This article was published as a part of the Data Science Blogathon
Introduction
Big data is the collection of data that is vast in size, however, growing exponentially faster with time. It’s data with so huge size and complexity that none of the traditional data management tools will store it or process it with efficiency.
Big Data is a field that treats ways in which to research, analyze, and consistently extract info from vast unstructured or structured data.
Python has various inbuilt features of supporting data processing whether it is small or huge in size. These features support processing for unstructured and unconventional data. This is the reason why Data Scientists and Big Data companies prefer to choose Python for data processing as it is considered to be one of the most important requirements in Big Data.
There are other technologies also that can process Big Data more efficiently than python. They are Hadoop and Spark.
Hadoop
Hadoop is the best solution for storing and processing Big Data because Hadoop stores huge files in the form of (HDFS) Hadoop distributed file system without specifying any schema.
It is highly scalable as any number of nodes can be added to enhance performance. In Hadoop data is highly available if there is any hardware failure also takes place.
Spark
Spark is also a good choice for processing a large amount of structured or unstructured datasets as the data is stored in clusters. Spark will conceive to store the maximum amount of data in memory so it can spill to disk. It will store a part of the dataset in memory and therefore the remaining data on the disk.
Toady Data Scientist’s first choice of language is Python and both Hadoop and Spark provide Python APIs that provides processing of the Big Data and also allows easy access to Big data platforms.
Image source: by me
Need of Python in Big Data
1. Open Source:
Python is an open-source programming language developed beneath under an OSI-approved open supply license, creating it freely usable and distributable, even for business use.
Python is a general-purpose, high-level interpreted language. It doesn’t have to be compiled to run. A program known as an interpreter runs Python code on virtually any type of system. This implies that a developer can modify the code and quickly see the results.
2. Easy to learn:
Python is very easy to learn just like the English language. Its syntax and code are easy and readable for beginners also. Python has a lot of applications like the development of web applications, data science, machine learning, and, so on.
Python allows us to write programs with lesser lines of code than most of the other programming languages. The popularity of Python is growing rapidly because of its simplicity.
3. Data processing Libraries:
When it comes to Data Processing, Python has a
rich set of tools with a whole range of benefits. As it’s an open-source language, it is easy to learn and also continuously improving. Python consists of a list of various useful libraries for data processing and also integrated with other languages (like Java) as well as existing structures. Python is richer in libraries that enhance its functionality even more.
4. Compatibility with Hadoop and Spark:
Hadoop framework is written in Java language; however, Hadoop programs can be coded in Python or C++ language. We can write programs like MapReduce in Python language, while not the requirement for translating the code into Java jar files.
Spark provides a Python API called PySpark released by the Apache Spark community to support Python with Spark. Using PySpark, one will simply integrate and work with RDDs within the Python programming language too.
Spark comes with an interactive python shell called PySpark shell. This PySpark shell is responsible for the link between the python API and the spark core and initializing the spark context. PySpark can also be launched directly from the command line by giving some instructions for interactive use.
5. Speed and Efficiency:
Python is a powerful and efficient high-level programming language. Whether for developing an application or working to solve any business problem through data science, Python has you covered all these boundaries. Python always does well for optimizing developer’s productivity and efficiency.
We can quickly create a program that can solve a business problem and fills a practical need. However,
the solutions may not reach optimized python performance while developing quickly.
6. Scalable and Flexible:
Python is that the most well-liked language for ML/AI due to its convenience. Python’s flexibility additionally permits to instrument Python code to form ML/AI scalability possibly without requiring higher expertise of distributed system and lots of invasive code changes. Hence, ML/AI users get the advantages of cluster-wide scalability with minimal effort.
Components of Hadoop:
There are mainly two components of Hadoop:
- HDFS (Hadoop Distributed File System)
- MapReduce
Hadoop Distributed file system
Hadoop file system was developed based on the distributed file system model. It runs on commodity hardware. In contrast to different distributed systems, HDFS is extremely fault-tolerant and designed using inexpensive hardware.
HDFS is able to hold a very huge amount of data and also provides easier access to those data. To store such a large amount of data, the files are stored over multiple systems. These files are stored in a redundant fashion to rescue the system from potential data losses just in case of failure. HDFS additionally makes applications offered to multiprocessing.
- It is liable for storing data on a cluster as distributed storage and processing.
- The data servers of the name node and knowledge node facilitate users to simply check the status of the cluster.
- Each block is replicated multiple times by default 3 times. Replicas are stored on completely different nodes.
- Hadoop Streaming acts like a bridge between your Python code and therefore the Java-based HDFS, and enables you to seamlessly access Hadoop clusters and execute MapReduce tasks.
- HDFS provides file permissions and authentication.
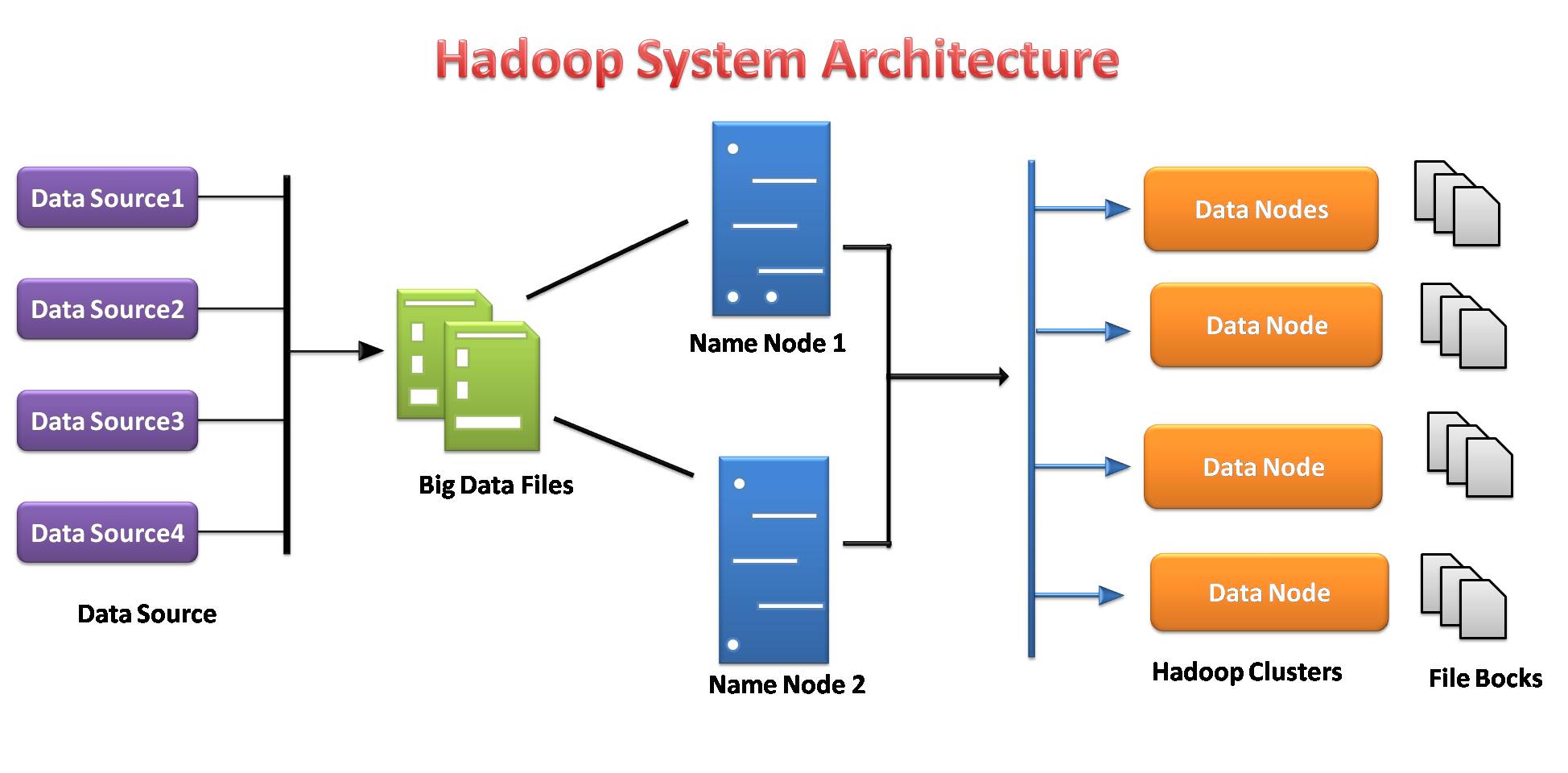
Image source: by me
Hadoop Installation in Google Colab
Hadoop is a java programming-based data processing framework. Let’s install Hadoop setup step by step in Google Colab. There are two ways first is we have to install java on our machines and the second way is we will install java in google colab, so there is no need to install java on our machines. As we are using Google colab we choose the second way to install Hadoop:
# Install java !apt-get install openjdk-8-jdk-headless -qq > /dev/null
#create java home variable import os os.environ["JAVA_HOME"] = "/usr/lib/jvm/java-8-openjdk-amd64" os.environ["SPARK_HOME"] = "/content/spark-3.0.0-bin-hadoop3.2"
Step 1: Install Hadoop
#download hadoop !wget https://downloads.apache.org/hadoop/common/hadoop-3.3.0/hadoop-3.3.0.tar.gz
#we’ll use the tar command with the -x flag to extract, -z to uncompress, #-v for verbose output, and -f to specify that we’re extracting from a file !tar -xzvf hadoop-3.3.0.tar.gz
#copying the hadoop file to user/local !cp -r hadoop-3.3.0/ /usr/local/
Step 2: Configure java Home variable
#finding the default Java path !readlink -f /usr/bin/java | sed "s:bin/java::"
Step 3: Run Hadoop
#Running Hadoop !/usr/local/hadoop-3.3.0/bin/hadoop
!mkdir ~/input
!cp /usr/local/hadoop-3.3.0/etc/hadoop/*.xml ~/input
!ls ~/input
!/usr/local/hadoop-3.3.0/bin/hadoop jar /usr/local/hadoop-3.3.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar grep ~/input ~/grep_example 'allowed[.]*'
Now, Google Colab is ready to implement HDFS.
MapReduce
MapReduce is a programming model that is associated with the implementation of processing and generating big data sets with the help of parallel, distributed algorithmic rules on a cluster.
A MapReduce program consists of a map procedure, that performs filtering and sorting, and a reduce technique, that performs an outline operation.
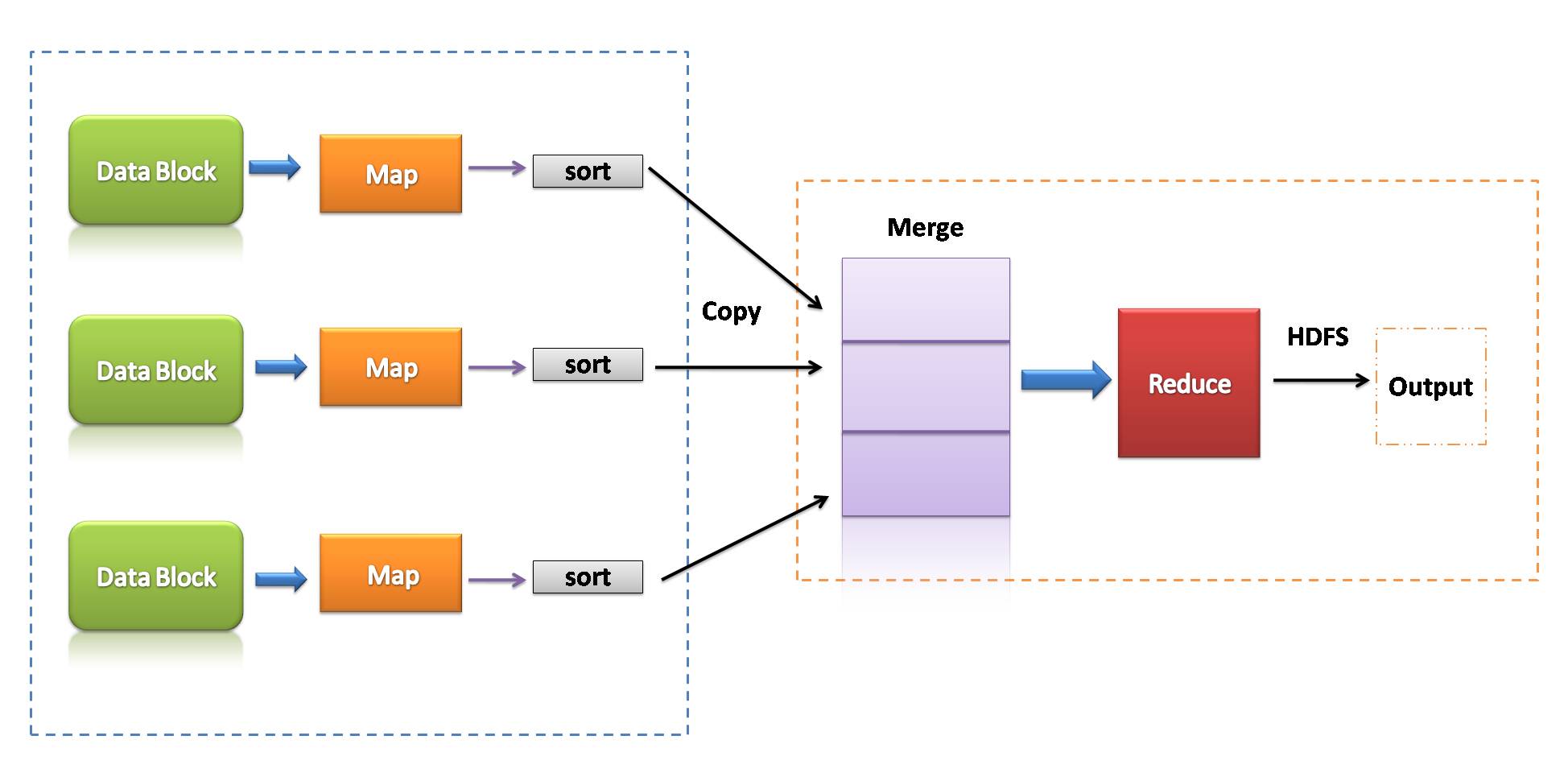
Image source: by me
- MapReduce could be a data processing framework to process data on the cluster.
- Two consecutive phases: Map and reduce.
- Each map task operates on separate parts of data.
- After the map, the reducer works on the data generated by the mapper on distributed data nodes.
- MapReduce used Disk I/O to perform operations on data.
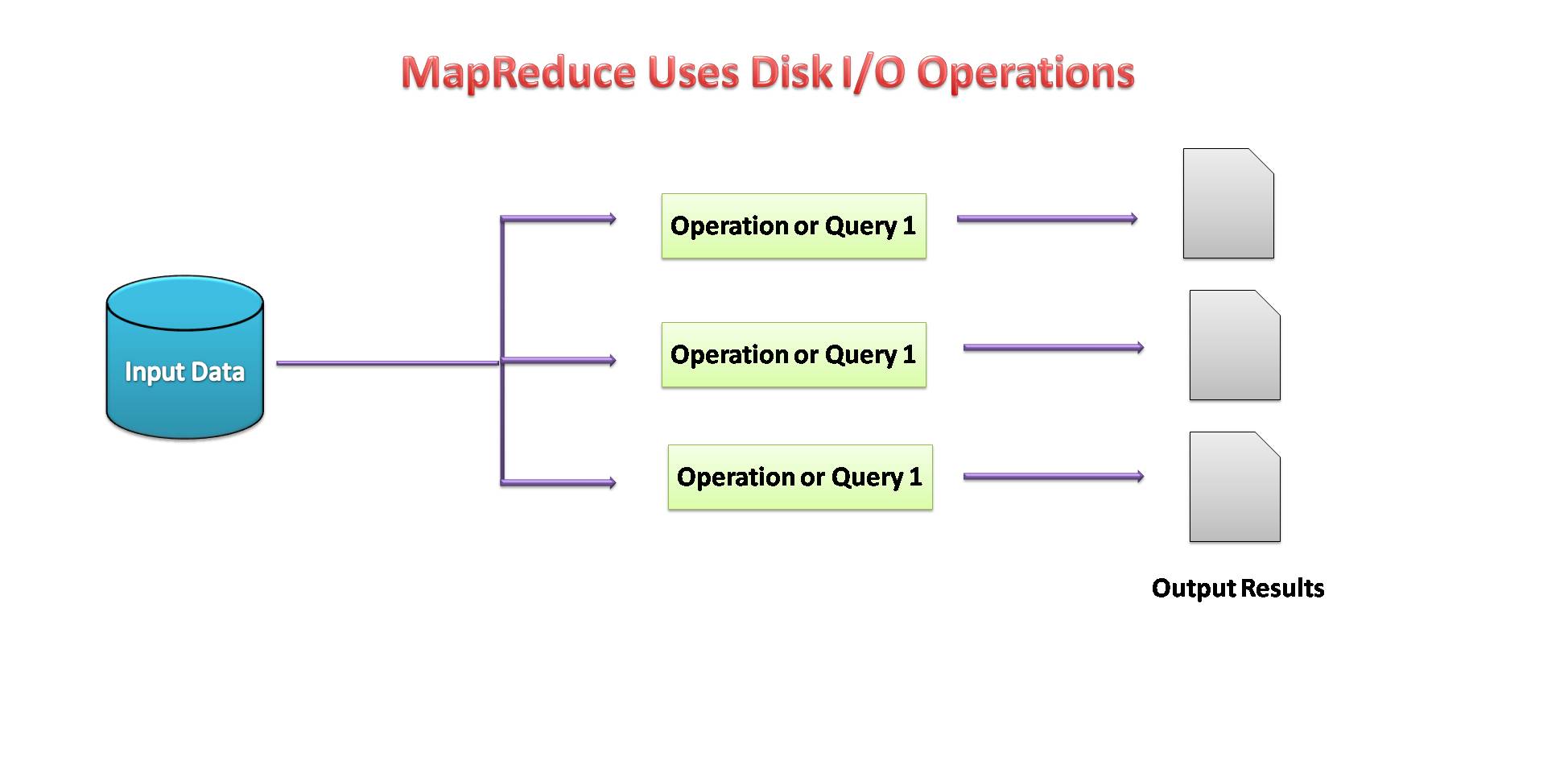
Image source: by me
Apache Spark
Apache Spark is an open-source data analytics engine for large-scale processing of structure or unstructured data. To work with the Python including the Spark functionalities, the Apache Spark community had released a tool called PySpark.
The Spark Python API (PySpark) discloses the Spark programming model to Python. Using the PySpark, we can work with RDDs in the Python programming language. It’s attributable to a library referred to as the Py4j that they’re able to reach this.
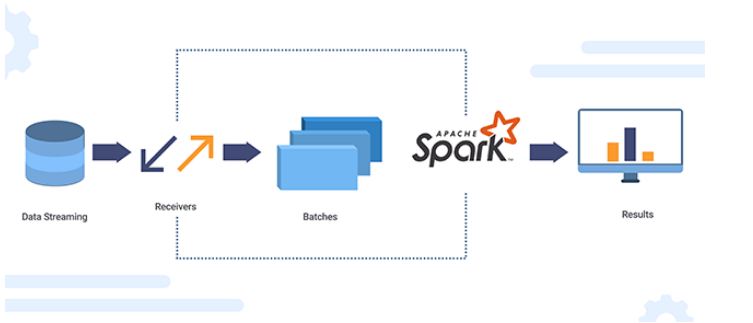
Image source: XanonStack
Resilient Distributed Datasets (RDD)
Concepts about Resilient Distributed Datasets (RDD) are:
- The main approach of Spark programming is RDD.
- Spark is extremely fault-tolerant. It has collections of objects spread across a cluster that can be operating on in parallel.
- By using Spark it can automatically be recovered from machine failure.
- We can create an RDD either by copying the elements from an existing collection or by referencing a dataset stored externally.
- There are two types of operations performed by RDDs: transformations and actions.
- The Transformation operation uses an existing dataset to create a new one. Example: Map, filter, join.
- Actions performed on the dataset and return the value to the driver program. Example: Reduce, count, collect, save.
If the availability of memory seems insufficient, then the data is written to disk like MapReduce.
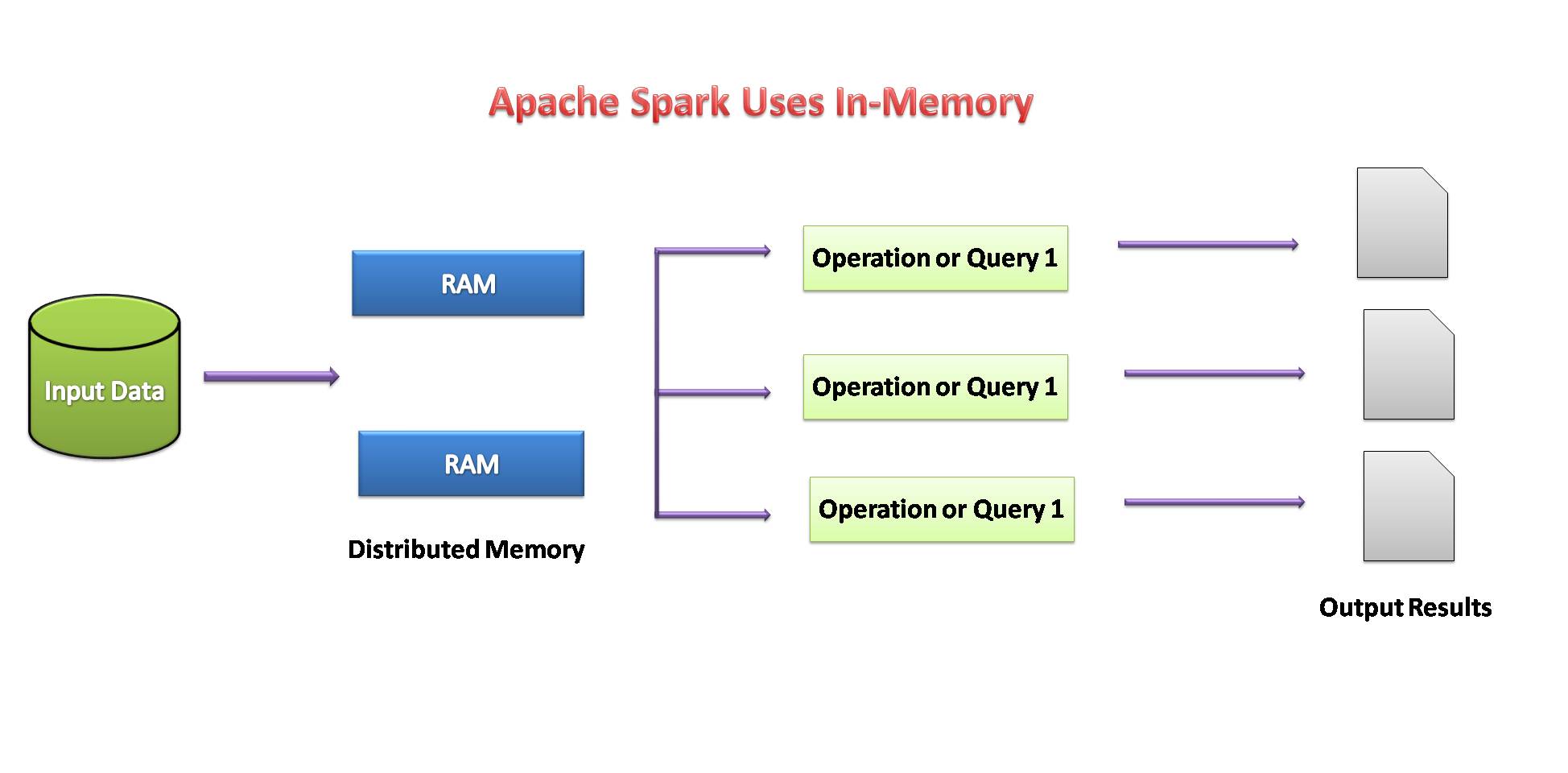
Image source: by me
Installation of spark in Google colab:
Spark is an efficient data processing framework. we can easily install it in the Google colab.
# Install java !apt-get install openjdk-8-jdk-headless -qq > /dev/null
#Install spark (change the version number if needed) !wget -q https://archive.apache.org/dist/spark/spark-3.0.0/spark-3.0.0-bin-hadoop3.2.tgz
#Unzip the spark file to the current folder !tar xf spark-3.0.0-bin-hadoop3.2.tgz
#Set your spark folder to your system path environment. import os os.environ["JAVA_HOME"] = "/usr/lib/jvm/java-8-openjdk-amd64" os.environ["SPARK_HOME"] = "/content/spark-3.0.0-bin-hadoop3.2"
#Install findspark using pip !pip install -q findspark
#Spark for Python (pyspark) !pip install pyspark
#importing pyspark import pyspark
#importing sparksessio from pyspark.sql import SparkSession
#creating a sparksession object and providing appName
spark=SparkSession.builder.appName("local[*]").getOrCreate()
#printing the version of spark
print("Apache Spark version: ", spark.version)

Now, Google Colab is ready to implement Spark in python.
Advantages of Apache spark:
- The Spark is 10 to 100 times faster than the Hadoop MapReduce when talking about data processing.
- It has simple data processing framework and Interactive APIs for Python that helps in faster application development.
- Also, It is more efficient as it has multiple tools for complex analytics operations.
- It can be easily integrated with the existing Hadoop infrastructure.
Conclusion:
In this blog, we studied how Python can become a good and efficient tool for Big Data Processing also. We can integrate all the Big Data tools with Python which makes data processing easier and faster. Python has become a suitable choice not only for Data Science but also for Big Data processing.
Thanks for reading. Do let me know if there is any comment or feedback.
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.






