod
- ... punct
old ... nsubj
recently ... advmod
won ... ROOT
ATP ... compound
Challenger ... compound
tournament ... dobj
. ... punctThe subject (nsubj) in this sentence as per the dependency parser is “old”. That is not the desired entity. We wanted to extract “22-year-old” instead.
The dependency tag of “22-year” is amod which means it is a modifier of “old”. Hence, we should define a rule to extract such entities.
The rule can be something like this — extract the subject/object along with its modifiers and also extract the punctuation marks between them.
But then look at the object (dobj) in the sentence. It is just “tournament” instead of “ATP Challenger tournament”. Here, we don’t have the modifiers but compound words.
Compound words are those words that collectively form a new term with a different meaning. Therefore, we can update the above rule to — extract the subject/object along with its modifiers, compound words and also extract the punctuation marks between them.
In short, we will use dependency parsing to extract entities.
Extract Relations
Entity extraction is half the job done. To build a knowledge graph, we need edges to connect the nodes (entities) to one another. These edges are the relations between a pair of nodes.
Let’s go back to the example in the last section. We shortlisted a couple of sentences to build a knowledge graph python:

Can you guess the relation between the subject and the object in these two sentences?
Both sentences have the same relation – “won”. Let’s see how these relations can be extracted. We will again use dependency parsing:
Output:
Nagal ... nsubj
won ... ROOT
the ... det
first ... amod
set ... dobj
. ... punctTo extract the relation, we have to find the ROOT of the sentence (which is also the verb of the sentence). Hence, the relation extracted from this sentence would be “won”.
Finally, the knowledge graph from these two sentences will be like this:

Build a Knowledge Graph from Text Data
Time to get our hands on some code! Let’s fire up our Jupyter Notebooks (or whatever IDE you prefer).
We will build a knowledge graph from scratch by using the text from a set of movies and films related to Wikipedia articles. I have already extracted around 4,300 sentences from over 500 Wikipedia articles. Each of these sentences contains exactly two entities – one subject and one object. You can download these sentences from here.
I suggest using Google Colab for this implementation to speed up the computation time.
Import Libraries
Read Data
Read the CSV file containing the Wikipedia sentences:
Output: (4318, 1)
Let’s inspect a few sample sentences:
candidate_sentences['sentence'].sample(5)
Output:

Let’s check the subject and object of one of these sentences. Ideally, there should be one subject and one object in the sentence:
Output:

Perfect! There is only one subject (‘process’) and only one object (‘standard’). You can check for other sentences in a similar manner.
Entity Pairs Extraction
To build a knowledge graph, the most important things are the nodes and the edges between them.
These nodes are going to be the entities that are present in the Wikipedia sentences. Edges are the relationships connecting these entities to one another. We will extract these elements in an unsupervised manner, i.e., we will use the grammar of the sentences.
The main idea is to go through a sentence and extract the subject and the object as and when they are encountered. However, there are a few challenges — an entity can span across multiple words, eg., “red wine”, and the dependency parsers tag only the individual words as subjects or objects.
So, I have created a function below to extract the subject and the object (entities) from a sentence while also overcoming the challenges mentioned above. I have partitioned the code into multiple chunks for your convenience:
Let me explain the code chunks in the function above:
Chunk 1
I have defined a few empty variables in this chunk. prv_tok_dep and prv_tok_text will hold the dependency tag of the previous word in the sentence and that previous word itself, respectively. prefix and modifier will hold the text that is associated with the subject or the object.
Chunk 2
Next, we will loop through the tokens in the sentence. We will first check if the token is a punctuation mark or not. If yes, then we will ignore it and move on to the next token. If the token is a part of a compound word (dependency tag = “compound”), we will keep it in the prefix variable. A compound word is a combination of multiple words linked to form a word with a new meaning (example – “Football Stadium”, “animal lover”).
As and when we come across a subject or an object in the sentence, we will add this prefix to it. We will do the same thing with the modifier words, such as “nice shirt”, “big house”, etc.
Chunk 3
Here, if the token is the subject, then it will be captured as the first entity in the ent1 variable. Variables such as prefix, modifier, prv_tok_dep, and prv_tok_text will be reset.
Chunk 4
Here, if the token is the object, then it will be captured as the second entity in the ent2 variable. Variables such as prefix, modifier, prv_tok_dep, and prv_tok_text will again be reset.
Chunk 5
Once we have captured the subject and the object in the sentence, we will update the previous token and its dependency tag.
Let’s test this function on a sentence:
get_entities("the film had 200 patents")
Output: [‘film’, ‘200 patents’]
Great, it seems to be working as planned. In the above sentence, ‘film’ is the subject and ‘200 patents’ is the object.
Now we can use this function to extract these entity pairs for all the sentences in our data:
The list entity_pairs contains all the subject-object pairs from the Wikipedia sentences. Let’s have a look at a few of them:
entity_pairs[10:20]
Output:

As you can see, there are a few pronouns in these entity pairs such as ‘we’, ‘it’, ‘she’, etc. We’d like to have proper nouns or nouns instead. Perhaps we can further improve the get_entities( ) function to filter out pronouns. For the time being, let’s leave it as it is and move on to the relation extraction part.
Relation / Predicate Extraction
This is going to be a very interesting aspect of this article. Our hypothesis is that the predicate is actually the main verb in a sentence.
For example, in the sentence – “Sixty Hollywood musicals were released in 1929”, the verb is “released in” and this is what we are going to use as the predicate for the triple generated from this sentence.
The function below is capable of capturing such predicates from the sentences. Here, I have used spaCy’s rule-based matching:
The pattern defined in the function tries to find the ROOT word or the main verb in the sentence. Once the ROOT is identified, then the pattern checks whether it is followed by a preposition (‘prep’) or an agent word. If yes, then it is added to the ROOT word.
Let me show you a glimpse of this function:
get_relation("John completed the task")Output: completed
Similarly, let’s get the relations from all the Wikipedia sentences:
relations = [get_relation(i) for i in tqdm(candidate_sentences['sentence'])]Let’s take a look at the most frequent relations or predicates that we have just extracted:
pd.Series(relations).value_counts()[:50]Output:

It turns out that relations like “A is B” and “A was B” are the most common relations. However, there are quite a few relations that are more associated with the overall theme – “the ecosystem around movies”. Some of the examples are “composed by”, “released in”, “produced”, “written by” and a few more.
Build a Knowledge Graph
We will finally create a knowledge graph from the extracted entities (subject-object pairs) and the predicates (relation between entities).
Let’s create a dataframe of entities and predicates:
Next, we will use the networkx library to create a network from this dataframe. The nodes will represent the entities and the edges or connections between the nodes will represent the relations between the nodes.
It is going to be a directed graph. In other words, the relation between any connected node pair is not two-way, it is only from one node to another. For example, “John eats pasta”:
Let’s plot the network:
Output:

Well, this is not exactly what we were hoping for (still looks quite a sight though!).
It turns out that we have created a graph with all the relations that we had. It becomes really hard to visualize a graph with these many relations or predicates.
So, it’s advisable to use only a few important relations to visualize a graph. I will take one relation at a time. Let’s start with the relation “composed by”:

Output:
That’s a much cleaner graph. Here the arrows point towards the composers. For instance, A.R. Rahman, who is a renowned music composer, has entities like “soundtrack score”, “film score”, and “music” connected to him in the graph above.
Let’s check out a few more relations.
Since writing is an important role in any movie, I would like to visualize the graph for the “written by” relation:

Output:
Awesome! This knowledge graph machine learning is giving us some extraordinary information. Guys like Javed Akhtar, Krishna Chaitanya, and Jaideep Sahni are all famous lyricists and this graph beautifully captures this relationship.
Let’s see the knowledge graph of another important predicate, i.e., the “released in”:

Output:
I can see quite a few interesting information in this graph. For example, look at this relationship – “several action horror movies released in the 1980s” and “pk released on 4844 screens”. These are facts and it shows us that we can mine such facts from just text. That’s quite amazing!
Conclusion
In this article, we talked about how to take information from text and make a knowledge graph. Even though we only used sentences with two things, we made graphs that had a lot of helpful info. There’s so much more we can do with knowledge graphs in machine learning! Try exploring more to find out. Share your thoughts below in the comments!
Frequently Asked Questions
Knowledge graphs in machine learning are like big networks that connect different pieces of information. They help us organize and understand data better.
Knowledge graphs help solve machine learning problems by showing relationships between different pieces of information. This makes it easier for computers to learn and make decisions.
Yes, knowledge graphs are part of natural language processing (NLP). They help computers understand language better by connecting words and concepts.
The function of a knowledge graph is to organize and connect information so that computers can understand and use it effectively. It’s like a big map that helps us navigate through data and make sense of it.
Data Scientist at Analytics Vidhya with multidisciplinary academic background. Experienced in machine learning, NLP, graphs & networks. Passionate about learning and applying data science to solve real world problems.








Great Article, this is a very good place to start Knowledge Graph, apart from that , information on nsubj, compound, amod was brilliant.
Thanks Sahil for the feedback.
Thanks for such a good article. I was wondering if there is a way for extracting the CEO relation from the following sentence: "Mark Zuckerberg is the CEO of Facebook".
Hi Abhishek, You can easily extract such relations. All you have to do is to find the sentences with the term 'CEO' and then extract subjects and objects from those sentences. Give it a try.
Hi Prateek, Thanks for the excellent article. There are really very few articles on knowledge graphs on the web, so yours is really a big help to us. You have used various NLP methods to arrive at triples and formed the graph. So the graph now is like an end product (BI product) from which we could read off existing relationships. Btw, have you heard about knowledge graph embeddings and if so what is your take on them. I think they represent the next step or evolution of these knowledge bases (trained using large wikidata datasets similar to word embeddings), where you can query about the probability of unexisting relationships. It'll be real cool if you could cover them in a future series as well. Thanks
Hi Hanifa, Thanks for appreciating. Graph Embeddings are basically features that can be fed to a Machine Learning model. Using these embeddings we can solve problems like node classification or edge (relation) classification. I will definitely cover it in my upcoming articles. Regards, Prateek
nice one, very introductory
Hi, very interesting read! Small correction: get_relation("John completed the task") instead of get_entities("John completed the task")
Thanks Nathan! I have made the correction.
Hi , Good Morning Brother, thank you share the knowledge. its really helpfull for me. can i get your whats app number.
Article is very nice but I found the trouble in parsing csv files , I am running my code on colab and it is asking me to the input csv file.If you will provide the CSV file set for practice then it would add more value to the article.
Hi Prankur, I have given the download link for the csv file under "Build a Knowledge Graph from Text Data". Please check.
Thanks Prateek, I am also working on same type use case but used Stanford library.
Hello Prateek, Just afer the Entity Pairs Extraction title, you explain that for the chunk 4: "Here, if the token is the object, then it will be captured as the second entity in the ent2 variable. Variables such as prefix, modifier, prv_tok_dep, and prv_tok_text will again be reset." However, in your code, there is not these 4 lines like for chunk 3: prefix = "" modifier = "" prv_tok_dep = "" prv_tok_text = "" Is it a mistake in your code ?
This article about Knowledge Graph is commendable. I didn't find any other one so useful and precise. Every piece of information is structured and consumable. Thanks for this awesome article Prateek Ji. Hope in upcoming days we will read some good application of BERT.
Thanks for the kind words Smrutiranjan.
Great post, thanks!! Have you heard about Flair?? Do you think I could do something similar with that library??
Good stuff as usual! I'd love to see an article from Analytics Vidhya showing how to construct a KnowledgeBase and train/use an EntityLinker in spacy. The documentation for these is not very helpful unfortunately and I haven't found any tutorials online.
Hi Prateek, Thanks for nice article. I have few questions, can you check once and reply please. 1. How to chose only some sentences, on which basis you have been selected around 4,300 sentences from over 500 Wikipedia articles. And am also trying similar concept in closed domain and not sure suppose need to select few sentences in the PDF documents. 2. I think it's not practically possible every sentence has only one subject and object, if it occurs will you ignore that sentence currently and any future plans to enhance it. 3. I guess, in this article we are using some rules at get_entities and get_relation will it support all cases or we need to fine tune them. 4. I have executed same code snippets but my Knowledge graphs are varied every-time and may i know how to fix it in similar to yours and also how to integrate this concept to chatbot. Thanks
Hey, so i am supposed to create a knowledge graph from some slides. i have to mine from text and images in those slides. i want my slides to be node of KG and then show dependencies in different slides . can anyone tell me how to proceed .
Article triggered some possible use cases that i can explore at my work. Thanks for triggering the thought process Prateek.
Hi, Good work! Nice article. Can i expect an article that talks about various graph databases & how to query a graph? ~Kannan
Thanks a lot!
Great article. How do you annotate the edge names using the same nx structure? Greately appreciate your input. Luiz
Is your code MIT License?
Yes, feel free to use it.
Sir, this was an excellent knowledge that you shared with us. I have been looking at the knowledge graph for months. This was the best to start. I have a question about if we take a data set from a graph database, wouldn't it be easy to create a knowledge graph??
i have question can i use knowldege graph for prediction missing values in data base
Really wonderful.
in the example "Nagal" and "22-year-old" is same entity. How can I show them in one Node?
Hi, Prateek Joshi, you did really amazing job, Had you published any online article on knowledge graph completion yet?
Thanks Usman! I have published an article on graph embeddings. You can find it here.
Hi sir, its a wonderful article, I am studying in China and doing a master's in CS.i want to submit my thesis on the Knowledge Graph. please suggest me some new ideas. It would be great and helpful for me.
Hey! I have a doubt. Once the knowledge graph is constructed. How can we do the querying operation over it? Like for example how to query from the KG using python? I am trying to build a question answering system using knowledge graphs. So once the paragraphs are put in the knowledge graphs... How will I query for a question from the knowledge graph? Please helppppppppp
Hi, for querying the knowledge graph, you can use the similar approach. A question would have a relationship and it will also have either object or subject. Let's say that the object is not present in the question, then you can use the subject and the relationship, from the question, to find the triples with the same subject-relationship pair.
Sir, Where I can get full code of this blog
Can I get full code
Hi, you can use the same code from the article. It should work.
Hi, Among thousands of articles, how could you determine the important relations/predicates to simplify the graph? thanks.
Hi, It seems that the dataset is now not available. Can someone please check and confirm?
Hi Ishdutt, Thanks for letting me know. I have updated the link.
How to show the relationship between them using networkx. like "Putin"------------(president of)--------------'Rusia' Can you please help me on this ?
Hi Prateek, Thanks for this great article. I wanted to use this KG for recommending items for one of my projects. Is it possible? If yes what steps should I follow?
Hello, Prateek! Thank you for the amazing article and work done! There really is no much material on KG there on the internet. I have wondered how have you created the dataset, i.e. how have you extracted around 4,300 sentences from over 500 Wikipedia articles? Is there a code for that and how is the code constructed? It is impossible to do it manually, right?
Hello, Prateek! Thanks for the great article, I really enjoyed it a lot! I wondered how did you come up with the dataset? You said you have constructed it yourself? Did you do it manually or use some technique? I want to construct a dataset like yours from Wikipedia, can you guide me how to do that?
Hi, Great article. I have a question though, how can i include the relations among the nodes on the graph itself as well?
When running following code: get_relation("John completed the task"). I get an error as follows; --------------------------------------------------------------------------- TypeError Traceback (most recent call last) in ----> 1 get_relation("John completed the task") in get_relation(sentence) 10 {'POS':'ADJ','OP':"?"}] 11 ---> 12 matcher.add("matching_1", None, pattern) 13 matches = matcher(doc) 14 k = len(matches) - 1 ~\Anaconda3\lib\site-packages\spacy\matcher\matcher.pyx in spacy.matcher.matcher.Matcher.add() TypeError: add() takes exactly 2 positional arguments (3 given) What shall I do to fix it?
Hi, First of all thanks for the wonderful areticle. One quick question that I have. How do I store this in the graph DB and query it also.
Great and educative piece Prateek... ...a small code update as follows will prevent an error ( because of Spacy's more recent version I think): # in line 14 of def get_relation(sent): replace: matcher.add("matching_1", None, pattern) with: matcher.add("matching_1",[pattern]) ...truly great piece anyway! Ajit (founder of rediff.com and data science enthusiast
How to work for on medical domain dataset to generate a knowledge graph for that. Thank you