The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.
Introduction
Let’s start with a most often used algorithm type for simple output predictions which is Regression, a supervised learning algorithm.
We basically train machines so as to include some kind of automation in it. In machine learning, we use various kinds of algorithms to allow machines to learn the relationships within the data provided and make predictions using them. So, the kind of model prediction where we need the predicted output is a continuous numerical value, it is called a regression problem.
Regression analysis convolves around simple algorithms, which are often used in finance, investing, and others, and establishes the relationship between a single dependent variable dependent on several independent ones. For example, predicting house price or salary of an employee, etc are the most common regression problems.
We will first discuss the types of regression algorithms in short and then move to an example. These algorithms may be linear as well as non-linear.
Table of contents
Linear ML algorithms

Linear Regression
It is a commonly used algorithm and can be imported from the Linear Regression class. A single input variable(the significant one) is used to predict one or more output variables, assuming that the input variable isn’t correlated with each other. It is represented as :
y=b*x + c
where y- dependent variable,x-independent,b-slope of the best fit line that could get accurate output and c -its intercept.Unless there is an exact line that relates the dependent and independent variables there might be a loss in output which is usually taken as the square of the difference between the predicted and actual output, ie the loss function.
When you use more than one independent variable to get output, it is termed Multiple linear regression. This kind of model assumes that there is a linear relationship between the given feature and output, which is its limitation.
Ridge Regression-The L2 Norm
This is a kind of algorithm that is an extension of a linear regression that tries to minimize the loss, also uses multiple regression data. Its coefficients are not estimated by ordinary least squares (OLS), but by an estimator called ridge, which is biased and has lower variance than the OLS estimator thus we get shrinkage in coefficients. With this kind of model, we can reduce the model complexity as well.
Even though coefficient shrinkage happens here, they aren’t completely put down to zero. Hence, your final model will still include all of it.
Lasso Regression -The L1 Norm
It is The Least Absolute Shrinkage and Selection Operator. This penalizes the sum of absolute values of the coefficients to minimize the prediction error. It causes the regression coefficients for some of the variables to shrink to Zero. It can be constructed using the LASSO class. One of the advantages of the lasso is its simultaneous feature selection. This helps in minimizing the prediction loss. On the other hand, we must note that lasso can’t do a group selection, also it selects features before it saturates.
Both lasso and ridge are regularisation methods

Let us go through some examples :
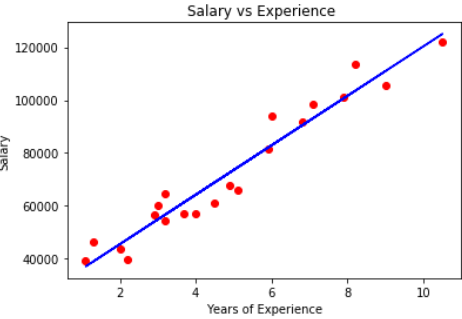
Suppose a data with years of experience and salary of different employees. Our aim is to create a model which predicts the salary of the employee based on the year of experience. Since it contains one independent and one dependent variable we can use simple linear regression for this problem.
Non-Linear ML algorithms
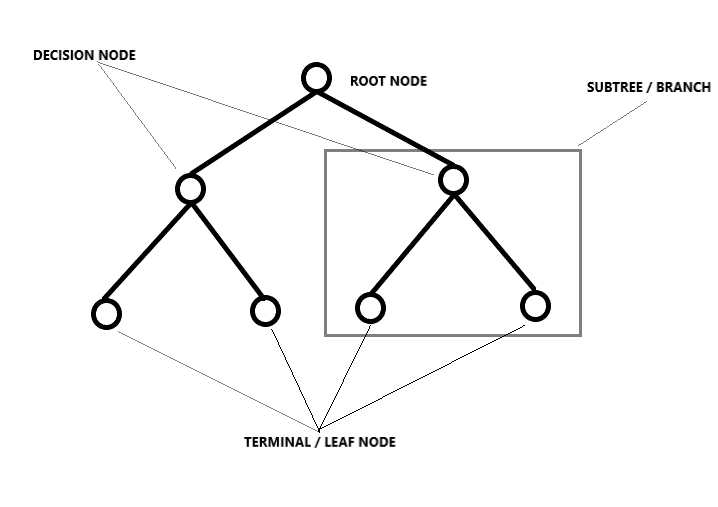
Decision Tree Regression
It breaks down a data set into smaller and smaller subsets by splitting resulting in a tree with decision nodes and leaf nodes. Here the idea is to plot a value for any new data point connecting the problem. The kind of way in which the split is conducted is determined by the parameters and algorithm, and the split is stopped when the minimal number of information to be added reaches. Decision trees often yield good results, but even if any slight change in data occurs, the whole structure changes, meaning that the models become unstable.
Let us take a case of house price prediction, given a set of 13 features and around 500 rows, here you need to predict the price for the house. Since here you have a considerable number of samples, you have to go for trees or other methods to predict values.
Random Forest
The idea behind random forest regression is that in order to find the output it uses multiple Decision Trees. The steps involved in it is:
– Pick K random data points from the training set.
– Build a decision tree associated with these data points
– Choose the number of trees we need to build and repeat the above steps(provided as argument)
– For a new data point, make each of the trees predict values of the dependent variable for the input given.
– Assign the average value of the predicted values to the actual final output.
This is similar to guessing the number of balls in a box. Let us assume we randomly note the prediction values given by many people, and then calculate the average to make a decision on the number of balls in the box. Random forest is a model that uses multiple decision trees, which we know, but since it has a lot of trees, it also requires a high time for training also computational power, which is still a drawback.
K Nearest Neighbors(KNN model)
It can be used from the KNearestNeighbors class. These are simple and easy to implement. For an input introduced in the data set, the K Nearest neighbors help to find out the k most similar instances in the training set. Either average value of median of the neighbors is taken as the value for that input.
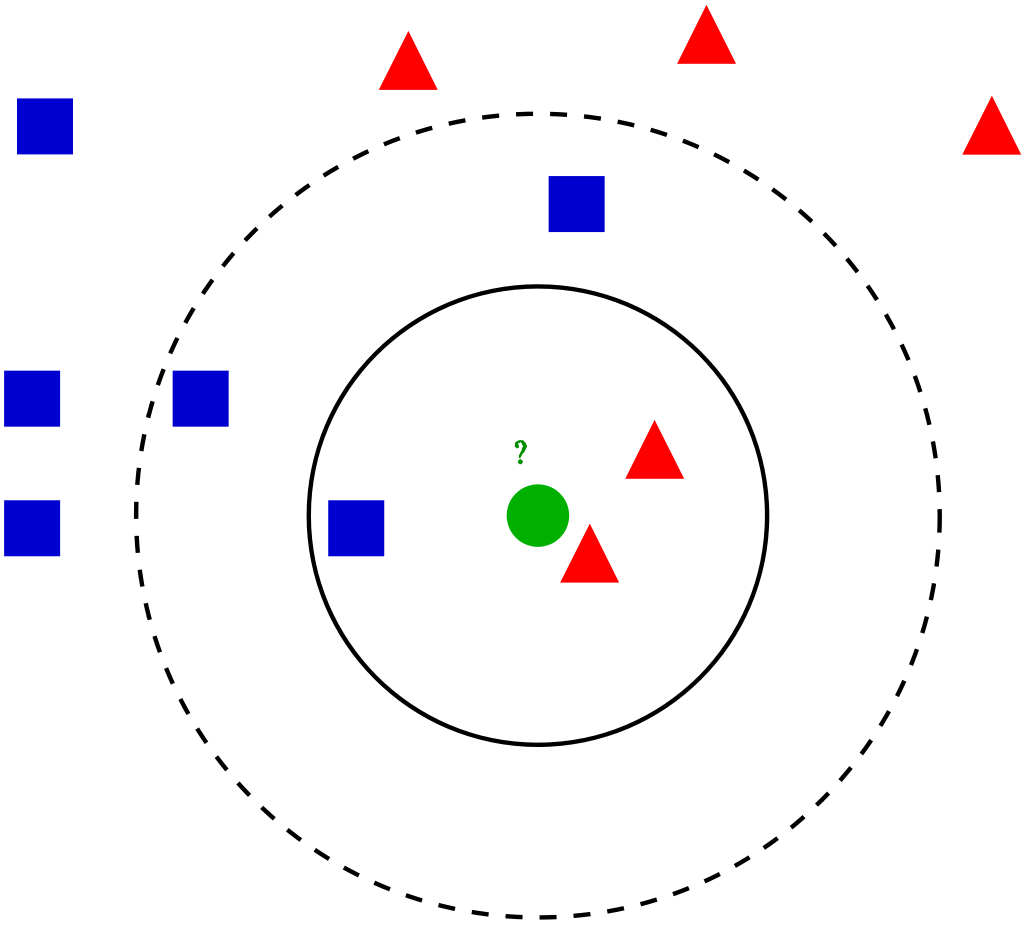
The method to find the value can be given as an argument, of which the default value is “Minkowski” -a combination of “euclidean” and “manhattan” distances.
Predictions can be slow when the data is large and of poor quality. Since the prediction needs to take into account all the data points, the model will take up more space when training.
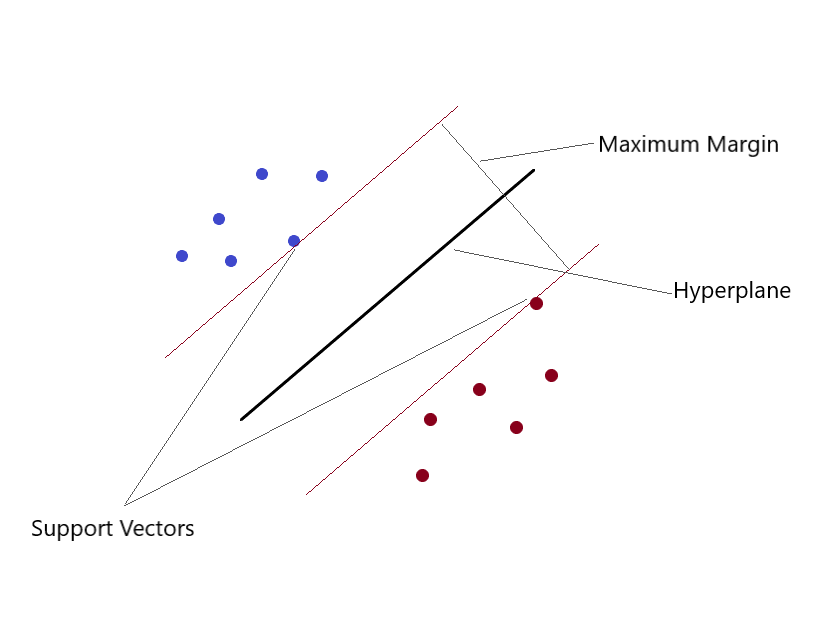
Support Vector Machines(SVM)
It can solve both linear and non-linear regression problems. We create an SVM model using the SVR class. In a multi-dimensional space, when we have more than one variable to determine the output, then each of the points is no longer a point as in 2D, but are vectors. The most extreme kind of assigning values can be done using this method. You separate classes and give them values. The separation is by the concept of Max-Margin(a hyperplane). What you must note is that SVMs are not at all suitable for predicting values for large training sets. SVM fails when data has more noise.
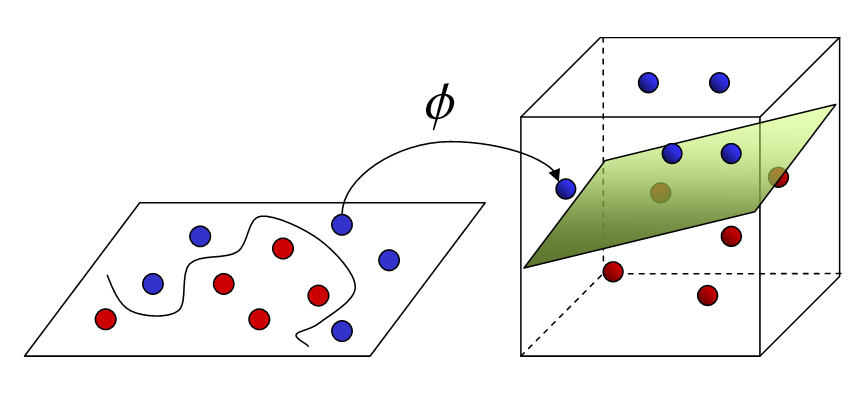
If training data is much larger than the number of features, KNN is better than SVM. SVM outperforms KNN when there are larger features and lesser training data.
Well, we have come to an end of this article, we have discussed the kinds of regression algorithms(theory) in brief. This is Surabhi, I am B.Tech Undergrad. Do check out my Linkedin profile and get connected. Hope you enjoyed reading this. Thank you.
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.
Conclusion
In summary, knowing about regression algorithms is essential in machine learning. Linear regression is like the basic building block, and Ridge/Lasso helps with some technical stuff. Other cool tools like Decision Trees, Random Forest, KNN, and SVM make understanding and predicting more complex things possible. It’s like having a toolbox for different jobs in machine learning!
Frequently Asked Questions
Q1.What is regression and classification?
Regression is a machine learning task that aims to predict a numerical value based on input data. It’s like guessing a number on a scale. On the other hand, classification is about expecting which category or group something belongs to, like sorting things into different buckets.
Q2.What is an example of regression in ML?
Imagine predicting the price of a house based on factors like size, location, and number of bedrooms. That’s a classic example of regression in machine learning. You’re trying to estimate a specific value (the price) using various input features
Q3. Where is regression used in ML?
Regression is used in many real-world scenarios. For instance, it helps predict stock prices, sales trends, or weather forecasts. In essence, regression in machine learning comes in handy when predicting a numerical outcome.







The graphics do not render correctly.