This article was published as a part of the Data Science Blogathon.
Introduction
Before explaining nested cross-validation, let’s start with the basics. A typical machine learning flow can be like this:
1. Understanding the business objective.
2. Getting the raw data.
3. Understanding the data.
4. Cleaning, preparing, and improving the data.
5. Selecting a model.
6. Training a model.
7. Assessing the validity of the model.
8. Making new predictions with the model.
In this article, we will focus our attention on steps 5, 6, and 7. So let’s assume that you have a perfectly prepared dataset, with some features and a target, and you want to use it for building a model.
How can you proceed? The naïve approach will be: using a library like scikit-learn, selecting a model, using the default parameters, and fitting in on the entire dataset. This way, you will have a fitted model you could use to make predictions. What’s the problem with this approach?
There are two, and we will tackle them one by one.
Improving the naïve approach
Train/Test split
– How can you be confident about the predictions of the model? Is the model good or bad?
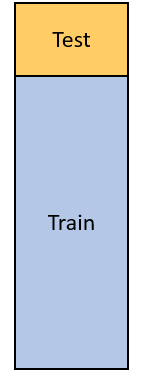
The simpler approach is splitting the dataset into two partitions: train and test. You train your model on the training dataset and you check the performance on the test set.
But there is a remaining problem:
– How do you know if the default parameters are good for your dataset?
The previous split does not work, because if you select your model based on the performance on the test dataset, you cannot measure how good the best model is using the same test dataset (it will be an optimistically biased estimation).
Train/Test/Validation Split
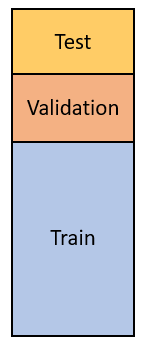
So to answer those two questions at the same time, the simpler approach is splitting your dataset into at least three partitions: train, validation, and test.
And then:
– You will train lots of models, of different types and with different parameters.
– Those models will be evaluated using the validation set. That means that you will use a metric (like roc_auc if we are in a classification problem) to compare the models on this dataset and select the model with better performance.
– Then, you will test this model on the test dataset, and this will give you an unbiased estimation of the performance of the model (the previous score, applied on the validation dataset, is biased because you have selected the best model based on the performance on this dataset).
– After you are satisfied and you have an estimation of the quality of the model, you can fit the winner model on the entire dataset, because, if the learning rate is still positive, it might improve a little.
Is there any problem with the previous approach? Well, what happens if the split generates datasets that differ a little bit in terms of statistical distributions? It will be safer to do different splits and check if the models and scores are similar or not. That’s when nested cross-validation comes in, helping you to do it in an ordered and consistent fashion.
Simple cross-validation
To understand it, let’s start with simple cross-validation. Simple cross-validation is analogous of the first approach we discussed: the train/test split. Let’s suppose that test size is 20% and train size is 80%, and that you want to assess how good a particular model with a fixed set of parameters is. Then, with the former simple train/test split you will:
– Train the model with the training dataset.
– Measure the score with the test dataset.
– And have only one estimate of the score.
On the other hand, if you decide to perform cross-validation, you will do this:
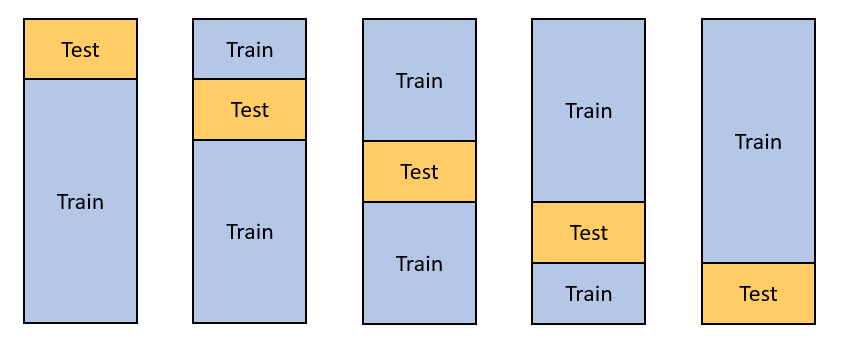
– Do 5 different splits (five because the test ratio is 1:5).
– For each split, you will train the model using the training dataset and measure the score using the test dataset.
– You will average the five scores and the estimate of the score will be sharper.
So, as you can see, you can replace the outer test split for estimating the error with a 5-fold splitting that helps you have more confidence in your estimation.
Nested cross-validation
Can you do the same for the inner validation split? Yes, and that’s called nested cross-validation. In nested cross-validation, you have a double loop, an outer loop (that will serve for assessing the quality of the model), and an inner loop (that will serve for model/parameter selection). It’s very important that those loops are independent, so each step or layer of cross-validation does one and only one thing.
The picture will be now:
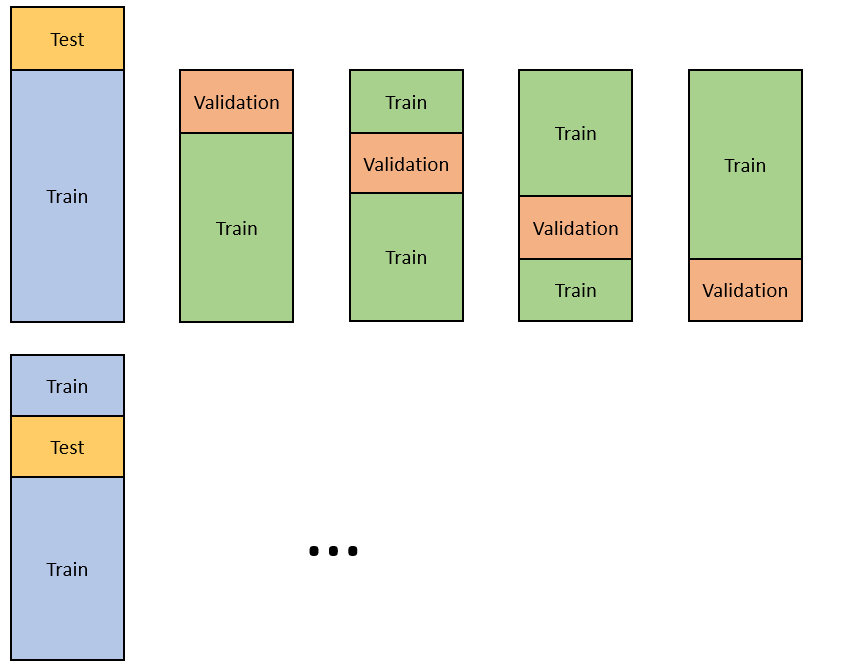
The outer loop is repeated 5 times, generating five different test sets. And for each iteration, the outer train set will be further split (in this case, into 4 folds). If there are 5 outer folds and 4 inner folds, as in the picture, the total number of trained models will be 20.
– The outer layer will be used for estimating the quality of the models trained on the inner layer.
– The inner layer will be used for selecting the best model (including parameters).
One important distinction: in fact, you are not assessing just the quality of the model, but the quality of the procedure for model selection. That’s it: what you are evaluating in the outer folds is that the procedure for model selection is consistent and well performant. So, after you finish the process, you will be able to apply the same exact inner procedure to your whole dataset.
In other words: for each iteration of the outer loop, you will select one (and only one) inner model (the best one), and this model will be evaluated on the test set for this outer fold. After you vary the outer test set, you will have 5 (k in general) estimates, and you can average them to assess better the quality of the models.
Maybe you have one doubt: once you find the best model + parameters, the ones that optimize the averaged performance on the validations sets, how can you select the model to check it on the outer test set if you have in fact, 4 different inner models? You can do two things:
– Creating a new instance of the model with these best parameters, and fit this instance on the whole outer train set.
– Or creating an ensemble of all inner models. An ensemble means that you will use all models for making predictions, by averaging the predictions of them.
Both approaches can be correct.
Implementation in Python
Now that you understand it, how can you code it in Python? Well, I will show you a Python library that I made for myself and my own projects, and it’s now pip installable.
For the moment, this library only works for binary classification problems. If that is your setting, the options that it has can make your life easier when trying to apply this nested cross-validation approach. I suggest reading the readme first, at least the first two sections, and then jump to the examples.
The full code is located here:
https://github.com/JaimeArboleda/nestedcvtraining
It’s my first Python package, so any comments, suggestions, or critics will be more than welcome!!
I hope you find this article useful!
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.







Nested CV is explained very poorly !! Please update it using layman's words
Very well explained. Nested Cross validation is complex concept to understand at first. It takes some time to grasp what's going on. I believe the author did a really good job here. Thanks!