This article was published as a part of the Data Science Blogathon.
Introduction
A data model is an abstraction of real-world events that we use to create, capture, and store data in a database that user applications require, omitting unnecessary details. As mentioned earlier, when determining requirements, we collect information about different business processes and the data that each process requires. In this process, the database designer is more likely to gather a lot of information—not all of it is needed initially to model data. We will need to separate the business objects and the information that understands the business objects.
.png)
Data Abstraction
When we move from one level (high-level conceptualization to lower-level implementation) of the data model to another, this is how to add more detail to the business objects. We will follow the levels of data abstraction as we move from user-level data requests to the physical representation of data in a database. We call this a three-tier database design architecture.
To facilitate the user’s interaction with the database, developers hide internal non-essential details from users. This process of hiding irrelevant details from the user is called data abstraction. The term “irrelevant” used here concerning the user does not mean that the hidden data is not relevant to the entire database. It just means that users are not interested in this data.
For example: When you book a train ticket, you don’t care how the data is processed at the back when you click on “book ticket”; what processes happen when you make online payments? You are only concerned about the message that appears when your ticket is successfully booked. This does not mean that the process going on at the back there is not relevant, it means you as a user, are not interested in what is happening in the database.
Three levels of data abstraction
• External level
• Conceptual level
• Inner level
The physical implementation of the database is in the selected database management software, and the selected hardware system follows these three levels, as shown in figure one below.
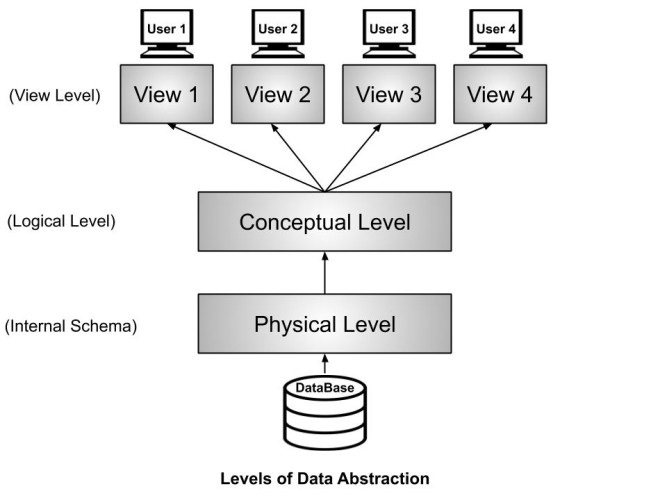
External Level
This level is also known as the external view. Identifying the data requirements of each user group includes identifying the user’s view of the data. First, we present what data is required by each user group and whose data is to be stored in the underlying database. The database design meets the data requirements of the organization as a whole.
A user group is, therefore, a division or department of an organization. The data requirements for such a division or department may be only a small set of data needed to meet their functional requirements. Thus, each division or department may require a data set that may be different; however, there may be some overlap with another related division or department.
Consider a hypothetical university, Your Area Learning University, for which we want to design a database. We identify groups of users as follows:
- HRD View — HRD needs data about employees, i.e., support and academic staff, information about employee benefits, and so on.
- Enrollment View – a registrar’s office that needs information about student registration and student exam results.
- Accounts View — Student Accounts (Business Office) that need information about financial aid, scholarships, and student fee payments.
- Student Life View — Student Life, which needs data about those students who live in the halls of residence
- Athletic View — An athletic department that needs data on students participating in one or more sports representing the university at regional, state, and national sporting events.
- The employee table will contain information about employees; The workbench will contain data on specials.
- Characteristics of the Professor table will contain data on academic staff.
- The job chart will contain different job titles.
- The plan table will contain information about various health and life insurance plans.
- The benefits table will contain data on the benefits chosen by the employee.
External view of HRD:
Note that we have identified only a few user groups within the university here, but there may be more user groups that are not included in our discussion. We want to design a database that will jointly meet the data requirements of all the above groups.
So we need to know the need in terms of data that can be satisfied from our designed database. Each user group will only look at what they need, regardless of the others. Each user group can think that we are designing the database just for them and, therefore, their view of the data. Thus, each user view of the data represents one external view. When we combine all external views, the resulting design must meet the data needs of all user groups.
HRD needs employee data. As the information collected from the support staff is not the same as that collected from academic staff, RLZ suggested that we store some different information about academic and non-academic staff in separate tables. Only a common set of information is stored in one Employee table.
These are design criteria only, and it is not mandatory to have three tables Employee, Employees, and Professor. We’ll talk about table design in detail later, explaining how to decide how to store information in different tables. With this note, we have the following model for HRD.
The external view of HRD is shown in Chen’s notation in ERD as follows:
External view of the registrar: The registrar needs information about students, registration of students in each semester, exam results, and grades. The student table will contain data about student information, student registration records table, course tables, and class schedule in the class table. The Registrar’s Office’s exterior is in Chens Notations in the ERD.
External view of the student account:
The Student Accounts Division is part of the Business Office, which deals with student fees, scholarships, and financial aid. A student account needs information about students, registering students each semester, assessing fees, and awarding scholarships and financial aid. External view for the student
The account is shown in Chens Notations in the ERD as follows:
As you have noticed from the above scenarios, information overlaps between different groups of users. The database designer must combine data requests from all users before creating the final database.
Concept Level
This level of abstraction meets organizational data requirements. We often use the word “conceptualization” to mean an overall picture of a given situation. Once conceptualized, it is easy to imagine. In the database design, the conceptual level represents an organizational view of the data, which combines or integrates external views into a single view.
It is an organization-wide representation of data, as seen by high-level managers. At that level, we identify the main data objects and describe them in minimal detail. This is where we look at the data in terms of the relationship that may exist between them.
For a better overview of data presentation, we use the most commonly used conceptual model: Entity Relationship Model (ERM). Using ERM, we create a conceptual diagram that serves to design the database. The figure below shows the use of ERM to create a conceptual diagram. This method has the advantage of combining all external views into the organization’s data requirements and showing the relationships between the data.
While we are creating a conceptual diagram using ERM, it should be noted that the ER model is independent of the database software that we can use to create our database. It is independent of the hardware on which we implement the model. The ER model is thus independent of both software and hardware platforms. This offers us the flexibility of modeling at the conceptual level, as any change in database management hardware or software will not affect the conceptual level.
Inner Level
The internal model is specific to the choice of DBMS. We implement the conceptual model into this specific DBMS modification. Essentially, we are mapping the conceptual model onto the characteristics and limitations of the selected models. This means that the internal model is dependent on the DBMS. Therefore, a change in the DBMS software may require a change in the ER model mapping to meet the DBMS requirements. The concept model is not affected. This is known as logical independence.
Let’s assume we decide to use a relational DBMS; then, our conceptual model will be mapped to the RDBMS internal model. This way, our entities will be mapped to tables. However, it does not matter which hardware platform we choose to install the DBMS, which makes the internal model independent of the hardware, as it is not affected by the choice of a computer we choose to install the software.
Conclusion
These systems are made up of complex data structures; every time a user interacts with the system, the developers often hide internal non-essential details from the user. The process of hiding irrelevant details is known as data abstraction. Abstraction is generally the process of removing elements from something to reduce the set of essential elements. It is usually the first step in database design. Creating a system without first creating a complete database of a simplified structure is much more complicated. These allow the developer to start with the essentials—the data abstractions—and add descending data details to create the final system
- Identifying the data requirements of each user group includes identifying the user’s view of the data. First, we present what data is required by each user group and whose data is to be stored in the underlying database.
- The ER model is thus independent of both software and hardware platforms. This offers us the flexibility of modeling at the conceptual level, as any change in database management hardware or software will not affect the conceptual level.
- Using ERM, we create a conceptual diagram that serves to design the database. The figure below shows the use of ERM to create a conceptual diagram. This method has the advantage of combining all external views into the organization’s data requirements and also showing the relationships that exist between the data.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I am a Machine Learning Enthusiast. Done some Industry level projects on Data Science and Machine Learning. Have Certifications in Python and ML from trusted sources like data camp and Skills vertex. My Goal in life is to perceive a career in Data Industry.







Data Abstraction learnt