Overview
- Writing what you learn is at the core of Analytics Vidhya and we regularly engage with the community and encourage them to be guest authors on our blog
- Here is a list of top 10 Guest Authors on Analytics Vidhya this year
Introduction
Analytics Vidhya has always prided itself on sharing high-quality comprehensive articles on a variety of topics related to ML, DS, and AI.
Be it articles dealing with the implementations of latest models, or dealing with covering the basic concepts, or the latest trends, our writers have always been at the forefront sharing our knowledge, and experience. The year 2020 was no different. We published over 500 articles and this number includes plentiful articles written by our Guest Authors.

Coming from various backgrounds and domains, our list of Guest Authors is an impressive roster of industry professionals and thought leaders who cover a wide range of topics including fundamentals of analytics right up to advanced deep learning models. These authors are extremely popular among our readers and we always look forward to what they will be writing next.
In this article, I highlight the top 10 Guest Authors on our blog this year. These are in alphabetical order by their username.
1. Arka Ghosh
We start off with an author who has written a couple of articles on different tools as well as how to start your DS career. All of Arka Ghosh articles combined have over 30K views!
What is the difference between Artificial Intelligence, Machine Learning, and Deep Learning? Which are the various roles in the DS industry? What are some tools and resources to start my DS career?
I am sure most of you who want to start their DS journey have these questions. This article by the author answers these questions and more in detail, using an example and easy-to-understand graphics. This article serves as a one-stop guide to starting your ML journey: How to Build a Career in Data Science and Machine Learning?

While we usually stick to either scikit-learn and pandas for our machine learning models. However, there are other libraries we can use to complete specific tasks more efficiently than the generic ones above.
His 2nd article deals with implementing Linear Regression. Too simple? Well, what makes it different is that the author implements linear regression using H2O’s AutoML tool and demonstrates the end-to-end process from loading the data to presenting the predictions. You can also learn about how to build AutoML models in this article: Exploring Linear Regression with H20 AutoML(Automated Machine Learning)
The final article by this author covers the Anomalize library in R for anomaly detection. The author has not only explained using this library but taken up an entire case-study to explain and implement anomaly detection in Time Series: A Case Study To Detect Anomalies In Time Series Using Anomalize Package In R
2. Ekta Shah
Our next author is well-known among our readers for the diversity of topics she chooses to write on. Mainly dealing with advanced machine learning concepts, she always uses interesting industry-level problems to explain them.
For instance, her article on Image Classification not only covers the basic code for using pre-trained models for the task but also to develop an Android app that uses such a model. This comprehensive article covers scraping images from the internet, preparing the image data, building a deep learning model based on VGG-16, and integrating a custom-built UI into an Android App: Build an End to End Image Classification/Recognition Application

The next article by this author deals with Stock price Prediction. While we come across various ways of dealing with Time Series tasks right from regression to ARIMA and to deep learning models like LSTMs, this article uses Reinforcement learning for the same. This is a totally new approach to solving a time series forecasting problem that is seldom used with comparable performance to the above methods. Check out this article here along with the Python code to implement it: Predicting Stock Prices using Reinforcement Learning (with Python Code!)
While the above articles were on Computer Vision and Reinforcement Learning, her latest article is from the NLP domain. Implementing the task of text summarization, the author now takes up scraping a Wikipedia Page(on reinforcement learning, no less) and using the nltk library to summarize this page. In the process, the article implements web scraping, text preprocessing, and summarisation: Tired of Reading Long Articles? Text Summarization will make your task easier!
3. Kavish Goyal
The net author is one of our regular writers for our blogathons. His articles always cover interesting problems and provide easy and short to-do guides on how to get the problem solved.
His 1st article deals with one of the most time-consuming tasks in the DS process- data exploration. No matter how large your dataset is, this is one task one simply cannot ignore and have to perform to get an idea of the data provided. However, using just the basic tools of pandas, numpy and a couple of visualization libraries is too tedious and inefficient. What if there were a tool to make data exploration easier and one that we could integrate with Jupyter Notebooks as well? Well, this is what the ‘dtale’ library does. The article takes up a dataset and explains how to use the ‘dtale’ library in your Notebook for interactive data exploration: Data Exploration with the dtale Library in Python

While there are blogs and articles aplenty dealing with how to build machine learning and deep learning models but have you ever wondered what comes before and after model building? In the industry, datasets are not provided to us on a plate, ready to build our models on. Oftentimes, we have to collect the data ourselves. This is especially applicable when you want image data. There are not many image datasets available that you can use to practice your Computer Vision tasks. However, the internet is a treasure trove of images, and we can leverage this huge resource to get the images we want ourselves. Thus, this article by the author implements image scraping using the popular Selenium library in Python: Web Scraping Iron_Man Using Selenium in Python
Similarly, it is not merely enough to build a model and generate predictions on a test dataset. The important part is serving the prediction results in ways that can be further used to make decisions such as web apps. However, if you have a model ready, you need not consult a web developer to build a web application for it. The latest article by Kavish Jain demonstrates how we can use Streamlit, a popular Python framework to deploy our model: Streamlit Web API for NLP: Tweet Sentiment Analysis
4. Raji Rai
The next Guest Author in this list also covers a wide range of topics in his articles catering to different audiences.
For beginners and professionals who want to become data scientists, it is often much easier to handle roles of data analyst or business analyst to get used to dealing with different types of data. However, there various opinions on how to become a data analyst. This comprehensive article covers all aspects of becoming a successful data analyst with useful resources to get you started: A Quick Guide to Become a Data Analyst.

What if you could create your own version of Alexa or your own personal digital assistant? Don’t worry, it is not as daunting as it sounds. This article provides the complete step-by-code to create your own desktop assistant powered by your voice: Build Your Own Desktop Voice Assistant in Python
So the next time you check the weather on your mobile, ask your own voice-based assistant first!
The importance of model deployment in the machine learning process can be gauged by the number of articles showing how to put your model into production using different tools and libraries is much needed in the domain of computer vision where you can show whether the image you uploaded is that of a dog or cat instantly. This article uses the fastai(v2) library and iPython widgets to classify x-ray images into Covid Positive or Covid-Negative: Develop and Deploy an Image Classifier App Using Fastai
5. Maanvi
One of our most prolific authors, Maanvi is fast becoming one of our regular contributors to the blogathons. For instance, Maanvi has submitted 5 well-researched and diverse articles over the last couple of months with each article exploring different concepts in R and Python.
Starting with the fundamentals of statistics, this article explains statistical modelling in great detail along with the definitions and key concepts of building statistical models: All about Statistical Modeling
It is a common misconception that machine learning involves collecting the data, cleaning it, feature engineering, model building, and prediction. However, that is not the case. There are quite a few statistical steps involved in between as well, such as Power Analysis. Power Analysis is a 4-step process that helps you perform a sanity-check on your data. This article illustrates this concept using Python: Statistics for Beginners: Power of “Power Analysis”
Are you more a proponent of Bayesian statistics over the frequentist approach? If so, conditional probabilities and Bayesian networks are your friends. More specifically, Probabilistic Graphical Models(PGM) form the base of making predictions using graphs and networks. This article covers PGM in great detail along with R code: Complete R Tutorial To Build Probabilistic Graphical Models!
Preparing your data before extracting and building features from it is one of the most vital tasks in the ML process. Occasionally, the data that we have collected is spread out across different files containing different features. It is not merely enough to just load these files and combine them into a single dataframe – we need to keep it consistent and remove the redundancy as well. This article demonstrates data preparation when it is split into different files: Tutorial to data preparation for training machine learning model
For beginners who have just started learning Python, data exploration can be a challenging task. It can be difficult to recollect and use a huge number of available functions to deal with different types of data. This article describes data exploration using Python on a dataset in easy-to-understand language and code: A Comprehensive Guide to Learn Data Exploration in Python!
6. Pattabhiraman Srinivasan
Another of our highest contributors, he regularly churns out high-quality articles dealing with deep learning and statistics.
For instance check out his article on Data Exploration: Interpreting P-Value and R Squared Score on Real-Time Data – Statistical Data Exploration
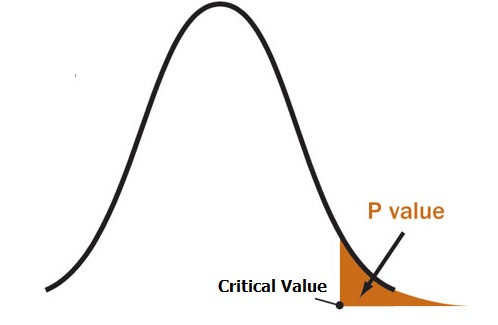
While it may look like just another run-of-the-mill articles on data exploration, the author particularly highlights how to use statistical measures and techniques at this stage. In fact, we can derive the majority of insights at this step itself without even proceeding to build a predictive model on the data.
Have you thought of applying Python to improve call centers? It can be extremely helpful for customer service representatives who have to deal with thousands of calls every day, sometimes on the same issues but worded differently. This article uses plain Python code without any complicated model-building to create an extremely efficient log of issues and their corresponding resolutions by parsing large files for the critical baking sector: Modernize Support Logs Using Simple Python Commands
A continuation of the previous article, the author now uses NLP techniques to look up similar issues being raised and how to identify high-priority issues: NLP Applications in Support Call Centers
It is really fascinating to study how ML professionals use a combination of ML and DL models in their decision-making process.
If using NLP wasn’t impressive enough, the author now ventures into transfer learning and Generative Adversarial Networks(GANs). This article explains the fundamental concepts behind GANs, but also uses them to generate new images from a custom image dataset: Training StyleGAN using Transfer learning on a custom dataset in google colaboratory
Moving on to one of the most interesting articles in this list – dealing with Unsupervised Deep Learning. The concept of Autoencoders is a compelling one. They basically ‘learn’ to encode data in an unsupervised manner and thus are typically used for extracting and reducing features in a dataset. This article demonstrates using Autoencoders for the same purposes in a real-life energy sector problem: Deep Unsupervised Learning in Energy Sector – Autoencoders in Action
7. Sagnik Banerjee
Like a few authors in this list, Sagnik Banerjee is also all about the tools. This author’s straightforward style of explaining practical concepts has been well-received by our community.
Time Series is one of the most common problems we come across in hackathons and in the industry. In fact, it is even a part of interview questions for ML roles across the board. There are various techniques to deal with time series forecasting like ARIMA, RNNs, etc. However, it is Facebook’s Prophet library that is fast becoming the preferred tool to forecast time series. This article provides a clear and concise implementation of the Prophet library using Python: Time Series Forecasting using Facebook Prophet library in Python

Similar to other articles that you will find in this list, Sagnik Banerjee’s next article also deals with Machine Learning model deployment. However, this time it is using the popular Microsoft Azure framework and Flask. The idea is to create a web application that can run 24 x 7 to generate predictions: How to Deploy Machine Learning models in Azure Cloud with the help of Python and Flask?
Feature engineering is one of the most essential steps in the ML process. You simply cannot skip this step and it is imperative to get the best possible features out of the data we have to get the best possible predictive model. Feature selection is one of the steps in feature engineering where we select the best possible combination of features. This excellent article describes the popular types of features selection techniques that filter out the redundant features: Most Common Feature Selection Filter Based Techniques used in Machine Learning in Python
8. Neha Seth
Here we have an author who takes up the building blocks of machine learning models and explains them meticulously using examples and code each step of the way.
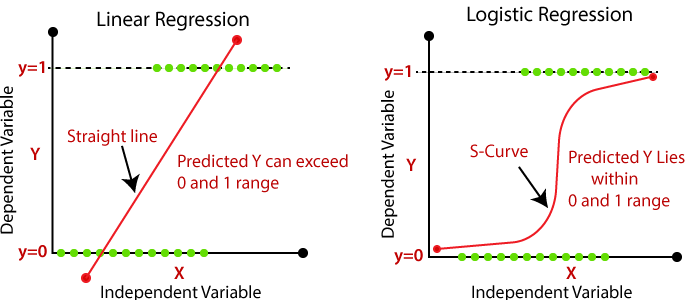
Generalized Linear Models(GLMs) are widely used in the industry despite the dee learning boom. Cheaper to build and easy to explain, they are the go-to models for building benchmarks in academia as well. In the case of classification, logistic regression, though popular can be quite intimidating for beginners. This article provides a complete guide to logistic regression along with the math behind it and also Python code: Demystification of Logistic Regression
Similarly, Entropy is one such term that we hear day-in and day-out in the case of decision trees and tree-based models. But what is Entropy and what is the intuition behind using it in tree models? This article provides a thorough, yet an easily understandable guide to Entropy and its usage: Entropy – A Key Concept for All Data Science Beginners
Dimensionality reduction is a much-needed step when we are dealing with large datasets. Working with thousands of features without reducing them can lead to poor-fitting models. Thus, using as few features as possible without losing too much information is essential for the ML process. Principal Component Analysis(PCA) is one of the most widely-used techniques for Dimensionality reduction. This comprehensive article explains PCA using interesting examples and clear explanations: An end-to-end comprehensive guide for PCA
9. Sreenath
I really like the topics Sreenath chooses to write his articles on. They are always engaging, dealing with new concepts and tools.
For instance, how many of you were acquainted with the idea of reservoir sampling? I am pretty sure that not many of us knew this simple technique of obtaining smaller chunks of datasets from a huge ‘reservoir’ of big data. It uses statistical techniques of accomplishing this. This article by Sreenath provides a comprehensive guide to Reservoir Sampling and provides the statistical intuition behind it: Big Data to Small Data – Welcome to the World of Reservoir Sampling
From statistics, let us move on to math. Most of the time when we are using linear regression, we hardly use the barebones model. More often than not, we combine regularisation with linear regression to get the best-fit equation for our data. Amongst regularisation, lasso and ridge regularisation are the most common types. However, what is the difference between the two? This article explains the math behind the two techniques and how they actually perform feature selection: Lasso Regression causes sparsity while Ridge Regression doesn’t! – Unfolding the math

Once we obtain the benchmark results for our model, the next step is Hyperparameter Tuning. It is Hyperparameter tuning that pushes our accuracy from 90% to 98% or our RMSE from 0.1 to 0.002. This finetuning of parameters can be a very tedious step when we are dealing with when we are using models with a large number of parameters like the Random Forest. It is simply impossible to try out various combinations of parameters by trial and error here. This article explores Optuna, a recent and lesser-known library that automatically generates the best possible combinations of parameters and also generates plots to visualize them: Hyperparameter Tuning using Optuna
Didn’t I mention earlier the diversity of topics that Sreenath chooses to write on? His most recent article tackles reinforcement learning. This concise article provides a really simple and intuitive explanation of reinforcement learning and how to use the Markov mathematical model to represent reinforcement learning: Getting to Grips with Reinforcement Learning via Markov Decision Process
10. Vetrivel PS
Finally, I would like to include one of the most well-received authors among our readers. Vetrivel PS is one of the few authors who has won 2 awards in the same blogathon! An experience DS professional who is also a Kaggle Expert published 2 popular articles with us.
Participating in Hackathons is one of the most crucial prerequisites for building your DS profile. Achieving a good rank in hackathons could be the difference in your resume among hundreds of other resumes that could give you a boost.
However, it can be intimidating for beginners to start participating in hackathons and Vetrivel PS addresses this very issue in his awesome article on how achieved Rank 4 out of 3000 submissions in one of our hackathons: Ultimate Beginners Guide to Breaking into the Top 10% in Machine Learning Hackathons

Not only this, his other articles deals specifically with classification problems in hackathons and shares his approach of featured in the top 10% amongst 20,000 participants in Hackathon involving a classification problem: Ultimate Beginner’s Guide to Win Classification Hackathons with a Data Science Use Case
End Notes
We read about our top 10 Guest Authors of 2020. Each one of these authors has been an inspiration for us and our readers in sharing their knowledge and skills. We can also get an idea of the topics that are sought-after by the general audience. With a healthy mix of beginner, intermediate, and advanced level articles, it is clear that the demand for DS professionals is growing across all domains.
Who was your favorite Guest Author of 2020? Share your feedback and answers below!






