A quick exercise
Let’s say you are a customer service executive working for a bank (and the only one for this hypothetical case). You need to make sure that you take decisions in the best interest of the bank. Let’s assume that you can read the names of customers in waiting queue before you decide which one to pick. You need to tell, which call would you pick!
All set?

Okay…here goes the first set of customers waiting to talk to you:
- Mr. Steve Dormack
- Mrs. Alicia Suvay
- Mr. Mark Pincus (Co-Founder of Zynga)
The choice should have been easy…right? Well done! Mr. Pincus was happy with your service
Here are next set of customers:
- Mrs. Silvia Cook
- Mr. Elon Musk (CEO & CTO of Tesla & SpaceX)
- Mr. Bill Gates (Yes, you read it right, this is the Bill Gates)
Whose call would you answer now? A difficult (and delightful) situation to be in.

Coming to the point, we make a lot of decisions based on what we think a person’s influence is. At times, these could be simple decisions (like the first set of customers you got). But, at times, this could be mind-numbing (scenario 2). Think of a scenario when you have to answer 10 calls from this list.
In today’s article, we will come up with a framework and make use of data science to measure influence scientifically.
Importance of Influence in today’s world
Let us now consider a more practical scenario. you need to hire for Business Development Ninja for a Technology firm. The ideal candidate should be able to win contracts all by himself and create a network of customers and their referrals. How smartly can you find this candidate ?
Case 1 :
You have received 1000 applications which you need to browse through. After a week of prolonged resume searches, here are some details which you could extract:
- 40% of them holds a commerce degree. 50% of which hold a masters degree.
- 10% of the total profiles have MBA degree.
- 99% of them have a LinkedIn account.
- 15% of them have appeared for TOEFL exams and 20% of them have scored more than 110.
- 15% of them have consulting background. 20% of them have more than 3 years of experience.
- Mean experience of candidates is 7 years. 20% of them have an experience more than 15 years.
- 70% of the candidates have current salary, which is at least 20% lower than what you can offer.
This information can help, but it would take far too much research and time to finalize a candidate.
….and finally you did some smart work. Check out Case 2.
Case 2:
For the same company, you have bought a few networking parameters from LinkedIn on 990 profiles. Now, additionally, you have the following information :
a. Total Networking index for every candidate. For every candidate, this score will capture the following:
- How global is the network?
- How diversified is the network (in terms of domains)?
- How much influential are people in his / her network or network index of the friend?
- How many people view their updates and comment on them?
b. Domain specific Networking index: This will be a similar metric but the entire population is restricted to a particular domain. Hence, you can get this index for finance, consulting, operations and BD for the same user.
Think: With this information and the inputs from case 1, how much easier has your job become now? Is it better or is it worse now? Will such indices make the task easier for you to take decide
Before proceeding beyond this point, write down your thoughts in the comments section below. I’d love to have a discussion on this.
Other applications:
If you are thinking that the use of influence is only in case of selecting A vs. B, think again! Here are a few real world applications to drive the importance home:
- Your bank opens up a new experience of banking and wants to offer it to only a handful of clients. Who should they be?
- Your mobile phone operator wants to give away a few promotional offers to a group of customers. How do they make sure that they make the most of social media attention to it?
- Your company is coming out with a new product and you want to assess which print magazines should you be advertising on?
All these cases need you to measure influence and accordingly take decisions. Since there are huge number of options available in each of these cases, you can not rely on your gut feel any more. You need a scientific criteria to measure influence – so let’s get to work!
Let’s try and measure influence
Suppose, you are asked to design this networking index (mentioned in the recruitment case above) and come up with a common score which can help assess the network of users on LinkedIn. The first thing you should do is to find the objective function right. Try doing this exercise on your own before you check out my approach.
We are trying to assess the following aspects through this index:
- The number of people user is connected to?
- How influential are these people?
- How geographically diverse are these people?
- How are these people different in the domain/profession they work for?
If we can find a metric which can take into account all four, we’ll have the tool / feature which hasn’t been created yet! My idea is to develop something really simple which can do all these. Here are a few definitions I have created to build this index :
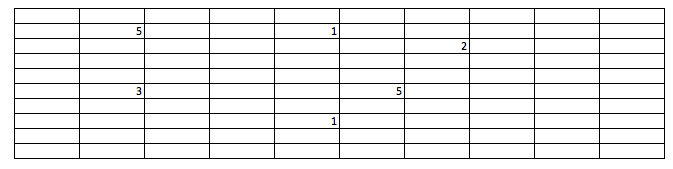
1.Geographical Coverage : Divide the entire world into 10*10 equal segment (you can choose any number here), and see the presence of friends in each of these segments. The number in following table denotes the number of friends. In this example, geographical coverage is 6. To eliminate noise we can put a threshold on number of people required in block to make it count (Here I have not used any thresholds).
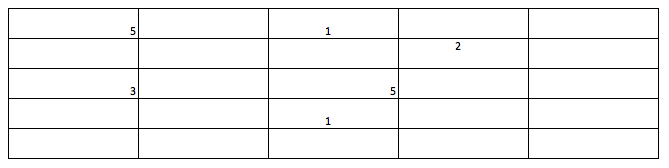
2. Geographical Compression Rate : Make the blocks bigger and recheck the coverage. For instance in following diagram, the broad coverage stays at 6. I define Geographical compression rate as (Broad coverage / Geographical coverage) which is 1 in this case. This number will be somewhere between 4 and 1 in my case. The smaller this number, more spread out are all the points. Hence smaller compression rate is desirable.
3.Total Influence: Currently we are considering only head counts, but all connections are not the same. Hence, the total influence will simply be the score of all the total index (which we will define later) across the entire user network.
4.Diversity in domain expertise : Let’s broadly categorize the domains into : Finance, Marketing , Operations, Manufacturing and Information Technology. Now we do a similar exercise as geographical coverage. Here I put a threshold of atleast 2 people required to make the field count. Here the domain diversity is 2 as IT is not a field which will count for this user (below threshold).

Create a single score
We have all the ingredients now. Let’s look at the desirable direction of each co-efficients.
1. Geographical Coverage (G) : Higher the better
2. Geographical Compression Rate (C) : Lower the better
3. Total Influence (I) : Higher the better
4. Diversity in domain expertise (D): Higher the better
As you can clearly see, calculation of Total Influence is not very straight forward and needs to be done iteratively. We can start with a common weight across as 1 and then try to iterate all the Total Influence.
Now is the time to define our Influence score, (simply put)
Influence Individual Score = G*I*D/C
where, I = Sum over user network (Influence Individual Score)
Tweak the score to suit your need…
Here are some variations which can be incorporated in the methodology. For instance, you need the Influence Individual Score only for Consulting network. You simply restrict the entire universe to only Consulting jobs in profile. Now calculate the same index to get this variation. There can be many other variations to it, for instance you need the influence score for only Asia zone. Again the approach will be to restrict the universe to Asia location.
End Notes
I hope you enjoyed this exercise and hope someday we will actually see these types of products being used in the market. The score will be as powerful as FICO or CIBIL scores (used in financial markets). There have been a few attempts on creating something like this in past, Klout probably being one of the most recognized one. However, the problem is far from solved yet.
Did you enjoy reading this article? Have you wondered over this question before? Do you think you can improvise this framework further to make it more realistic?
If you like what you just read & want to continue your analytics learning, subscribe to our emails, follow us on twitter or like our facebook page.
Tavish Srivastava, co-founder and Chief Strategy Officer of Analytics Vidhya, is an IIT Madras graduate and a passionate data-science professional with 8+ years of diverse experience in markets including the US, India and Singapore, domains including Digital Acquisitions, Customer Servicing and Customer Management, and industry including Retail Banking, Credit Cards and Insurance. He is fascinated by the idea of artificial intelligence inspired by human intelligence and enjoys every discussion, theory or even movie related to this idea.




{kind=link}
very useful and yet simple.
The approach is Due diligently explained, i feel the Centrality Score and the list of topics which the user is discussing are also very important parameters. For e.g, Identifying Fraudulent Claims based on Social Network Analysis.