This article was published as a part of the Data Science Blogathon
I started learning machine learning recently and I think cross-validation is one of the most important methods for our models.
So, the question arises here, What is cross-validation and why is it important for the models to achieve good performance? Let’s dive into this.
What is cross-validation?
Cross-validation is a step when you start building your model, it’s like before sitting in the main exam you solving previous year papers to perform well in the main exam. This is not the exact definition of cross-validation but one way to look at it and understand it.
So, next, the question arises, why is it important?
It usually happens when we understand if something is important when we get stuck on something, I mean, let’s take the current scenario, because of Covid we now know that how important is it to take care of our health and how important is the healthcare sector.
Same concepts we can apply here, because of overfitting, cross-validation is important.
Okay so, the new term here, Overfitting, everyone have watched Doraemon, there is one episode where Nobita wants to learn answers for exam and Doraemon gives him a gadget (a bread) if he eats he will memorize it all, well here it is the same, model the Nobita memorizes the data gives the predictions, yes better on training data but performs badly on unseen data and this is called Overfitting, memorizing the data.
So, because of Overfitting, cross-validation is important and we will dive into this with an example. I think overfitting with an example will clear things up. So, let’s go :
I’m taking the wine-quality dataset for simplicity, this dataset consists of features about wine, and depending on those features the quality of the wine is measured, quality in the dataset I have scales between 0 to 5.
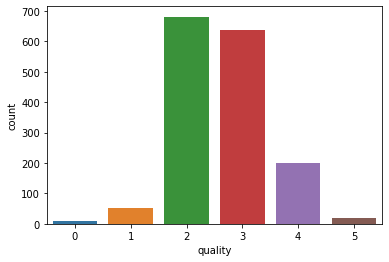
Here you can see how imbalanced this dataset is, after seeing this kind of dataset, I always question myself, Can imbalanced data create Overfitting? Well, this is a very interesting topic to delve into but let’s not lose our balance here.
I’m using the Decision Trees classifier here to calculate the accuracy of training and test data.
We have 5 categories of quality here and that is why I’m posing this as a classification problem, and picking a very simple accuracy as our metric.
from sklearn import tree
from sklearn import metrics
clf = tree.DecisionTreeClassifier(max_depth = 10)
clf.fit(data_train[cols], data_train.quality)
train_pred = clf.predict(data_train[cols])
test_pred = clf.predict(data_test[cols])
train_score = metrics.accuracy-score(data_train.quality, train_pred)
test_score = metrics.accuracy_score(data_test.quality, test_pred)
print(train_score*100, '%')
90.2%
print(test_score*100, '%')
56.59%
As you can see over here the training accuracy is very good but the testing accuracy is not quite good, whenever you see a significant difference in training and testing accuracy then it indicates overfitting. It could here happen that most of the wine will be classified into only one or two classes.
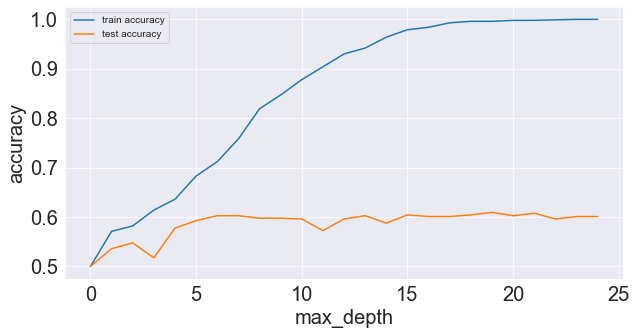
Photo by author
Here is the graph where I have calculated accuracies for different max depths. (Max depth is one of Decision Tree’s parameters). As you can see testing accuracy is not increasing but training has reached almost 100% accuracy.
Now, Cross-Validation comes in picture

Here you can see I have divided the whole dataset into 4 folds, folds could also be said as iteration. So, for every fold we calculate accuracy and one more thing, every fold has a different sample for testing from the dataset (Like shuffling for every fold).
After calculating the accuracies for every fold, we will average them as shown in the image above.
from sklearn.model_selection import GridSearchCV
max_depth = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
clff = GridSearchCV(clf, hyperparameter, cv = 5)
best_model = clff.fit(data_train[cols], data_train.quality)
print('Best depth : ', best_model.best_estimator_)
o/p : Best depth : DecisionTreeClassifier(max_depth=10)
kfold = model_selection.KFold(n_splits=5)
model = tree.DecisionTreeClassifier(max_depth=6)
results = cross_val_score(model, data_train[cols], data_train.quality, cv=kfold)
print('Accuracy :', results.mean()*100)
o/p : 57%
As you can see, previously we were getting 90% accuracy and now with our best parameter we are on 57%, this implies that If we used Decision Tree then It will not perform well and most probably it will overfit.
There are more cross-validation techniques and KFold is one of them. I just wanted to tell you that cross-validation is an important technique to know if we are overfitting and not perform badly on testing data.
The next important type of cross-validation is stratified k-fold. We have a dataset for classification with 2 and 3 quality has the most sample in the dataset, for this, you don’t want to use the random k-fold cross-validation we did above. Using simple k-fold cross-validation for a dataset like this can result in folds with all same quality (2 or 3) samples. In these cases, we prefer using stratified k-fold cross-validation.
Stratified k-fold cross-validation keeps the ratio of labels in each fold constant. So, in each fold, you will have the same amount of samples with the same distribution. Thus, whatever metric you choose to evaluate, will give similar results across all folds.
from sklearn.model_selection import cross_val_score from sklearn.model_selection import StratifiedKFold cv = StratifiedKFold(n_splits=4, shuffle=True, random_state=1) scores = cross_val_score(clf, data_train[cols], data_train.quality, scoring = 'accuracy', cv = cv) print(scores.mean())
o/p : 54%
We also can find optimal k for our model and for that we will try to plot the depth and scores for it
import matplotlib import matplotlib.pyplot as plt import seaborn as sns
# this is our global size of label text
# on the plots
matplotlib.rc('xtick', labelsize=20)
matplotlib.rc('ytick', labelsize=20)
# This line ensures that the plot is displayed # inside the notebook %matplotlib inline
d_rad_range = range(1, 31)
# empty list to store scores
d_scores = []
# 1. we will loop through values of d
for d in d_range:
# 2. run DecisionTreeClassifier
dt = tree.DecisionTreeClassifier(max_depth=d)
# 3. obtain cross_val_score for DecisionTreeClassifier
scores = cross_val_score(dt, data_train[cols], data_train.quality, cv=10, scoring='accuracy')
# 4. append mean of scores for depth to d_scores list
d_scores.append(scores.mean())
plt.figure(figsize=(10, 5))
sns.set_style("darkgrid")
plt.plot(d_range, d_scores)
plt.xlabel('d', size=20)
plt.ylabel('d_scores', size=20)
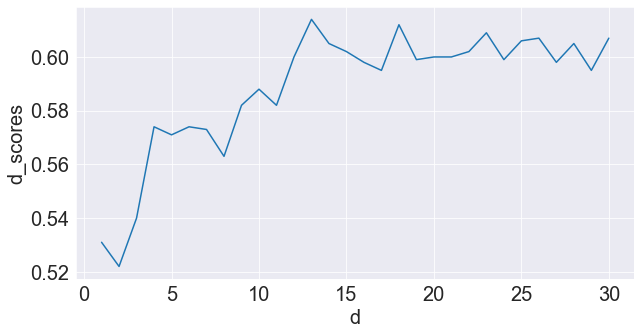
Here, we plotted the d (max depth) for the folds (scores).
Use Cross-validation and Save your Model.
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.






