Introduction
Improve your Python output with the power of pprint! Properly formatted and visually appealing output can greatly enhance your code debugging experience. This article introduces pprint, a Python library that serves as a Data Pretty Printer. Whether you’re dealing with JSON files or working with dictionaries, pprint can help you handle large amounts of data more effectively. Say goodbye to messy outputs and confusing structures. Best of all, pprint is an inbuilt Python library, so no separate installation is required. Let’s dive in and make your outputs shine!
This article was published as a part of the Data Science Blogathon.
Table of contents
What is pprint()?
It stands for “Pretty Print”, and is one of the native Python libraries that allows you to customize your outputs with its numerous parameters and flags for its single class pprint(). Here is the official documentation to list all of its properties and usage.
pprint() Parameters
The library contains just a single class, called pprint(). There are in total six parameters that can be used with this class. Here is a short description of the parameters along with their default values:
- indent: The number of spaces to indent each line, this value can help when specific formatting is needed. Default value = 1
- width: Maximum characters that can be in a single line. If the number of words exceeds this limit, the remaining text will be wrapped on the lines below. Default value = 80
- depth: The number of depth levels to be shown while using nested data types. By default, it shows all the data, but if specified, the data beyond the depth level is shown as a series of dots ( . . . ). Default value = None
- stream: This is used to specify an output stream and is mainly used to pretty print a file. Its default behavior is to use sys.stdout. Default value = None
- compact: This is a boolean argument. If set to True, it will consolidate complex data structures into single lines, within the specified width. If the value is the default (ie. False) all the items will be formatted on separate lines. Default value = False
- sort_dicts: This is also a boolean argument. While printing dictionaries with pprint(), it prints the key-value pair sorted according to the key name alphabetically. When set to false, the key, value pairs will be displayed according to their order of insertion. Default value = True
Now enough with the technical stuff, let’s jump into the programming part!
Basics of pprint()
First, we import the pprint module at the beginning of our notebook.
import pprintNow you can either use the pprint() method or instantiate your pprint object with PrettyPrinter().
import pprint
pprint.pprint("Hello World!")
my_printer = pprint.PrettyPrinter()
my_printer.pprint("Hello Pretty Printer")
print(type(my_printer))Now let us create a sample dictionary to demonstrate some of the arguments of the class pprint().
sample_dict = {
'name': 'Sion',
'age': 21,
'message': 'Thank you for reading this article!',
'topic':'Python Libraries'
}If we simply print out this dictionary using print, what we get is:
{'name': 'Sion', 'age': 21, 'message': 'Thank you for reading this article!', 'topic': 'Python Libraries'}Now that doesn’t look much appealing, does it? But still one might argue that this output format is okay since you can clearly see which value belongs to which key, but what happens if these values are extremely long, and nested. Or if the volume of our key-value pairs is much much more? That’s when it all goes downhill. It will become very very difficult to read, but worry not, print to the rescue:
pprint.pprint(sample_dict)
Firstly, all the pairs have their separate row, which increases the readability tenfold. Also if you look closely, all the elements are automatically sorted according to the keys.
The pprintpp Module
The pprintpp module is an enhanced version of the built-in pprint module in Python. It provides advanced pretty-printing functionality, allowing you to format complex data structures in a more readable and visually appealing manner. With pprintpp, you can handle nested objects, dictionaries, lists, and other data structures with ease. Its improved formatting options make it an excellent choice for displaying large amounts of data in a clear and concise way. Upgrade your data visualization and debugging capabilities by exploring the power of pprintpp in your Python projects.
Also Read: How to Read Common File Formats in Python – CSV, Excel, JSON, and more!
Text Wrapping

Most people might know the basics that I showed above. Now let’s use some of the other parameters to further customize our outputs.
Another basic usage is text wrapping. Suppose you are not satisfied by just printing the key-value pairs on separate lines, but want to have the text wrapped when the length of the line exceeds a certain amount. For this, we can use the width parameter.
pprint.pprint(sample_dict, width = 30)
Apart from this, we can use the indent parameter to add indentation in front of each row for better readability.
pprint.pprint(sample_dict, width = 30, indent = 10)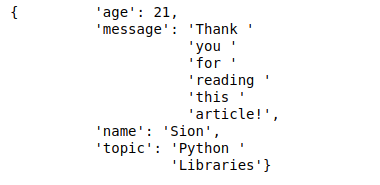
Here is an example for the usage of compact and width parameters:
import pprint
stuff = ['spam', 'eggs', 'lumberjack', 'knights', 'ni']
stuff.insert(0, stuff[:])
pp = pprint.PrettyPrinter(indent=4)
pp.pprint(stuff)
pp = pprint.PrettyPrinter(width=41, compact=True)
pp.pprint(stuff)
Deep Nested Objects

Sometimes while working with highly nested objects, we just want to view just the outer values and are not interested in the deeper levels. For example, if we have a nested tuple like this:
sample_tuple = ('spam', ('eggs', ('lumberjack', ('knights', ('ni', ('dead',
('parrot', ('fresh fruit',))))))))Now if we use print or print, the outputs will be almost similar:
print(sample_tuple)
> ('spam', ('eggs', ('lumberjack', ('knights', ('ni', ('dead', ('parrot', ('fresh fruit',))))))))
pp.pprint(sample_tuple)
However, if the depth parameter is specified, anything deeper than that will be truncated:
pprint.pprint(sample_tuple, depth=2)
pprint.pprint(sample_tuple, depth=1)
p = pprint.PrettyPrinter(depth=6)
p.pprint(sample_tuple)
pprint() vs PrettyPrinter()
The difference between these two is that the pprint() method uses the default arguments and settings of the libraries, which you can change like we previously saw, but these changes are temporary.
With PrettyPrinter(), you can create a class, with your own specifications and override the default settings to create permanent class objects which retain their forms and values all over your project.
import pprint
coordinates = [
{
"name": "Location 1",
"gps": (29.008966, 111.573724)
},
{
"name": "Location 2",
"gps": (40.1632626, 44.2935926)
},
{
"name": "Location 3",
"gps": (29.476705, 121.869339)
}
]
pprint.pprint(coordinates, depth=1)
> [{...}, {...}, {...}]
pprint.pprint(coordinates)
As you can see, the arguments supplied were just temporary. Conversely, these settings are stored with PrettyPrinter(), and you can use them wherever in the code you want, without any change in functionality:
import pprint
my_printer = pprint.PrettyPrinter(depth=1)
coordinates = [
{
"name": "Location 1",
"gps": (29.008966, 111.573724)
},
{
"name": "Location 2",
"gps": (40.1632626, 44.2935926)
},
{
"name": "Location 3",
"gps": (29.476705, 121.869339)
}
]
my_printer.pprint(coordinates)
> [{...}, {...}, {...}]Conclusion
In conclusion, mastering pprint in Python can greatly enhance your data handling and debugging skills. With its ability to present data in a more readable and organized format, pprint is an invaluable tool for any Python developer. If you want to take your Python and data science skills to the next level, consider joining Analytics Vidhya’s Blackbelt program. It will empower you to become a proficient data scientist with expert guidance, comprehensive resources, and hands-on projects. Take advantage of this opportunity to level up your career in data science.
Frequently Asked Questions
Q1. What is Pprint used for?
A. Pprint (pretty print) is a Python module used for formatting complex data structures more readably and organized, especially when printing them to the console or writing to a file.
Q2. What is the difference between print and Pprint?
A. The main difference between print and Pprint is that Pprint is designed to format complex data structures such as dictionaries and lists, preserving their structure and providing indentation. In contrast, print is used for simple output of values or strings.
Q3. Is Pprint standard in Python?
A. Pprint is not a standard built-in module in Python, but it is included in the Python Standard Library, meaning it is available by default in most Python installations.
Q4. Is Pprint native to Python?
A. Yes, Pprint is native to Python as it is included in the Python Standard Library, allowing developers to utilize its functionality without needing external dependencies or installations.
References
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.






