Introduction
As a data scientist working with Python, it’s crucial to understand the importance of feature selection when building a machine learning model. In real-life data science problems, it’s almost rare that all the variables in the dataset are useful for building a model. Adding redundant variables reduces the model’s generalization capability and may also reduce the overall accuracy of a classifier. Furthermore, adding more variables to a model increases the overall complexity of the model.
As per the Law of Parsimony of ‘Occam’s Razor’, the best explanation of a problem is that which involves the fewest possible assumptions. Thus, feature selection becomes an indispensable part of building machine learning models.
Learning Objectives:
- Understanding the importance of feature selection.
- Familiarizing with different feature selection techniques.
- Applying feature selection techniques in practice and evaluating performance.
Table of contents
What Is Feature Selection in Machine Learning?
The goal of feature selection techniques in machine learning is to find the best set of features that allows one to build optimized models of studied phenomena.
The techniques for feature selection in machine learning can be broadly classified into the following categories:
Supervised Techniques
These techniques can be used for labeled data and to identify the relevant features for increasing the efficiency of supervised models like classification and regression. For Example- linear regression, decision tree, SVM, etc.
Unsupervised Techniques
These techniques can be used for unlabeled data. For Example- K-Means Clustering, Principal Component Analysis, Hierarchical Clustering, etc.
From a taxonomic point of view, these techniques are classified into filter, wrapper, embedded, and hybrid methods.
Now, let’s discuss some of these popular machine learning feature selection methods in detail.
Types of Feature Selection Methods in ML
Filter Methods
Filter methods pick up the intrinsic properties of the features measured via univariate statistics instead of cross-validation performance. These methods are faster and less computationally expensive than wrapper methods. When dealing with high-dimensional data, it is computationally cheaper to use filter methods.
Let’s, discuss some of these techniques:
Information Gain
Information gain calculates the reduction in entropy from the transformation of a dataset. It can be used for feature selection by evaluating the Information gain of each variable in the context of the target variable.

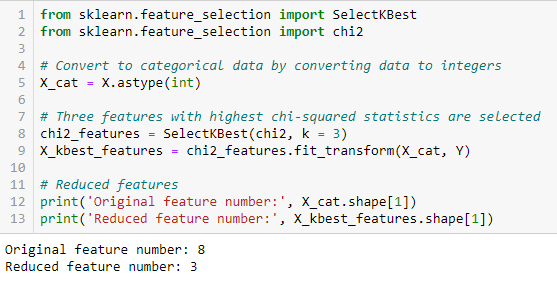
Chi-square Test
The Chi-square test is used for categorical features in a dataset. We calculate Chi-square between each feature and the target and select the desired number of features with the best Chi-square scores. In order to correctly apply the chi-squared to test the relation between various features in the dataset and the target variable, the following conditions have to be met: the variables have to be categorical, sampled independently, and values should have an expected frequency greater than 5.
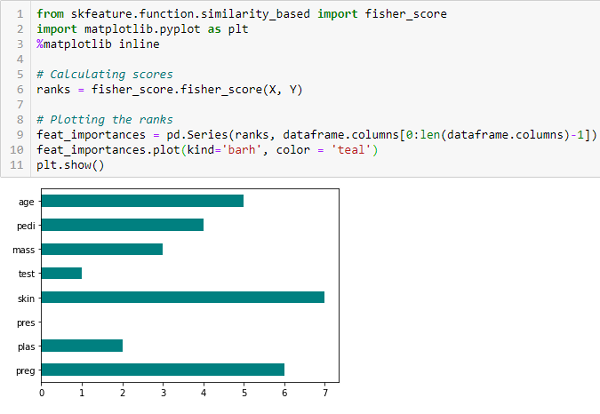
Fisher’s Score
Fisher score is one of the most widely used supervised feature selection methods. The algorithm we will use returns the ranks of the variables based on the fisher’s score in descending order. We can then select the variables as per the case.
Correlation Coefficient
Correlation is a measure of the linear relationship between 2 or more variables. Through correlation, we can predict one variable from the other. The logic behind using correlation for feature selection is that good variables correlate highly with the target. Furthermore, variables should be correlated with the target but uncorrelated among themselves.
If two variables are correlated, we can predict one from the other. Therefore, if two features are correlated, the model only needs one, as the second does not add additional information. We will use the Pearson Correlation here.

We need to set an absolute value, say 0.5, as the threshold for selecting the variables. If we find that the predictor variables are correlated, we can drop the variable with a lower correlation coefficient value than the target variable. We can also compute multiple correlation coefficients to check whether more than two variables correlate. This phenomenon is known as multicollinearity.
Variance Threshold
The variance threshold is a simple baseline approach to feature selection. It removes all features whose variance doesn’t meet some threshold. By default, it removes all zero-variance features, i.e., features with the same value in all samples. We assume that features with a higher variance may contain more useful information, but note that we are not taking the relationship between feature variables or feature and target variables into account, which is one of the drawbacks of filter methods.

The get_support returns a Boolean vector where True means the variable does not have zero variance.
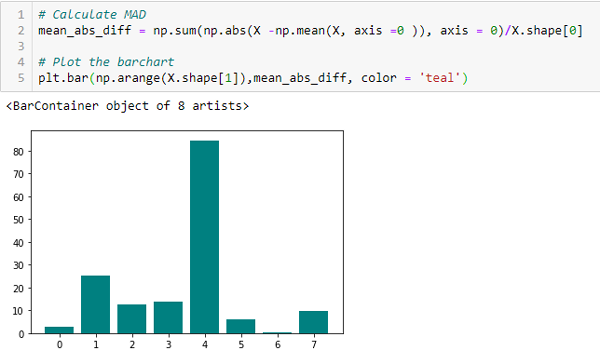
Mean Absolute Difference (MAD)
‘The mean absolute difference (MAD) computes the absolute difference from the mean value. The main difference between the variance and MAD measures is the absence of the square in the latter. The MAD, like the variance, is also a scaled variant.’ [1] This means that the higher the MAD, the higher the discriminatory power.
Dispersion Ratio
‘Another measure of dispersion applies the arithmetic mean (AM) and the geometric mean (GM). For a given (positive) feature Xi on n patterns, the AM and GM are given by
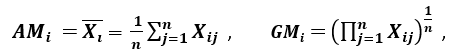 respectively; since AMi ≥ GMi, with equality holding if and only if Xi1 = Xi2 = …. = Xin, then the ratio
respectively; since AMi ≥ GMi, with equality holding if and only if Xi1 = Xi2 = …. = Xin, then the ratio
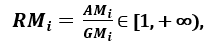
can be used as a dispersion measure. Higher dispersion implies a higher value of Ri, thus a more relevant feature. Conversely, when all the feature samples have (roughly) the same value, Ri is close to 1, indicating a low relevance feature.’ [1]
Wrapper Methods
Wrappers require some method to search the space of all possible subsets of features, assessing their quality by learning and evaluating a classifier with that feature subset. The feature selection process is based on a specific machine learning algorithm we are trying to fit on a given dataset. It follows a greedy search approach by evaluating all the possible combinations of features against the evaluation criterion. The wrapper methods usually result in better predictive accuracy than filter methods.
Let’s, discuss some of these techniques:
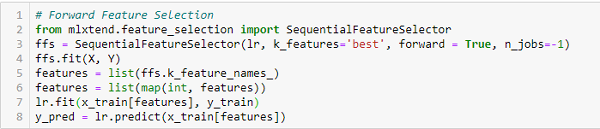
Forward Feature Selection
This is an iterative method wherein we start with the performing features against the target features. Next, we select another variable that gives the best performance in combination with the first selected variable. This process continues until the preset criterion is achieved.
Backward Feature Elimination
This method works exactly opposite to the Forward Feature Selection method. Here, we start with all the features available and build a model. Next, we the variable from the model, which gives the best evaluation measure value. This process is continued until the preset criterion is achieved.

This method, along with the one discussed above, is also known as the Sequential Feature Selection method.
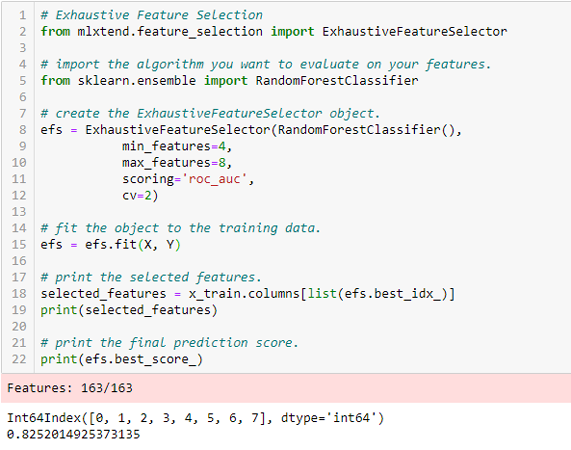
Exhaustive Feature Selection
This is the most robust feature selection method covered so far. This is a brute-force evaluation of each feature subset. This means it tries every possible combination of the variables and returns the best-performing subset.
Recursive Feature Elimination
‘Given an external estimator that assigns weights to features (e.g., the coefficients of a linear model), the goal of recursive feature elimination (RFE) is to select features by recursively considering smaller and smaller sets of features. First, the estimator is trained on the initial set of features, and each feature’s importance is obtained either through a coef_ attribute or a feature_importances_ attribute.
Then, the least important features are pruned from the current set of features. That procedure is recursively repeated on the pruned set until the desired number of features to select is eventually reached.’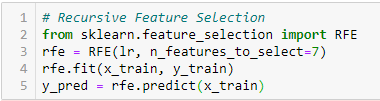
Embedded Methods
These methods encompass the benefits of both the wrapper and filter methods by including interactions of features but also maintaining reasonable computational costs. Embedded methods are iterative in the sense that takes care of each iteration of the model training process and carefully extract those features which contribute the most to the training for a particular iteration.
Let’s discuss some of these techniques here:
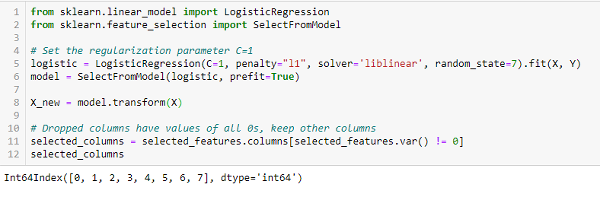
LASSO Regularization (L1)
Regularization consists of adding a penalty to the different parameters of the machine learning model to reduce the freedom of the model, i.e., to avoid over-fitting. In linear model regularization, the penalty is applied over the coefficients that multiply each predictor. From the different types of regularization, Lasso or L1 has the property that can shrink some of the coefficients to zero. Therefore, that feature can be removed from the model.
Random Forest Importance
Random Forests is a kind of Bagging Algorithm that aggregates a specified number of decision trees. The tree-based strategies used by random forests naturally rank by how well they improve the purity of the node, or in other words, a decrease in the impurity (Gini impurity) over all trees. Nodes with the greatest decrease in impurity happen at the start of the trees, while notes with the least decrease in impurity occur at the end of the trees. Thus, by pruning trees below a particular node, we can create a subset of the most important features.

Conclusion
We have discussed a few techniques for feature selection. We have purposely left the feature extraction techniques like Principal Component Analysis, Singular Value Decomposition, Linear Discriminant Analysis, etc. These methods help to reduce the dimensionality of the data or reduce the number of variables while preserving the variance of the data.
Apart from the methods discussed above, there are many other feature selection methods. There are hybrid methods, too, that use both filtering and wrapping techniques. If you wish to explore more about feature selection techniques, great comprehensive reading material, in my opinion, would be ‘Feature Selection for Data and Pattern Recognition’ by Urszula Stańczyk and Lakhmi C. Jain.
Key Takeaways
- Understanding the importance of feature selection and feature engineering in building a machine learning model.
- Familiarizing with different feature selection techniques, including supervised techniques (Information Gain, Chi-square Test, Fisher’s Score, Correlation Coefficient), unsupervised techniques (Variance Threshold, Mean Absolute Difference, Dispersion Ratio), and their classifications (Filter methods, Wrapper methods, Embedded methods, Hybrid methods).
- Evaluating the performance of feature selection techniques in practice through implementation.
Frequently Asked Questions
Q1. What is a feature selection method?
A. A feature selection method is a technique in machine learning that involves choosing a subset of relevant features from the original set to enhance model performance, interpretability, and efficiency.
Q2. What is the feature selection principle?
A. The feature selection principle centers on identifying and retaining the most informative features while eliminating redundant or irrelevant ones. This optimization aims to enhance model accuracy and efficiency.
Q3. Is PCA used for feature selection?
A. No, PCA (Principal Component Analysis) is primarily a dimensionality reduction technique, not a feature selection method. While it reduces features, it doesn’t consider the individual importance of features for prediction.
Q4. What are the typical steps in feature selection?
A. Typical steps in feature selection include understanding the dataset and problem, choosing a relevant feature selection method, evaluating feature importance, selecting a subset of features, and assessing and validating model performance with the chosen features.
Aman Gupta
17 Jul, 2024








Kindly share dataset of above code
Hello I was just wondering if you know anyone who can help me with one of my Applied Machine Learning assignment. Thanks Bijal
It two distinct methods gives different set of features as the most important, say 5 features from the dataset. How to determine which exactly are the most important features in this case of contradiction
Which is the best method in case we have 7-8 numerical variables and 7-8 categorical variables for binary classification?
Use filter methods like Chi-square for categorical features, Information Gain for relevance, Fisher's Score for ranking, and Correlation Coefficient for relationships which are typically statistical methodologies. You can also experiment with wrapper methods like Forward Selection or Recursive Feature Elimination (RFE), and embedded methods like LASSO and tree-based models, e.g. Random Forest for optimal feature selection. Usually embedded methods are more commonly used often.