Introduction
We are aware of the massive amounts of data being produced each day. This humungous data has lots of insights and hidden trends stored within it that need to be skillfully extracted by data scientists. However, collecting this massive amount of unstructured data is a challenging task in itself. But don’t worry, data engineers are here to your rescue!

Data engineers gather the unstructured or semi-structured data from various sources and store them in a structured format in databases. They prepare this data for model building required by the data scientists. They are the intermediary between unstructured and structured data and play a crucial role in a real-world data science project.
In this article, we will work with a small project of analysing streaming Tweets. From extracting data from the source and storing it into a database to processing that data and preparing it for analysis tasks, we will try to understand the workflow of a data engineer’s task. And to bring closure to this project, we will analyse this data towards the end and see if we can come up with some valuable insights.
Table of Contents
- What we want to achieve here
- Installing relevant Libraries
- PostgreSQL Database
- Creating Database in PostgreSQL
- Creating Twitter Developer Account
- Authenticating the Twitter API
- Streaming Tweets using Tweepy
- Streaming Tweets on Keywords
- Streaming Tweets in Real-Time using StreamListener
- Creating Tables in PostgreSQL
- Connecting to the Database
- Streaming Tweets into Database
- Analyzing Streamed Tweets
Note – The Github link for this can be found here – https://github.com/aniruddha27/Analysing-Streaming-Tweets
What we want to achieve here
Today, the production of data is at a lightning pace. Every domain from stock markets and social media platforms to IoT devices are producing thousands of rows of data in a matter of seconds. But often this data is of immense importance in real-time. For example, analyzing real-time weather data is important for forecasters to predict how the weather will change over time.
This streamed data can either be analysed in real-time or can be stored and analysed later. Either way, it proves to be immensely important for analysis and deriving insights. Therefore, it becomes imperative for every data scientist to understand how to handle real-time or streaming data. And what better streaming data than Twitter which produces millions of Tweets every hour!

Twitter is a treasure trove of data. A plethora of tweets is sent out every second. Just imagine how much information you can extract from this. If you can analyse streaming tweets, you can understand the feelings of the people about events happening in the present. Businesses can leverage this information about how the public is reacting to their product. Investors can determine how a stock is going to perform and so much more.
Here we plan to stream tweets on Covid-19. Determine people’s sentiment about a disease that has disrupted our lives in an unprecedented way. Also determine what hashtags are being used by people, which keywords are being used, and more.
We will accomplish this by first establishing a connection with the Twitter API. Then we will extract relevant information from tweets and store them into a database. Once we have done that, we can query this database and analyse the streaming tweets. Below is a visual representation of how we are going to achieve this.

Now, before delving into the programming part, let’s first install the relevant libraries for this project.
Installing relevant Libraries
We need to install three of the following things for this project:
- PostgreSQL database to store the Tweets
Installing PostgreSQL is pretty easy and straightforward. Head over to the download page and download the application according to your machine’s operating system. Once you have done that, PostgreSQL will be downloaded on your machine along with the pgAdmin tool which is a development platform for PostgreSQL. - Tweepy library to stream the Tweets
Tweepy is a great library to access the Twitter API. Using Tweepy you can either stream tweets from your timeline, a specific user’s timeline, or simply search for the specific keyword! All using simple and elegant in-built functions.It is pretty straightforward to install Tweepy. You can either use pip to install Tweepy:pip install tweepy
Or use Git to clone the repository from GitHub.
git clone https://github.com/tweepy/tweepy.git cd tweepy pip install .
psycopg libraries to access the PostgreSQL database from Python.
You can install psycopg using the pip command.!pip install psycopg
Alright, now we have downloaded all the relevant libraries for the project. Now let’s understand the properties of PostgreSQL and why we are using it here.
PostgreSQL Database
Postgresql is a relational database management system based on SQL. It is free and open-source and works well on all Operating Systems. Further, it has a proven reputation for safely and robustly storing your data and supports both SQL (relational) and JSON(non-relational) based querying.
Postgresql has properties like asynchronous replication, multi-version concurrency control, and many more. Additionally, Postgresql is also highly extensible. You can create your own data types, index types, and more. Besides supporting the primitive data types like boolean, characters, integers, etc., Postgresql also has some additional data types related to geometry like a box, line, polygon, etc.
Postgresql is widely used as a back-end database with many dynamic websites and web applications and provides support for many languages like Python, Java, C++, and more.
The popularity is well documented. In the recent Stack Overflow survey of 2019, Postgresql was the second most popular database amongst the professional developers, ahead of giants like SQL Server, Oracle, and others. And is popularly used by many technology behemoths like Apple, Spotify, Instagram, and more.

So why are we using Postgresql for our purpose here? Being a relational database, we can use Postgresql to define the table structure and the datatypes we want for each of the attributes. It will also ensure that redundant data is not saved multiple times in the database, which can save us a lot of space.
We can utilize the properties of the primary key and foreign key to create multiple related tables in the database for different purposes. Storing data in this structured manner will allow us to query the database according to our requirements.
So let’s install this awesome database!
Creating Database in PostgreSQL
Let’s create a database in Postgresql where we will create multiple tables to store data that we receive from Twitter API. To create a database in Postgresql, we are going to use the pgAdmin tool that got installed when we installed Postgresql.
Create a new database and give a name to it. I am going to name our database TwitterDB.

That’s it! You created a database for storing your tweets. Since Postgresql supports Python programming language, we will leverage that capability later on in the article to create tables inside this database. For now, let’s set up our Twitter API!
Creating Twitter Developer Account
To stream data from Twitter, you will need to head over to the Twitter developer’s website and register your app to get access to the Twitter APIs. The steps are pretty straightforward. However, you need to provide a good explanation as to what you are going to do with the data you receive from Twitter. Hence, this might take a while, but you should be able to get this done pretty easily.
Once you have registered your app, you will be provided with an API access key and API secret key. Store these keys in a safe place because they will only be generated once and you will need them, again and again, to connect to the API.
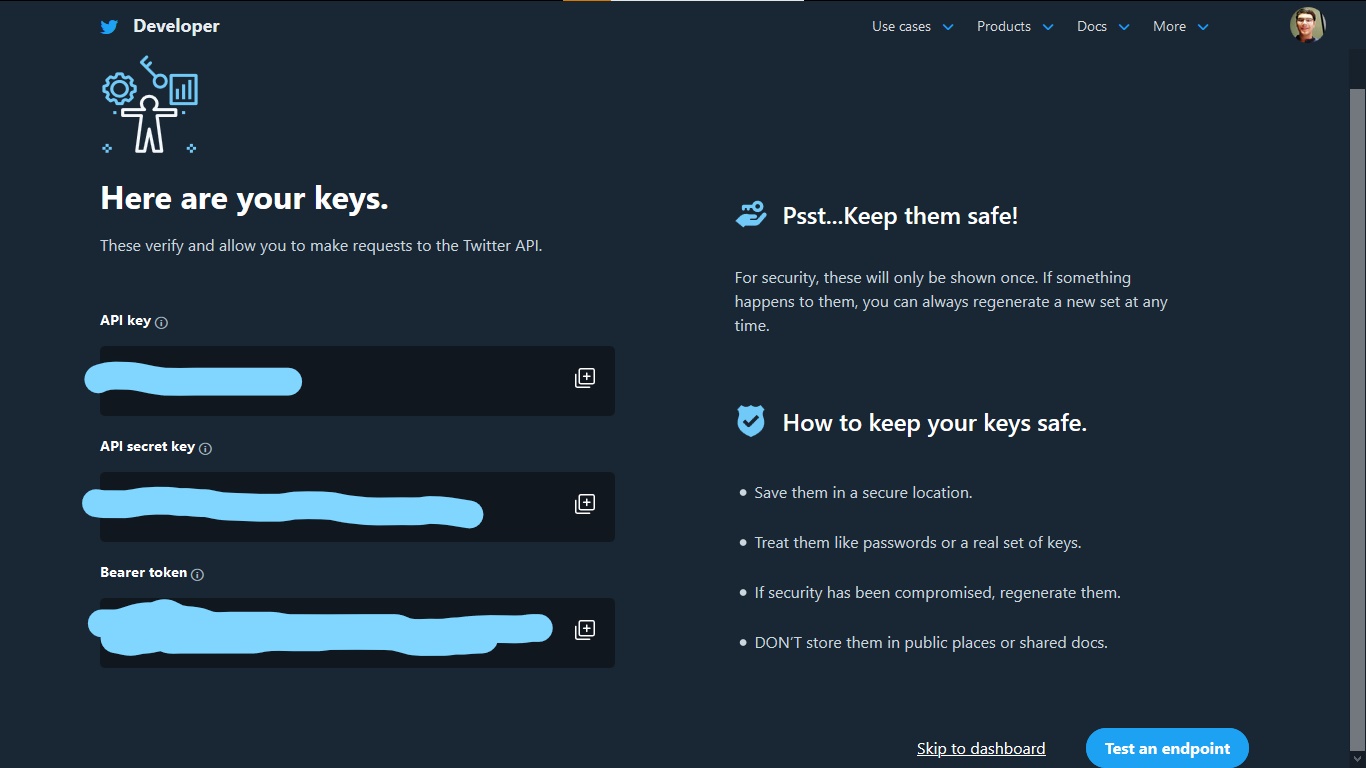
Once you have done this, head over to the dashboard and give a name to your app. Then access the Access token and generate Access Token Secret key. You will need these two keys as well to connect to the API.

Alright! Now that you have your API access keys, it’s time to stream those tweets!
Authenticating the Twitter API
Authenticating Twitter API with Tweepy is a piece of cake.
Firstly we need to create an OAuthHandler instance that handles the authentication. To do this, you need to pass the API key, API secret key, and Access token that you saved after setting up your Twitter app.
Besides this, you will also need the Access Token Secret key which you can generate by logging into your developer account and generating one for the Twitter app that you created. Once you have done that, you can finally create the API object by passing in the authentication information.
Now you can finally stream your data using Tweepy!
Streaming Tweets using Tweepy
There are a couple of ways to access the data from Twitter. Let’s start with the first one, accessing tweets from our own timeline.
To do that you need to use the API object’s home_timeline() function. By default, it returns 20 most recent tweets from your timeline but you can change that using the count parameter.
You can even use Tweepy to access tweets from another user’s timeline. For this, you have to use the API object’s user_timeline() function.
Alright now that you have got your hands dirty by streaming tweets, it is important to understand the various data fields that are being retrieved along with the tweet text. Let’s dive deep and unravel the streaming data.
Streaming Tweets on Keywords
The Twitter API returns the data in JSON format. So far we had just accessed the text from the tweet using tweet.text. But there is more to what is being returned by Twitter API. To understand that, let’s stream tweets on a specific topic.
Since we are looking to analyse streaming tweets around Covid-19, let’s stream those tweets using the API object’s search() method which uses the Twitter Search API.

There is a wealth of information being returned here. As you must have noticed, the API returns the Tweet and related information in a JSON format. Each Tweet JSON contains information about the tweet, the user, entities like hashtags and mentions, and so on. There can be over 150 attributes associated with the Tweet! Let’s try to understand some of the important fields in the Tweet JSON that are returned by the API.
- id – This integer attribute is a unique identifier for the Tweet.
- text – This is the Tweet text that we are looking for. It can contain up to 140 characters.
- user – Contains details about the author of the tweet as a nested field. Information like user id, user creation date, screen name, etc. can all be found in this field.
- entities – This field contains information such as hashtags, mentions, links, etc. These are also present as nested fields.
- truncated – In 2017, Twitter extended the Tweet JSON to include longer messages of up to 280 character length. This field indicated whether the Tweet is shorter than 140 characters or not. If the tweet is longer than 140 characters, it returns True otherwise it returns False.
- extended_tweet – In case the tweet contains more than 140 characters, the tweet, and the entity information will be truncated in the root-level fields. To access the complete data, you need to access the fields nested within extended_tweet
The following command will let you access the Tweet JSON-
pprint(result[0].user._json)
To access hashtags from code, use the following code.
pprint(result[4].entities['hashtags'])

You can read about the Tweet JSON in detail here.
Now, Tweepy’s search() method is great. But there is a drawback to it. It retrieves Tweets using the Search API which gives results from the past, going as far as 7 days. This means that the Tweets retrieved aren’t actually in real-time. Moreover, the Search API also has a limit of 180 tweets per 15-minute window.
Also, the Tweets retrieved aren’t exhaustive. Meaning, there might be some Tweets, matching the keywords, that might be missing from those that the API returns. So, how do we stream Tweets in real-time? We use the Streaming API!
Streaming Tweets in Real-Time using StreamListener
The Streaming API lets you stream Tweets in real-time. It is useful for obtaining a large number of tweets or for creating a live stream of tweets. Unlike the Search API, which pulls data from Twitter, the Streaming API pushes messages to a persistent session.
“Rather than delivering data in batches through repeated requests by your client app, as might be expected from a REST API, a single connection is opened between your app and the API, with new results being sent through that connection whenever new matches occur. ” — Consuming streaming data
Also, the Streaming API returns data in JSON and with the same fields as the Search API. We will use the Tweepy’s StreamListener class to stream real-time tweets. This class has several methods to handle tweets.
The on_data() method in this class which receives the messages and calls the appropriate method. The on_status() method handles the staus of the tweet. Since our only concern is the tweet the user creates, we will be working with the on_status() method.
We need to create a custom class that will inherit the StreamListener class and overrides the on_status() method. Here we will write our own code to extract the relevant data from the tweet. We will also override the on_error() method that handles any errors that occur during the connection. We are concerned about error 420 which occurs when we exceed the limit on the number of attempts to connect to the Streaming API.
As you can see, I have put the code to read the tweet inside the if-else loop. This is so because if the tweet is an extended tweet, exceeding 140 characters, it will be truncated. To retrieve the full tweet, in that case, would mean that we have to access the tweet from the extended_tweet field rather than reading from the root-level text field.
We will be only connecting and saving the tweet to the database when the tweet is in English and is not a retweet, since our only concern is about new tweets here.
Also, I have included a code to pass False as the output when the time exceeds the time_limit. This I have done to make sure the connection doesn’t stay alive forever. I will only be keeping it alive for 300 seconds. You can change this according to your needs.
Since the hashtags field dictionary (containing hashtags and their character indexing in the tweet) is saved within a list in the entities field, I have written a custom method read_hashtags() to extract only the hashtags and save them in a Python list.
Finally, to connect to the database and save the tweets, I will write a custom dbConnect() method which we will discuss in one of the succeeding sections. First, let’s set up those tables in the database!
Creating Tables in PostgreSQL
Now that we know how to stream tweets using the Twitter API, it time to define those tables inside the TwitterDb database that we created using pgAdmin.
Remember that I said Postgresql supports the Python Programming. Well, how does it do that? It provides a very popular database adapter called psycopg that let us enjoy the best of both the worlds, Python and Postgresql!
Let’s first write up the commands for creating the tables. Since Postgresql support SQL language, the syntax should be pretty easy to grasp. The important part however is understanding the various tables and how they relate to each other.
Check out this article to understand the various keys in SQL.
We are going to create three tables in the database.
The first table will be TwitterUser. It will contain user-specific information.
- user_id – Unique user id. This will be the PRIMARY KEY for the table.
- user_name – User screen name
The second table will be TwitterTweet. It will contain tweet specific information.
- tweet_id – Unique tweet id. This will be the PRIMARY KEY for the table.
- tweet – Tweet text
- retweet_count – Number of times the tweet was retweeted
- user_id – To relate the user information with their tweet information, we are going to include the user_id from the TwitterUser table as a FOREIGN KEY in this table.
The third table will be TwitterEntity. It will contain entity information. Specifically, we will be storing hashtags from the tweet but you can store other entity fields as well.
- id – Unique to represent the rows. It will be of SERIAL type which will make sure that this field increments automatically as new rows are added to the table. We don’t have to provide this value, the database will handle it on its own (perks of using Postgresql ;))
- hashtag – It will store the hashtags and will be of VARCHAR type.
- tweet_id – To relate the table to the TwitterTweet table, we will include the tweet_id as FOREIGN KEY in the table.
Below is a visualization of the tables and how they are related to each other.

Since the tables are related to each other, it is important to create the table in order otherwise we will get an error. First, we will create the TwitterUser table, then TwitterTweet, and finally TwitterEntity table. Let’s write these commands in a simple tuple.
Now, let’s make a connection to the Postgresql server using psycopg. For that, you need to import the psycopg module and call the connect() method. In the method, you need to pass some important arguments.
- host – Database server address
- port – The port number on which the server is running. By default, it is 5432.
- database – Name of the database name you want to connect to.
- user – The username to authenticate.
- password – Password to authenticate the user.
import psycopg2 # Connection to database server conn = psycopg2.connect(host="localhost",database="TwitterDB",port=5432,user=<user>,password=<password>)
The connect() method creates a new Database session and returns an instance of the connection class. Now we need to generate a Cursor object using the cursor() method which allows us to execute queries against a database using the execute() method.
Don’t forget to commit the changes and close connection after use so that the database doesn’t get locked!
Now its time to define that custom dbConnect() function, that we created in the MyStreamListener class, that will take the data from the streaming tweets and save to our database.
Connecting to the Database
We have already seen how to connect to the database and how to execute SQL commands from Python using psycopg. Now we will do those together. Whenever a tweet needs to be saved to the database, we will first open a connection to the database, execute the SQL command to the database, commit the changes, and finally close the connection. This is what is happening in the dbConnect() method below.
There are however two important things to point out here.
Firstly, I have used the ON CONFLICT command while inserting information into the TwitterUser table that is storing information about the author of the Tweet. This is so because a user can create multiple tweets but we don’t want to store the information about the same user multiple times. That’s the beauty of RDBMS!
Secondly, I have used a for-loop for inserting information into the TwitterEntity table. This is so because the hashtags parameter received by this function is a Python list that we generated in our custom MyStreamListener class. Since RDBMS needs to maintain atomicity, we need to insert each of these hashtags as new rows.
Once we are done adding values to the tables, we commit and close the connection.
Streaming Tweets into Database
We have set up how we will stream tweets in real-time and how we will store them in the database. Now, it is time to call the Streaming API and store those tweets in the database. To do that we need to first create an instance of our MyStreamListener() class. This instance along with our API authentication will be passed to tweepy. Stream() method. Finally, we can filter the keywords we want to receive by using the filter() method on the instance returned by tweepy.Stream().
The tweet_mode argument specifies whether you want to access the tweets in extended mode or not.
Its time to analyse the streamed tweets, now that we have successfully streamed and stored them!
Analysing streamed tweets
Having finished with the tricky part already, analysing tweets should be a piece of cake! I am going to do three things here-
- Check out the most commonly occurring words in the tweets.
- Determine the sentiment of the tweets.
- Chart out the count of the hashtags that we retrieved from the tweets.
Let’s start out by importing the relevant libraries.
from nltk.stem import WordNetLemmatizer import numpy as np from textblob import TextBlob import re from wordcloud import WordCloud import matplotlib.pyplot as plt import seaborn as sns
The first thing to do when working with text data is to preprocess the text. So let’s do that!
We are going to do the following things to preprocess the tweets:
- Remove tweet URLs.
- Remove any mentions that were present in the tweet.
- Remove all non-alphanumeric characters from the tweet.
- Lemmatize the words in the tweet.
- Finally, convert the tweet to the lowercase.
I am going to create a separate function to execute the SQL queries on the database.
Then, let’s write up the SQL queries to retrieve the tweets from the database and save the resulting data into a dataframe for analyzing.

Let’s create a word cloud of the most commonly occurring words in the tweets.

We can notice words like “Covid”, “mask”, “pandemic”, “virus”, “lockdown”, etc. occuring quite frequently in the tweets (as expected).
Then let’s check out the sentiment of the tweets using the Textblob library. We will be using the sentiment() method to call upon the tweet and check out the polarity of the sentiment. Further, the polarity of -1 means that the tweet is a negative statement and 1 means that the tweet is a positive statement (a blessing in these tough times!).

Now let’s do the final thing we wanted to achieve in this analysis – determining the most commonly occurring hashtags!
Firstly, we need to query and retrieve the hashtags from our TwitterEntity table in the database.

We have 277 unique hashtags here, that’s almost 75% of the total number of tweets we mined from Twitter! People surely use hashtags a lot in their tweets.
Let’s create a pivot table to determine the count of the unique hashtags from the tweets.

Finally, let’s visualize these hashtags.

As you can see, although COVID-19 is mostly used hashtag in the tweets, there are other events that people want to talk about in their tweets as well. Twitter is truly THE place to understand the present feelings of the people. Well done Twitter!
Endnotes
To summarize, we learned to stream tweets in real-time, store them in a database, and finally analyse streaming tweets. This was really a fun project to work on, hope you were able to get a glimpse of the responsibilities of a data engineer! Surely, there were a lot of other things we could have retrieved and analysed from the tweets, but I leave it up to you to experiment with them and come up with your own mind-boggling analysis.
You can check out this amazing article and this super awesome free course on Twitter analysis that we have created for you.
I hope you have understood each and every concept in this article. In case you have any queries, reach out to me in the comments below.
I am on a journey to becoming a data scientist. I love to unravel trends in data, visualize it and predict the future with ML algorithms! But the most satisfying part of this journey is sharing my learnings, from the challenges that I face, with the community to make the world a better place!







Nice workflow man, this gives a good picture of the process. On the implementation side, I'd recommend to be more attentive to the resource usage. Being slow to process each tweet will force Twitter to drop tweets being delivered. It's data being lost for no reason. Opening and closing a connection to the database is a very time consuming operation. Doing it at every tweet is not a good idea. Also, look for prepared statements instead of making the DB parse de SQL query each time a row is inserted. If you want a real real-time-no-tweet-drops example, check out this post. Very inspiring: http://kirkshoop.github.io/2016/12/04/realtime_analysis_using_the_twitter_stream_api.html
Hi Antonio, glad you found the article useful in understanding the workflow. I do realize that Twitter puts a rate limit on streaming tweets and so processing of the tweets should be fast. For this, a persistent database connection as suggested by you is the way to go. I will update the same in the code. Also, thanks for sharing such a nice project with the community! Thanks!
This is too good !
Great work ANIRUDDHA BHANDARI, Can you please share the final project via Git? It will be very helpful to wrap all the code under the Class and Project file.