This article was published as a part of the Data Science Blogathon.
What is Bias?
Most of you might have watched or at least heard about the popular Netflix series ‘Queen’s Gambit’. This series had excellently captured the struggles of women in society and one of the best examples of gender bias.

PiCTURE CREDIT: PHIL BRAY/NETFLIX
We all know that society is biased for ages. Bias based on gender, race, age, socioeconomic status, etc have consciously or unconsciously been part of human thoughts and actions. In this modern society with the help of raising awareness, most of us are coming forward to fight against discrimination and prejudice that is affecting human decision-making.
But what about the decision-making done by intelligent systems and applications that are increasingly becoming an inevitable part of our lives?
These intelligent applications are built on data supplied by humans. When the bias is present in human thoughts and actions, there is no surprise that the intelligent applications that we are developing are inheriting this bias from us.
What is Data Bias?
Consider an NLP application fills a sentence as ‘Father is to doctor as a mother is to nurse’.

The above NLP example is directly linked to the gender inequality present in society.
Consider more examples:
Why did one of the popular AI-based recruitment software biased against women applicants?
Why did Siri and Alexa show gender bias initially?
There are many reports that a lot of image processing applications fail to recognize women, especially dark-skinned women.
Why did the AI-based decision support application fail to identify criminals belonging to a particular race?
Why is this bias in the output given by these ML/AI applications?
Because the Machine Learning / AI applications that we design learn from the data that we feed to them. The data we feed contains the prejudices and inequalities that exist in the human world consciously or unconsciously.
We are in the race to build smart cities, smart buildings using the advancements in technology. What happens when an automatic door opener in your office fails to recognize a person based on his/her skin color?
How serious are the implications of neglecting bias in the data?
As Data Scientists/ Data Analysts/Machine Learning Engineers and AI practitioners, we know that if our data sample does not represent the whole population, then our results are not statistically significant. Which means that we do not get accurate results.
Machine Learning models built on such data would perform worse on underrepresented data.
Picture source: https://link.springer.com/article/10.1007/s13555-020-00372-0
Consider an example from one of the critical domains, Healthcare, where data bias would result in devastating results.
The AI algorithms developed to detect skin cancer as perfectly as an experienced dermatologist failed to detect skin cancers in people with dark skin. Refer to the picture shown above.
Why did this happen?
Because the dataset was imbalanced. Majority of the images on which the algorithms were trained belong to light-skinned individuals. The data that was used to train these algorithms was taken from those states where the majority are white-skinned people. Hence, the algorithm fails to detect the disease in dark-skinned people when the images belonging to them were given to it.
Another AI application developed to identify the early stages of Alzheimer’s disease in people took auditory tests from people. It takes the way a person speaks as input and analyzes that data to identify the disease. But as the algorithm was trained on the data from Native English speakers, when a non-native English speaker takes the test, it wrongly identified the pauses and mispronunciations as indicators of the disease. (An example of false positive)

Picture source: https://www.onartificialintelligence.com/articles/18060/new-findings-on-human-speech-recognition
What are the consequences of this wrong diagnosis in the above two examples?
Where in the development process have we gone wrong?
How can AI bias occur?
There are multiple factors behind these AI biases. There is no single root cause.
1. Missing diverse demographic categories.
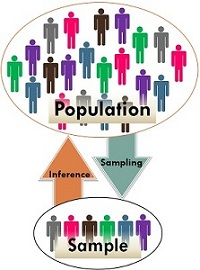
Picture Source: https://www2.stat.duke.edu/courses
Sampling errors are also majorly the result of improper data collection methods.
Datasets that do not include diverse demographic categories will be imbalanced/skewed and there are higher chances of overlooking these factors during the data cleaning phase.
2. Bias inherited from humans.
As discussed above, bias can be induced into data while labeling, most of the time unintentionally, by humans in supervised learning. This can be due to the fact that unconscious bias is present in humans. As this data teaches and trains the AI algorithm on how to analyze and give predictions, the output will have anomalies.
3. During the feature engineering phase
During the feature engineering phase, bias can occur.
For example, while developing an ML application for predicting loan approval, if features like race, gender are considered, these features would induce bias.
On the contrary, while developing an AI application for healthcare, if the same features like race, gender are removed from the dataset, this would result in the errors explained in the healthcare examples above.
Research on handling AI Bias
AI is being used widely in not only the popular domains but also in very sensitive domains like health care, criminal justice, etc. Hence, the debate on biased data and fairness in the output is always on in data and AI communities.
There is so much research and study going on to identify how bias is induced into the AI systems and how to handle it to reduce errors. Responsible AI and ethical AI are also been adopted widely to tackle the problem of bias too along with other AI challenges.
Are we not responsible to reduce this data bias?
One of the primary goals of using AI in decision support systems should be to make decisions less biased than humans.
Should we leave this biased-data problem to the researchers and carry on with our regular data cleaning tasks and trying to improve the accuracy of our algorithms as part of our development work?
As Artificial Intelligence is growing deeper and deeper into our lives, bias in data that is used for developing these applications can have serious implications not only on human life but also on the entire planet.
Hence, it is everyone’s responsibility to work towards identifying and handling bias at the early stages of development.
What is our part to reduce data bias?
Every data Machine Learning engineer/AI practitioner has to take the responsibility of identifying and removing bias while he works on developing artificially intelligent applications.
Here are some of the steps we can consider to take this forward.
We should not blindly build, develop applications with whatever data is available to us.
We need to work with researchers too and ensure that diverse data is available for our model development.
We have to be careful during the data collection phase to gain enough domain knowledge on the problem we are working on to be able to assess if the data collected includes diverse factors and has any chances of bias.
During the feature engineering phase, we should study the features in-depth combined with more research on the problem domain we are working in, to eliminate any features that may possibly induce bias.
Explainable AI and Interpretable AI also helps us to build trust in algorithms by ensuring fairness, inclusivity, transparency, and reliability.
Testing and evaluating the models carefully by measuring accuracy levels for different demographic categories and sensitive groups may also help in reducing algorithmic bias.
Finally, we must also ensure to include the topics related to AI-Bias and its implications in every data course. Because handling data bias and saving the world from adverse effects is the responsibility of every data enthusiast.
About Me:
Prasuna Atreyapurapu:
I am a data lover | Big Data consultant | Data Engineer | Data Science and Machine Learning trainer | Mentor | Curriculum Strategist and Content Developer.
https://www.linkedin.com/in/prasuna-atreyapurapu-a954064/
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.






