Overview
- Learn how to use graphs to identify social media influencers
- We will demonstrate several techniques to identify these social media influencers and lay a roadmap for future use cases
Introduction
I’m fascinated by the power of social media. A seemingly obscure personality suddenly rises up from the ground and holds a following of thousands and even millions! Social media has given the average human a tremendous platform to engage with the world.
Most businesses (if not all), are using social media for marketing their products and services. This includes running paid advertisements, designing viral content, or relying on their quality to gain a following online.
One of the more fascinating branches to emerge from this is the use of social media influencers to promote brand awareness. I’ll show you a few examples in this article on how using these social media influencers changed the game for a lot of businesses.

This got me thinking – what exactly are social media influencers? How can we formally define them? And is there a way to leverage my knowledge of graph theory to identify these influencers? We’ll answer all these questions and more in this article!
Do note that I will be using the terms “graphs” and “networks” interchangeably to denote social networks. Similarly, the terms “link”, “connection” and “edge” mean the same thing.
If you’re new to graph theory, I would encourage you to go through the below tutorials as well:
- Let’s Think in Graphs: Introduction to Graph Theory and its Applications in Python
- All Tutorials on Graphs and Networks
Table of Contents
- Who are Social Media Influencers?
- Why is Influencer Identification Important?
- Real-Life Use Cases
- Locating Individual Influencers
– Degree Centrality
– k-core Centrality
– Closeness Centrality - Identifying Multiple Influencers
– Independent Cascade Model
– Linear Threshold Model
Who are Social Media Influencers?
When we think about influential personalities on social media, people with millions of followers come to mind. Personalities like Barack Obama, Donald Trump, Lady Gaga, Cristiano Ronaldo, etc. hold away over millions and millions of people around the world.
Things, however, are starting to change. Thanks to the incredible rise of social media platforms such as Twitter, YouTube, Facebook, Reddit, Quora, etc., we don’t need to be a celebrity to be a social media influencer. If you are really good at something and people admire you for that, you qualify as a social media influencer.
For example, people outside the data science community might not recognize the man in the picture below. But being a pioneer in the field of machine learning and computer vision, he is a big influencer and his name is Yann LeCun.

So, social media influencers are those individuals who have a loyal following of users, and they achieve a high level of engagement on their content, such as images, blogs, posts, videos, etc. Usually, these influencers are viewed as experts in their domains, have a high level of convincing power, and can easily persuade others.
Why is Influencer Identification Important?
In recent times, discovering influencers on social media is becoming increasingly important. The benefits that come along with it are amazing. It is useful for tasks like viral marketing, product promotion, behavior adoption and even analyzing epidemic spreading.
For a small brand, finding a social media influencer with thousands of loyal followers to promote their products is much more economical and fruitful than spending their advertising budget on billboards or TV ads.
It is easy to find a popular non-celebrity social media user, such as PewDiePie the YouTuber, or Jamie Oliver, a top food influencer on Instagram. However, we also can’t ignore the fact that there are many social media users with an audience of about 1,000 to 100,000 who have achieved recognition in their respective fields. Even though their following is not big, they can collectively influence the behavior and decision making of a large number of people.
Real-Life Use Cases of Social Media Influencer Marketing
Here, I am listing some of the recent examples of how social media influencers contribute to a wide range of campaigns.
- Pantene teamed up with African American social media influencers to promote their Gold Series Collection:
- Coca-Cola started an Instagram influence campaign with a few micro-influencers. They managed to generate an average engagement rate of around 8%:

- Some of the influencers are also using their positions to raise awareness of social issues. For example, Mike Sherbakov raised $52,800 to build houses for the homeless:

There are a ton of similar examples from across the globe. I’m sure you’ve come across them in your social media circles as well.
Locating Individual Influencers
The easiest way to find influencers in a social network is by ranking them based on their influencing capability. Let’s dive deeper and find out what this “influence capability” is and how we should calculate it.
Let’s understand it with the help of a graph:

This graph has 13 nodes. Let’s say each node represents an individual and the edges connecting these nodes denote some relationship. This is an example of a social network.
Now, which individual looks important to you?
Is it node 6? It has the maximum number of connections (5). It can influence five individuals immediately:
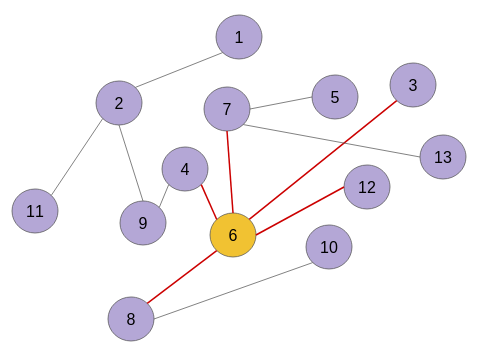
Or is it node 4 since the route to nodes 9, 2, 1 and 11 go through node 4? If this node is gone, then it breaks this social network into two. So, node 4 might have an influence on two big clusters in this graph because of its crucial position:

Neither of the two approaches is wrong. However, under different settings, one might outperform the other. There are many more methods to quantify the importance or influencing capability of a user in a social network.
In case you come across the word “centrality”, it is essentially a measure of the importance of a node in a graph.
Let’s see some of the commonly used methods to gauge the “influencing capability” of social media users.
A) Degree Centrality
In the context of graphs, the degree of a node in a network is the number of edges incident with it. So, we can use this property to rank the user of a social network starting from the most influential user at the top:

As you can see in the sample network above, node 6 is the most influential user followed by node 2 and then by node 7.
The advantages of the degree centrality method are that it is easy to implement and highly scalable as it requires negligible computational resources.
On the downside, the number of direct connections may not be a reliable indicator in real-world social networks. This approach takes into account only the immediate neighbors that are directly connected and not the entire structure of the network.
B) k-core Centrality
Unlike the Degree Centrality method, the k-core Centrality method takes into account the entire network.
In this method, the nodes, with connections lesser than k (a threshold value), are removed from the network. After the removal of these nodes, the network is checked again to see if there are nodes still present with less than k connections. If yes, then they are also removed. This process is repeated till every node has a degree equal to or higher than k.
The leftover nodes are assigned a k-core number equal to k.
The limitation of the k-core method is the fact that it ends up assigning a lot of nodes the same k-core number.
C) Closeness Centrality
This centrality measure takes into account the distance of a node to all the other nodes in a network. We can define Closeness Centrality by the expression below:

- Where Ci is the closeness centrality of the node i
- N is the total number of nodes in the network
- dij is the length of the shortest path between node i and node j
Closeness centrality is suitable for those problems where the objective is to find or use the shortest paths in the network.
There are many other centrality metrics apart from the ones discussed above, such as Betweenness centrality and Eigenvector centrality. I encourage you to go and check them out if you want to dive deeper into the topic.
Locating Multiple Influencers
In large-scale social networks, the collective behavior of large populations can be influenced by a handful of individuals. Let’s call these individuals “super spreaders”. The identification of super spreaders helps in controlling an entire network or a big part of the network.
For example, in case of a disease spread, if we can find the super spreaders, then we have a much better chance of containing the disease. It can also be helpful for viral marketing of a product – just get the super spreaders on board and let them promote the product.
This problem of finding super-spreaders in a network is formally known as collective influence maximization. It might seem similar to the problem of identification of individual influencers but there is a big difference between the two problems.
In collective influence maximization, we are in search of those individuals who might not be the most influencing users, but collectively they influence the network in a big way.
It is not an easy problem and it is still an active area of research. Here, let’s see some methods that we can use for collective influence maximization.
A) Independent Cascade Model (ICM)
In an independent cascade model, a probability pi is specified for each edge of a network in advance. A node is influenced by its neighboring nodes with the predefined probability, independently. In this model, nodes can have two states — active (influenced) and inactive states (not influenced).
Let’s say we are tracking the flow of information in an online social network. So, under ICM. our goal is to identify a set of k users that could generate the largest influence. The steps involved in ICM are given below:
- At time t, k nodes carry the information. In other words, we can say that these nodes are activated. These nodes are called seed nodes
- When any node u is first activated, it has a single chance to activate each of its neighbors v. The success depends on the probability puv assigned to the edge connecting u and v. This happens at time t+1
- If the node v gets influenced, then node v will activate its neighbors. If v does not get activated by node u, then u will never attempt to activate v again
B) Linear Threshold Model (LTM)
Under LTM, a node’s state (influenced or not) is determined collectively by its neighbors’ state. It differs from ICM in the way the nodes of a network get influenced. Each node in the network is assigned a threshold value θi and each edge is assigned a weight w (u, v). Similar to ICM, k seed spreaders have the information initially.
During information flow, a node u is influenced only if the sum of the weights of the edges incident on it is greater than or equal to the nodes threshold value θu.
End Notes
This was a quick primer on how to identify social media influencers using graphs. As I mentioned above, this is an active area of research and I expect a lot of developments to happen this year.
I’ve listed below a list of references using which you can deep dive further into this topic. Feel free to reach out to me in case you have any queries or want to share your feedback on this article.
References
- Maximizing the Spread of Cascades Using Network Design (https://arxiv.org/pdf/1203.3514.pdf)
- Maximizing the Spread of Influence through a Social Network (https://www.cs.cornell.edu/home/kleinber/kdd03-inf.pdf)
- Efficient collective influence maximization in cascading processes with first-order transitions (https://arxiv.org/pdf/1606.02739.pdf)
- Network Centrality: An Introduction (https://arxiv.org/pdf/1901.07901.pdf)
- Machine Learning Techniques for brand-influencer Matchmaking on the Instagram Social Network (https://arxiv.org/pdf/1901.05949.pdf)
- Finding Influential Users in Social Media Using Association Rule Learning (https://arxiv.org/pdf/1604.08075.pdf)
- Theories for influencer identification in complex networks (https://arxiv.org/abs/1707.01594)
- Influence and Passivity in Social Media (https://www.hpl.hp.com/research/scl/papers/influence/influence.pdf)
Data Scientist at Analytics Vidhya with multidisciplinary academic background. Experienced in machine learning, NLP, graphs & networks. Passionate about learning and applying data science to solve real world problems.






