Introduction
Data science is not a choice anymore. It is a necessity.
2020 is almost in the books now. What a crazy year from whichever standpoint you look at it. A pandemic raged around the world and yet it failed to dim the light on data science. The thirst to learn more continued unabated in our community and we saw some incredible developments and breakthroughs this year.
From OpenAI’s mind-boggling GPT-3 framework to Facebook’s DETR model, this was a year of incremental growth and of giant leaps. Whether that was in machine learning or natural language processing (NLP) or computer vision, data science thrived and continued to become ubiquitous around the world.

As is our annual tradition, we are back with our review of the best developments and breakthroughs in data science in 2020 and we also look forward to what you can expect in 2021. There’s a lot to unpack here so let’s get going!
Table of Contents
- Developments in Natural Language Processing (NLP) in 2020
- Developments in Computer Vision(CV) in 2020
- Developments in Reinforcement Learning in 2020
- The Rise of MLOps
- Data Science Community came together to fight COVID-19
- Analytics Vidhya’s Take on Machine Learning Trends in 2020
Developments in Natural Language Processing (NLP) in 2020
NLP does not seem to take a break from taking leaps year on year
Like last year, we saw some major developments in 2020 too. We have listed down some of them in this section.
If you’re a newcomer to NLP and want to get started with this burgeoning field, I recommend checking out the below comprehensive course:
Let’s have a look at it.
Release of GPT-3
![]()
OpenAI released a new successor to its Language Model- GPT-3. This is the largest model trained so far, with 175 billion parameters. The authors trained multiple model sizes, varying from 125 million parameters to 175 billion parameters, in order to get the correlation between model size and benchmark performance.
The architecture of GPT-3 is Transformers-based, similar to GPT-2, including the modified initialization, pre-normalization, and reversible tokenization described therein. The only exception is that it uses alternating dense and locally banded sparse attention patterns in the layers of the transformer, similar to the Sparse Transformer.
The GPT-3 though has its limitations but is still one of the Major Breakthroughs in NLP. To give an example, the fake news generated by GPT-3 is so similar to the real ones that it is hard to distinguish. Some results show that only 50% of fake news could be detected.
We are simply amazed by this giant leap in Language Models.
FacebookAI’s State-of-the-Art Open Source Chatbots
![]()
Claiming to be better than Google’s Meena, Facebook released its State-of-the-Art, open-sourced Chatbot, BlenderBot. Its a result of many years of result and is equipped with a combination of diverse conversational skills that encompasses empathy, knowledge, and personality.
This chatbot has improved decoding techniques, the novel blending of skills, and a model with 9.4 billion parameters, which is 3.6x more than the largest existing system.
The recipe of the chatbot includes a special focus on Scale, blending skills, and generation strategies. It is so better, that even the human evaluators can’t deny its supremacy.
You can view the full model, code, and evaluation set-up here.
OpenAI releases its API for Public Access
![]()
OpenAI released its new API in the middle of this year. The API lets you use the company’s AI tools on “virtually any English language task.” The API gives access to the firm’s GPT-3 and lets you perform tasks like- semantic search, summarization, sentiment analysis, content generation, translation, and more — with only a few examples or by simply letting know your task in English.
The aim of this is to solve the distributed systems problem and in turn, increase the focus of the users on their Machine Learning research. The API was designed to be both simple and flexible increase in the productivity of the users.
You can read more about it here.
Or you can simply try the API here.
Developments in Computer Vision(CV) in 2020
DETR: End-to-End Object Detection with Transformer was released

DETR solves object detection problem as a direct set prediction problem, unlike traditional computer vision techniques. Facebook announced DETR as “an important new approach to object detection and panoptic segmentation”. It includes a set-based global loss, which forces unique predictions using bipartite matching, and a Transformer encoder-decoder architecture.
DETR completely varies in architecture as compared to previous object detection systems. It is the first object detection framework to successfully integrate Transformers as a central building block in the detection pipeline. DETR equalizes in performance with State-of-the-Art methods while completely streamlining the architecture.
You can learn more about DETR here.
FasterSEG was released
FasterSeg is an automatically designed semantic segmentation network with not only state-of-the-art performance but also faster speed than current methods.

FasterSeg supports multi-resolution branches, has a fine-grained latency regularization alleviating the “architecture collapse” problem. Moreover, FasterSeg achieves extremely fast speed (over 30% faster than the closest manually designed competitor on CityScapes) and maintains competitive accuracy.
You can view the code and full documentation here.
On-Device Computer Vision Models
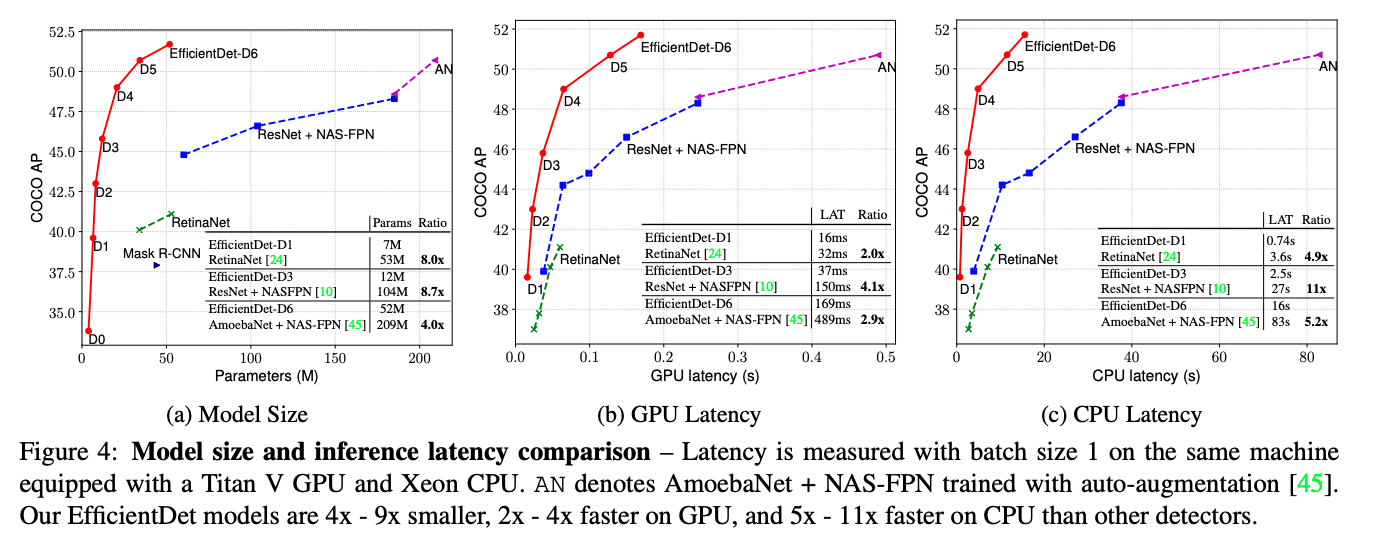
The computer vision community is on the path to make its algorithm more efficient so that they can function on very small devices and sensors. One of the prominent architectures at the forefront of this strive for efficiency is EfficientDet-D7.
It has been reported that EfficientDet-D7 achieves state-of-the-art on COCO object detection task with 4-9x fewer model parameters than the best-in-class and can run 2-4x faster on GPUs and 5-11x faster on CPUs than other detectors.
You can learn more about it here.
Detectron2 – A PyTorch-based modular object detection library was released by Facebook

Detectron2 is a complete rewrite of Detectron that started with maskrcnn-benchmark. The platform is now implemented in PyTorch. The new and more modular design makes Detectron2 flexible and provides faster training on single or multiple GPUs.
Detectron2 contains high-quality implementations of state-of-the-art object detection algorithms, including DensePose, panoptic feature pyramid networks, and numerous variants of the pioneering Mask R-CNN model family also developed by FAIR. Its extensible design facilitates easy implementation of cutting-edge research projects without having to fork the entire codebase.
Additionally, the model trains much faster, and models can be exported to torchscript format or caffe2 format for deployment.
You read about it in detail here.
DeepMind’s AlphaFold Solves the Protein Folding Problem
One of the oldest and most challenging problems of biology was to predict the unique 3-D structure or shape of proteins. The shape of proteins is determined by how the chains of Amino Acid fold and this also determines what the protein will do.
DeepMind’s AlphaFold system has been recognized as a solution to this problem by organizers of the biennial Critical Assessment of protein Structure Prediction (CASP).
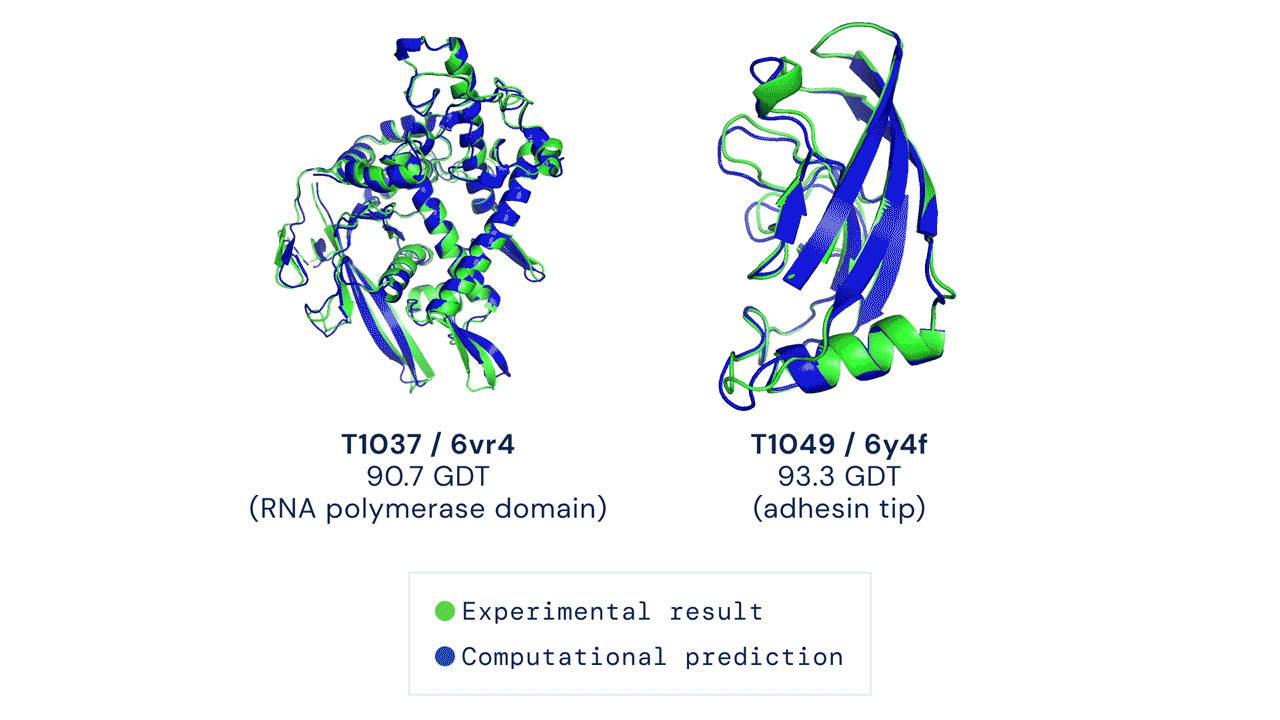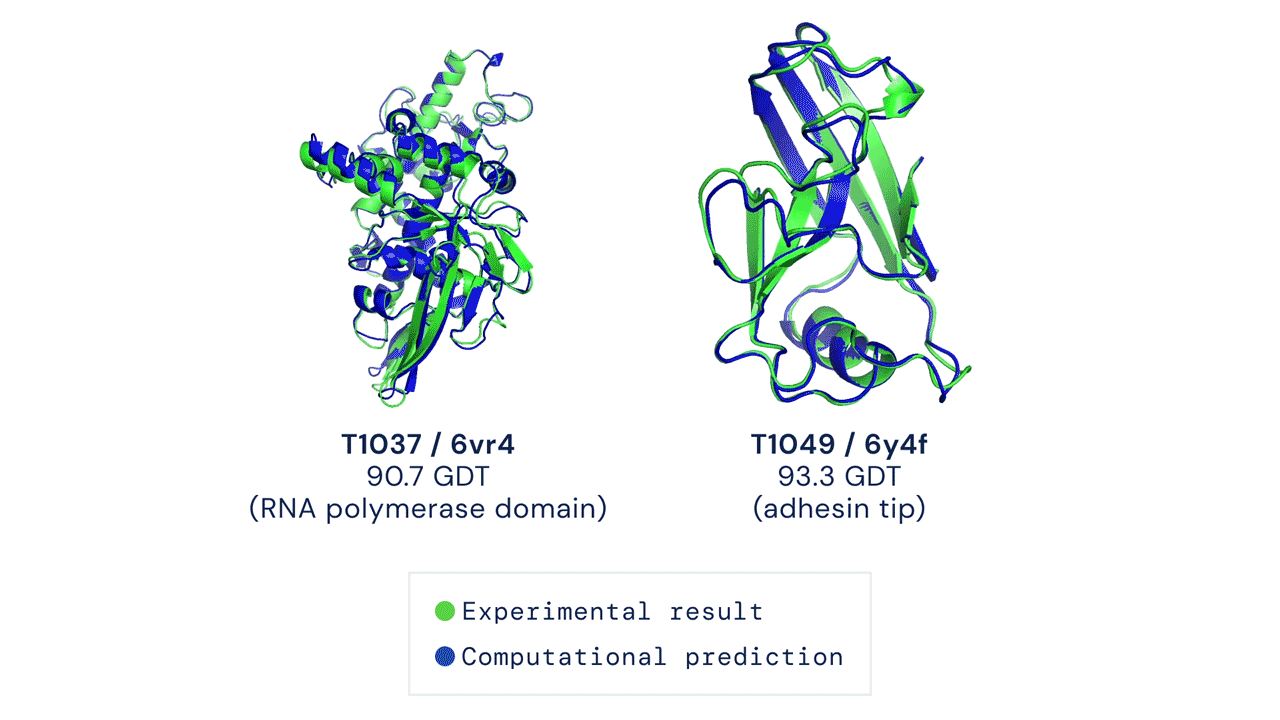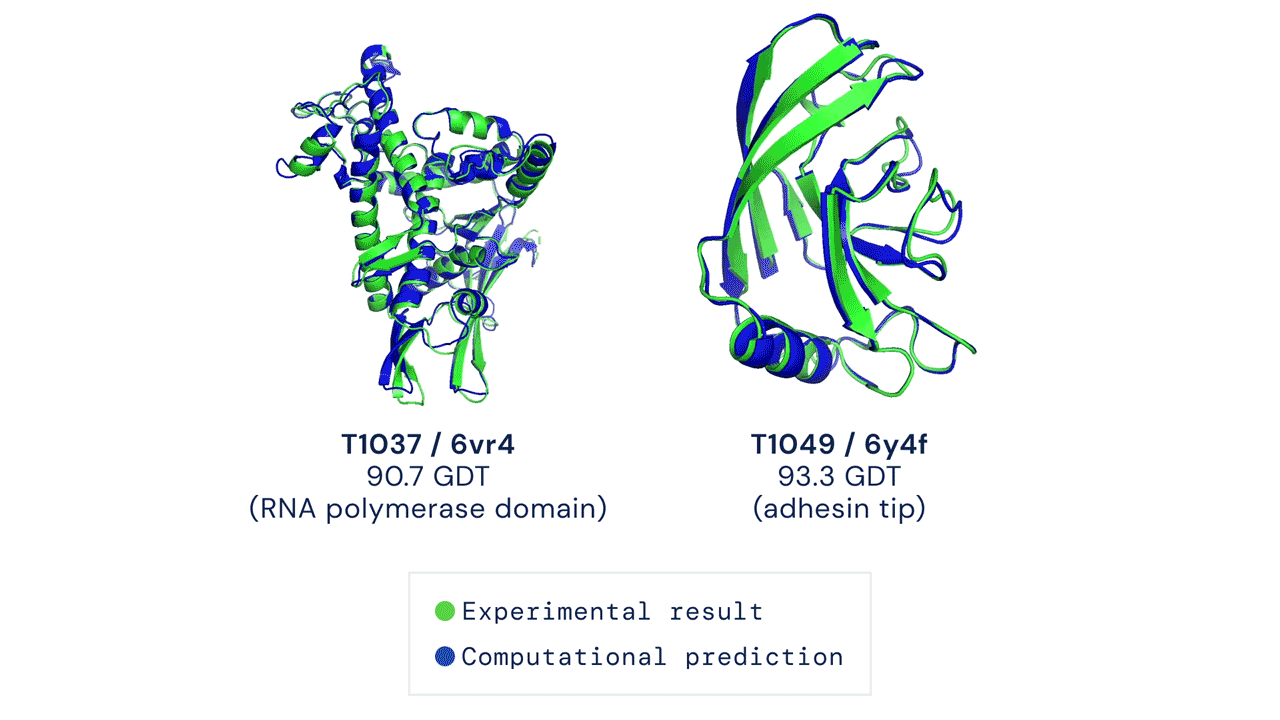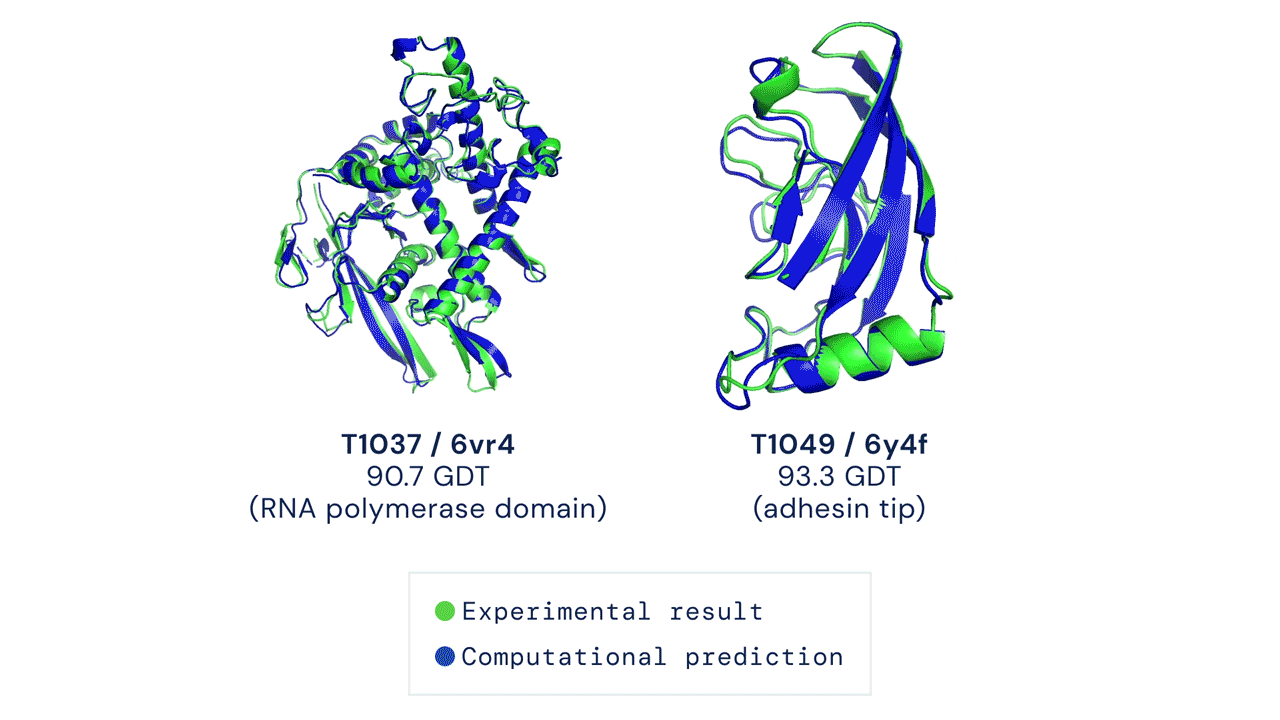
Since the shape of the protein determines its functions, predicting the shape will help us determine what and how it works. This is a giant leap in the scientific community and has the potential to solve global problems like breaking down industrial waste and developing treatments for diseases quickly.
Developments in Reinforcement Learning in 2020
This reinforcement learning aspect was a little slow in terms of breakthroughs in 2020, but there one development that we just cannot miss as this has huge potential in the way we deal with problems is the creation of Agent57.
Agent57 Scores Above the Human Baseline
After the proposal of The Arcade Learning Environment (aka Atari57) as an evaluation set of 57 classic Atari video games which pose a broad range of challenges for an RL agent to learn and master, there has rarely been any RL program that beat it.

Source: DeepMind
Enter Agent57 from DeepMind! It has become the first reinforcement learning (RL) agent to top human baseline scores on all 2600 games in the Atari57 test set.
Agent57 combines an algorithm for efficient exploration with a meta-controller that adapts the exploration and long vs. short-term behaviour of the agent.
The ultimate goal here for DeepMind was not to create an algorithm to perform better at games but to use games to adapt itself and excel in other broad range of tasks.
The Rise of MLOps
MLOps is a relatively new concept in the data science domain. So let us give clarity to you on that in brief.
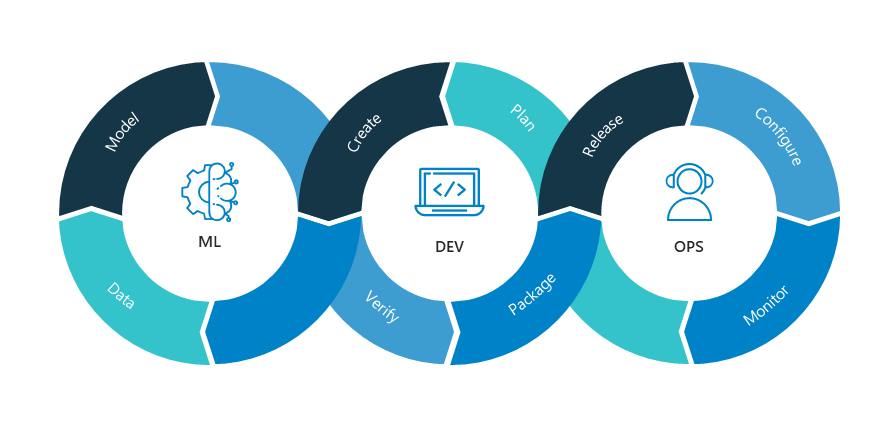
MLOps is the meeting point of data scientists with the operations department ensuring to ensure the best practical applications of models created. In simple terms, we can refer to MLOps as DevOps for Machine Learning.
“Its about how to best manage data scientists and operations people to allow for the effective development, deployment and monitoring of models.”- Forbes
MLOps is on the rise, suggesting that the industry is moving from how to build models(Technology R&D) to how to run models(operations). Research says 25% of the top-20 fastest-growing GitHub projects in Q2 2020 ML infrastructure, tooling, and operations. Even Google Search traffic for “MLOps” is now on a rise for the first time.
Data Scientist’s on the Problems of the Data Science Domain
As per the ‘State of Data Science 2020’ by Anaconda, 2 of the big questions that the data scientists are concerned about is the impact of bias from data and the impacts on individual privacy.
The social impact of bias in data and models is a long-standing problem in Data Science. Though there are many scientifically proven methods that can reduce the sample or training data, eliminating it is still a dream far away. And if unchecked, the bias in data and models will to decisions that may have an irreversible adverse effect on society.
Similarly, the line between data collection and data privacy is thin. There are many organizations that collect data that they do not even need for the product to function for future purposes. This again raises the questions of ethical practice and trust.
Other problems are highlighted below-

Data Science Community came together to fight COVID-19
The White House asked the Kaggle community to come to the rescue. The data was so much and so diverse that it required all brains within the community to apply their thoughts and knowledge to it.
Let’s see how the community leveraged the data science techniques to solve different problems related to the pandemic.
-
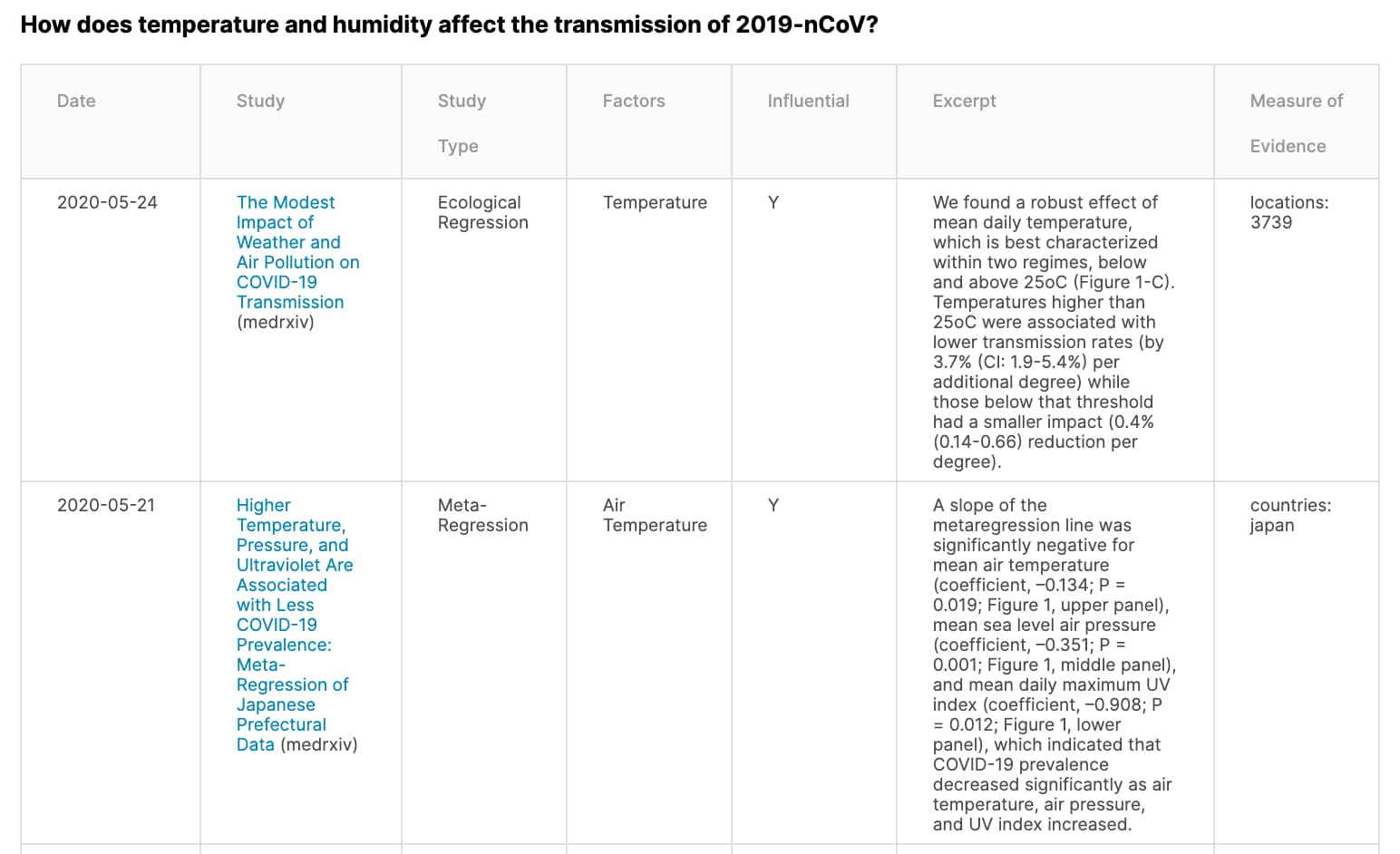
NLP to go through research papers
The volume at which research papers were being published on a daily basis was just unfathomable.
This is when the white house asked Kaggle to launch an NLP challenge to find answers to 9 key questions that were drawn from both the National Academies of Sciences, Engineering, and Medicine’s Standing Committee on Emerging Infectious Diseases research topics and the World Health Organization’s R&D Blueprint for COVID-19.
You can view the dataset here. This dataset was created by the Allen Institute for AI in partnership with the Chan Zuckerberg Initiative, Georgetown University’s Center for Security and Emerging Technology, Microsoft Research, IBM, and the National Library of Medicine – National Institutes of Health, in coordination with The White House Office of Science and Technology Policy.
The results of this exercise were double-checked and widely used by medical experts. Preliminary tables are generated by Kaggle notebooks that extract as much relevant information as possible. These tables showed excerpts from the originally published article itself.
Here is an example below- -
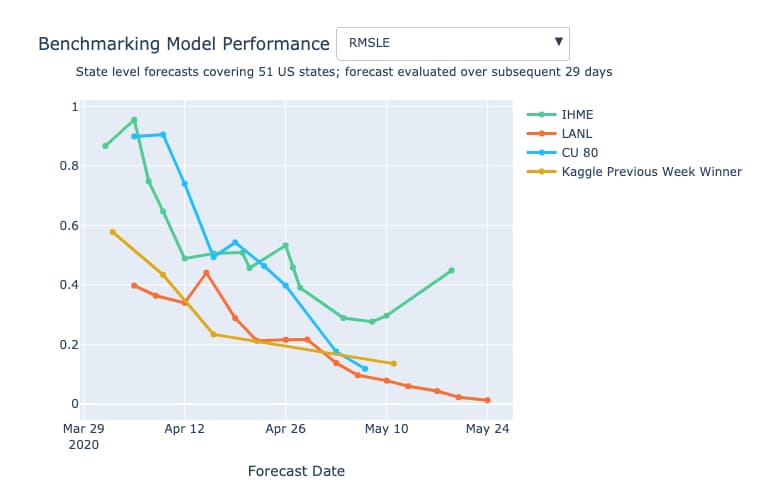
Time Series Forecasting
Kagge started hosting a series of global transmission forecasting competitions. The goal is to predict the total number of infections and fatalities for various regions—with the idea being that these numbers should correlate well with the actual number of hospitalizations, ICU patients, and deaths—as well as the total number of scarce resources that will be needed to respond to the crisis.
The winning solutions performed at par with the epidemiological models with respect to RMLSE as you can see in the plot below-
Participants were able to predict well-using ensemble mode techniques like XGBoost and LightGBM and have also identified sources of external data, that when incorporated gives a better prediction.
Analytics Vidhya’s Take on Machine Learning Trends in 2020
1. The number of jobs in the Data Science Domain will continue to rise in 2021. Not only due to the rising volume of data, but the post-covid world will have lots of new consumer habits plus the requirement of data scientists is set to increase in old-guard industries such as manufacturing, mining, etc.
2. Facebook’s PyTorch to outpace Google’s TensorFlow indicating use in production in the coming year. Research shows that there has been a decrease in the use of TensorFlow and shifting to PyTorch. Also of many conferences that reveal the framework used three-fourths use PyTorch. You can read the research in the following reports-
- https://thegradient.pub/p/cef6dd26-f952-4265-a2bc-f8bfb9eb1efb/
- http://horace.io/pytorch-vs-tensorflow/
- https://paperswithcode.com/trends
3. Python to get a better stronghold in 2021
There is no doubt in the fact that Python is currently the most preferred language and there is no language that is competing with it. To further be the dominant language, it has already rolled out Python 3.9 in October with many improvements, and Python 3.10 already in development and set to release in early 2021.
4. Redundancy of models based on Pre-Covid Data
The cultivation of new habits and change in consumer behavior is going to be the key to capture success in the post-covid world. The validity of models based on pre-Covid data is going to fall.
5. Data Marketplaces will be on a rise
Covid-19 will be a big game-changer in terms of the habits of the consumers. That means more new and diverse kinds of data never collected before will be collected by some organizations which will increase the market for the formal exchange of Data for money.
In the end, we just have one thing to say- “Data Science is here to stay”. In the near future, it will be a part of everyone’s life and directly impact each decision they make.






I agree that MLops is critically needed and on the rise. But I disagree on who will end up being the right operators. It is not operations.
Nice blog. The popularity of large scale deep learning models will peak in 2021; data and energy requirements are simply becoming too high for the trend to continue.
Its really hard to find such amazing content nowadays, it feels really good after reading your post.