This article was published as a part of the Data Science Blogathon.
Introduction:
One of the main concepts of Relational Database Management Systems is Normalization Theory. This topic is really important for students who are taking DBMS course in their Computer Science and Information Technology major in their undergrad or Data Science and Business Analytics in their Post graduation. This article highlights the various anomalies that are created due to redundancy in databases and how the Normalization theory addresses those issues.

How can we design a ‘good database’? Informally we can say a database is good when each relation or schema represents a particular entity. For example, a Student is one kind of entity, so there is a relation for the student. Faculty is another kind of entity, so there is another entity for faculty members.
For a database to be good, we can also say there are no spurious tuples i.e. there is no tuple that has got values that don’t mean anything. Redundancy in a database denotes the repetition of stored data. Redundancy might cause various anomalies and problems pertaining to storage requirements:
Insertion anomalies: It may be impossible to store certain information without storing some other, unrelated information.
Deletion anomalies: It may be impossible to delete certain information without losing some other, unrelated information.
Update anomalies: If one copy of such repeated data is updated, all copies need to be updated to prevent inconsistency.
Increasing storage requirements: The storage requirements may increase over time.
These issues can be addressed by decomposing the database –
normalization forces this!!!
Decomposition:
When a schema or a relation is decomposed, there are issues like losslessness that one can face.
Losslessness:
Suppose we have a relation having three attributes:
<id, name, yob>

These two tables can be decomposed into 2 tables:
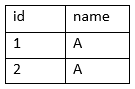
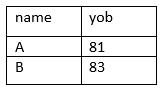
But it should produce the original entity on join. However, on join, we get the following entity:
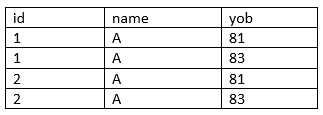
So, this decomposition is a lossy decomposition. This decomposition loses certain information so, it essentially violates the property of losslessness. We want the database to be such that the decomposition is lossless. We must strive for a design where there no spurious tuple.
Normalization theory tries to say how to design a good database in a formal manner. So, it tries to handle these problems of modification anomaly, the lossless decomposition e.t.c.
Table of Contents
1. Functional Dependencies
2. Axioms about functional dependencies
3. Normal Forms
3.1 First Normal Form (1NF)
3.2 Second Normal Form (2NF)
3.3 Third Normal Form (3NF)
3.4 Boyce-Cord Normal Form (BCNF)
1. Functional Dependencies:
Functional Dependencies(FD) are constraints that can be derived from the relation itself.
X——> Y ( It means X functionally determines Y, where X and Y are sets of attributes in a particular relation)
The value of X uniquely determines the value of Y.
Suppose X is the candidate key or super key of the relation. Then, the unique value of X determines the entire table so Y can be any other attribute. If we say X functionally determines Y, that means if you know the value of X, the value of Y is fixed and it’s a unique value.
Or, we can say , t1.X = t2.X ==> t1 .Y = t2.Y
but it is not another way round. For example. roll —-> name (in student database). If we know the roll no. of a student, the name is uniquely determined.
Trivial:
A functional dependency is called trivial if y is a subset of X i.e. Y ⊆ X.
A candidate key functionally determines every other attribute of the relation.
Normal forms: The functional dependencies and the keys together define normal forms of the database.
2. Axioms about the functional dependencies:
Armstrong’s Axioms : ( as Inference Rules )
1. Reflexive: if Y ⊆ X, then X —–> Y
i.e. if Y is a subset of X then X functionally determines Y.
2. Augmentation: If X —–>Y, then XZ—–>YZ
If X functionally determines Y, then XZ functionally determines YZ. So essentially if X is augmented with another set of attributes Z i.e. if the left side is augmented then the right side is augmented.
3. Transitive: If X ——> Y & Y ——> Z then X ——> Z
If we know the value of X, the value Y is unique and if you know the unique value of Y, again the value of z is unique. So we can say knowing X will determine the unique value of Z.
Note that these rules are sound and complete in the sense that any other rule that can be derived from it will also hold. No other rule can be outside this. So, every other rule can be derived from one or more of all these.
4. Decomposition: If X——>YZ, ( it is an attribute set which is formed from Y & Z), then X—–>Y and X—–>Z
5. Union: If X—–>Y & Y—–>Z, then X—–>YZ
6. Pseudotransitivity: If X—–>Y, & WY—–>Z, then, WX—–>Z
Closure of a set of Functional Dependencies:
If F is a set of functional dependency, F+ is called the closure of it. So, given F, all the functional dependency rules that can be derived from it forms F+. So, F+ is a closure of it.
If X is the set of attributes w.r.t. F, then the set X+ is a closure i.e. if X is the set of attributes derived from F, then X+ is the set of attributes derived from the closure of F+.
Covers: F covers G if everything in G can be inferred from F.
i.e. F covers G ⊆ G+ ⊆ F+
Also, note that F&G are equivalent if the closure of them are the same i.e. if F+ = G+
Minimal: F is minimal if every FD of F has only a single attribute with the following conditions:
1. f belongs to F, RHS off is a single attribute
2. Any G ⊂ F is not equivalent to F.
3. Any F –>( X—>A ) ⋃ ( Y—>A ) where Y⊂ X is not equivalent to F.
Note: Every set of FD has at least one minimal set of FD.
3. Normal Forms –
The process of actually designing what the schemas are and in general taking all the attributes of all the entities of the database together and breaking them up into smaller relations is called normalization.
Keys & FDs determines which normal form relation is in: 1NF, 2NF, 3NF, BCNF
3.1 First Normal Form (1NF):
A relation is in 1NF if the following condition holds:
Every attribute is atomic. Example of a non-atomic attribute: Name -> It can be broken into First Name and Last Name. If a relation contains ‘Name’, it may not be considered to be in 1NF. Generally, we assume that things are in 1NF (even if ‘Name’ is present) unless explicitly mentioned.
Prime attributes: Attributes that are a member of some candidate key is called a prime attribute. Example – Roll no.
Non–Prime attribute: Not a member of any candidate key.
NOTE: We will use the key for the candidate key henceforth.
Full functional dependency: X——>Y is called full functional dependency if X cannot be reduced any further and it is a partial dependency otherwise. Ex: roll ——>name (Full FD)
Partial FD: It is a partial FD if the left side is reduced and it is still a functional dependency. Ex: roll, gender ——> name. It is a partial FD as we can get rid of the gender & still the FD holds.
Transitive FD: IfX——>Z can be derived from X——>Y & Y——>Z
Ex: Roll ——> hod. It is a transitive F.D because: roll ——>dept.id and dept.id ——> hod.
Non–Transitive F.D: If X——>Z can not be broken down to X——>Y & Y——>Z.
3.2 Second Normal Form (2NF):
A relation is said to be in 2NF if every non-prime attribute is fully functionally dependent on every candidate key OR
Every attribute must be :
(1). In a candidate key, or
(2). Depend fully on every candidate key
Ex: <id, projid, hrs, name, project name> Check whether it is in 2NF?
We test each attribute & see whether it satisfies the conditions of 2NF:
id: This is a candidate key so it is not a non–prime attribute. So, nothing needs to be done, it is already satisfying the condition of 2NF.
projid: Again it is a candidate key so projid is fine.
hrs: Does it fully depend on every candidate key? So, the only candidate key here is id and projid. So ‘hrs’ depend completely on id & projid i.e. neither id by itself nor projid by itself determines hrs.
name: It is a non-prime attribute & it is not determined fully by id and projid because there is partial id to name so that means name is not fully determined. So, ‘name’ fails the 2NF test.
NOTE: name is determined only by ID which means id & projid together, the key is redundant.
Now, suppose we want to make this relationship into 2NF, this process is called a 2NF normalization.
2NF Normalization:
We break it up into the following tables:
The 1st table contains: (id, projid, hrs )
2nd table : (id, name )
3rd table : (projid, projname)
Note that all three tables are in 2NF. The design where we break this up into these three tables in a better design.
3.3 Third Normal Form (3NF):
A relation is in 3NF if:
1. It is in 2NF, and
2. No non-prime attribute is transitively functionally dependent on the candidate key.
OR
For every F.D. X——>Y
1. It is trivial i.e. Y⊆C, or
2. X is superkey, or
3. Every attribute in Y——>X is prime
OR
Every non-prime attribute
1. Fully functionally dependent on every key, AND
2. Non–transitively functional dependence on every key
Example: <id, name projid, projname>
id – name, projid
projid – projname
Check whether it is in 3NF?
It is not in 3NF because of the following reasons:
id – prime attribute, so nothing needs to be done.
name – name is fully determined by the id & it is not transitively dependent on any other thing. So name is fine.
projid – projid is fully determined by the id & it is not transitively dependent on any other thing. So projid is also fine.
projname – It is a non–prime attribute & it transitively determines on ID
Hence, it is not in 3NF.
3NF normalization: We try to isolate the offending attribute i.e. projname in this case. So, we will try to isolate it by breaking this relation into two parts: (id, name, projid) and (projid, projname). Now both of these relations are in 3NF.
projname is determined on projid which in turn is determined by ID so if id changes, projname is affected unnecessarily. So if projname is changed, the effect is carried in a rippling manner to the id so every employee who works in that projname gets affected, so all the tuples now need to be modified.
On the other hand, when it is broken down into 3NF form, the projname is isolated from this so the first table is not touched at all & in 2nd table, there is only one change that needs to be done, which is to change the project name. So, this is a much better design.
Summary:
1. In 1NF – all attributes are atomic.
2. In 2NF – all attributes must depend on the whole key so that is why it is sort of fully functionally dependent.
3. In 3NF – all attributes must depend on nothing but the key. There is no transitive dependence, it must only depend on the key.
i.e. in short,
1NF: atomic
2NF: whole key
3NF: nothing but the key
Example: L = (id, list, lot, area, price, rate)
id – list, lot, area, price, rate
dist, lot – id, area, price, rate
dist – rate
area – price. Check whether it is in 1NF, 2NF, and 3NF?
It is in 1NF because we are assuming every attribute is atomic
It is not in 2NF. Consider rate which depends on dist, lot and rate also depends on district so it is not fully dependent on dist & lot. So, it violates 2NF condition.
It is not in 3NF. We can say without testing because if something is not in 2NF, it can not be in 3NF.
Now that we have seen that it is not in 2NF and 3NF, we will try to normalize it:
2NF Normalization:
L1 = ( id ,dist,area,price) It is in 2NF.
L2 = ( dist , rate ) It is in 2NF
Now, we will check whether L2 is in 3NF?
If there are only two attributes and one of them is the key & that’s the only key, it is in any normal form one can think of. rate is only determined by dist and there are no functional dependencies. So, yes L2 is in 3NF.
Now that L2 is in 3NF, we will check whether L1 is in 3NF or not?
Because price depends on id but is also dependent on area i.e. id determines area which determines the price. So, this is the offending key. In order to normalize it we have to break it to be in 3NF:
L11 = (id, dist, lot, area)
L12 = (area, price )
Functional Dependency is satisfied in L12. L11 is in 3NF because there is only one key and dist.
3.4 Boyce- Cord Normal Form ( BCNF):
If X——>Y is non-trivial F.D, then X is a superkey.
OR
For every functional dependency X——>Y,
1. Trival, or
2. X is a superkey
Example:
Id ——>, dist, lot, area
Dist, lot ——> id, area
Area——> dist
Check whether this is BCNF?
No, it is not in BCNF because of area – dist (others are fine)
area determines dist but area by itself is not a super key.
Normalizing this in BCNF: For normalization, we need to break this down into – (id, let, area) and (dist, area)
F.D: id——> lot, and area ——> dist
Note: 1. Functional dependencies may be lost
2. May not always be possible to be lossless
Ex.- town, state, dist
town, state ——> dist, and dist ——> state are a functional dependency.
It is not in BCNF, the problem is with dist ——> state. we break it into (state, dist) & (town, state)
Note:
One can check that this decomposition is not lossless because if one joins this, then you do not get back the original relationship. So, this is lossy and this cannot be allowed under any circumstances. So, this decomposition is wrong.
One can also argue that maybe the BCNF decomposition rule was wrong as t there is no way to break this relationship down in any other way. So, this is the problem with BCNF. It may be possible it may not always be possible to ensure that the relationship is in BCNF.
Functional dependency & keys can normalize the relation up to a certain extent. So, it can wake, the design of a database good up to a certain extent. It can not make it completely bereft of any modification anomaly. There can still be modifications anomaly even if one covers all the normal forms that are possible with functional dependencies & keys.
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.






