Introduction
I have recently come across a lot of aspiring data scientists wondering why it’s so difficult to import different file formats in Python. Most of you might be familiar with the read_csv() function in Pandas but things get tricky from there.
How to read a JSON file in Python? How about an image file? How about multiple files all at once? These are questions you should know the answer to – but might find it difficult to grasp initially.
And mastering these file formats is critical to your success in the data science industry. You’ll be working with all sorts of file formats collected from multiple data sources – that’s the reality of the modern digital age we live in.

So in this article, I will introduce you to some of the most common file formats that a data scientist should know. We will learn how to read them in Python so that you are well prepared before you enter the battlefield!
I highly recommend taking our popular ‘Python for Data Science‘ course if you’re new to the Python programming language. It’s free and acts as the perfect starting point in your journey.
Table of Contents
- Extracting from Zip files in Python
- Reading Text files in Python
- Import CSV file in Python using Pandas
- Reading Excel file in Python
- Importing Data from Database using Python
- Working with JSON files in Python
- Reading data from Pickle files in Python
- Web Scraping with Python
- Reading Image files using PIL
- Read multiple files using Glob
Extracting from Zip Files in Python
Zip files are a gift from the coding gods. It is like they have fallen from heaven to save our storage space and time. Old school programmers and computer users will certainly relate to how we used to copy gigantic installation files in Zip format!
But technically speaking, ZIP is an archive file format that supports lossless data compression. This means you don’t have to worry about your data being lost in the compression-decompression process (Silicon Valley, anyone?).


Here, let’s look at how you can open a ZIP folder with Python. For this, you will need the zip file library in Python.
I have zipped all the files required for this article in a separate ZIP folder, so let’s extract them!
Once you run the above code, you can view the extracted files in the same folder as your Python script:
Reading Text Files in Python



Text files are one of the most common file formats to store data. Python makes it very easy to read data from text files.
Python provides the open() function to read files that take in the file path and the file access mode as its parameters. For reading a text file, the file access mode is ‘r’. I have mentioned the other access modes below:
- ‘w’ – writing to a file
- ‘r+’ or ‘w+’ – read and write to a file
- ‘a’ – appending to an already existing file
- ‘a+’ – append to a file after reading
Python provides us with three functions to read data from a text file:
- read(n) – This function reads n bytes from the text files or reads the complete information from the file if no number is specified. It is smart enough to handle the delimiters when it encounters one and separates the sentences
- readline(n) – This function allows you to read n bytes from the file but not more than one line of information
- readlines() – This function reads the complete information in the file but unlike read(), it doesn’t bother about the delimiting character and prints them as well in a list format
Let us see how these functions differ in reading a text file:
The read() function imported all the data in the file in the correct structured form.
By providing a number in the read() function, we were able to extract the specified amount of bytes from the file.
Using readline(), only a single line from the text file was extracted.
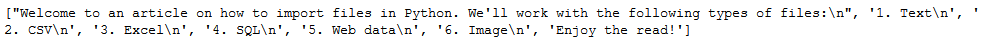
Here, the readline() function extracted all the text file data in a list format.
Reading CSV Files in Python
Ah, the good old CSV format. A CSV (or Comma Separated Value) file is the most common type of file that a data scientist will ever work with. These files use a “,” as a delimiter to separate the values and each row in a CSV file is a data record.
These are useful to transfer data from one application to another and is probably the reason why they are so commonplace in the world of data science.
If you look at them in the Notepad, you will notice that the values are separated by commas:

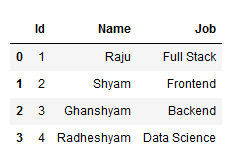
The Pandas library makes it very easy to read CSV files using the read_csv() function:
import pandas as pd
# read csv file into a DataFrame
df = pd.read_csv('products.csv')
# display DataFrame
print(df)But CSV can run into problems if the values contain commas. This can be overcome by using different delimiters to separate information in the file, like ‘\t’ or ‘;’, etc. These can also be imported with the read_csv() function by specifying the delimiter in the parameter value as shown below while reading a TSV (Tab Separated Values) file:
Reading Excel Files in Python
Most of you will be quite familiar with Excel files and why they are so widely used to store tabular data. So I’m going to jump right to the code and import an Excel file in Python using Pandas.
Pandas has a very handy function called read_excel() to read Excel files:

But an Excel file can contain multiple sheets, right? So how can we access them?
For this, we can use the Pandas’ ExcelFile() function to print the names of all the sheets in the file:

After doing that, we can easily read data from any sheet we wish by providing its name in the sheet_name parameter in the read_excel() function:

And voila!
Importing Data from a Database using Python
When you are working on a real-world project, you would need to connect your program to a database to retrieve data. There is no way around it (that’s why learning SQL is an important part of your data science journey).
Data in databases is stored in the form of tables and these systems are known as Relational database management systems (RDBMS). However, connecting to RDBMS and retrieving the data from it can prove to be quite a challenging task. Here’s the good news – we can easily do this using Python’s built-in modules!
One of the most popular RDBMS is SQLite. It has many plus points:
- Lightweight database and hence it is easy to use in embedded software
- 35% faster reading and writing compared to the File System
- No intermediary server required. Reading and writing are done directly from the database files on the disk
- Cross-platform database file format. This means a file written on one machine can be copied to and used on a different machine with a different architecture
There are many more reasons for its popularity. But for now, let’s connect with an SQLite database and retrieve our data!
You will need to import the sqlite3 module to use SQLite. Then, you need to work through the following steps to access your data:
- Create a connection with the database connect(). You need to pass the name of your database to access it. It returns a Connection object
- Once you have done that, you need to create a cursor object using the cursor() function. This will allow you to implement SQL commands with which you can manipulate your data
- You can execute the commands in SQL by calling the execute() function on the cursor object. Since we are retrieving data from the database, we will use the SELECT statement and store the query in an object
- Store the data from the object into a dataframe by either calling fetchone(), for one row, or fecthall(), for all the rows, function on the object
And just like that, you have retrieved the data from the database into a Pandas dataframe!
A good practice is to save/commit your transactions using the commit() function even if you are only reading the data.

You can read more about SQLite in Python from the official documentation.
Working with JSON Files in Python
JSON (JavaScript Object Notation) files are lightweight and human-readable to store and exchange data. It is easy for machines to parse and generate these files and are based on the JavaScript programming language.
JSON files store data within {} similar to how a dictionary stores it in Python. But their major benefit is that they are language-independent, meaning they can be used with any programming language – be it Python, C or even Java!
This is how a JSON file looks:

Python provides a json module to read JSON files. You can read JSON files just like simple text files. However, the read function, in this case, is replaced by json.load() function that returns a JSON dictionary.
Once you have done that, you can easily convert it into a Pandas dataframe using the pandas.DataFrame() function:

But you can even load the JSON file directly into a dataframe using the pandas.read_json() function as shown below:

Reading Data from Pickle Files in Python
Pickle files are used to store the serialized form of Python objects. This means objects like list, set, tuple, dict, etc. are converted to a character stream before being stored on the disk. This allows you to continue working with the objects later on. These are particularly useful when you have trained your machine learning model and want to save them to make predictions later on.
So, if you serialized the files before saving them, you need to de-serialize them before you use them in your Python programs. This is done using the pickle.load() function in the pickle module. But when you open the pickle file with Python’s open() function, you need to provide the ‘rb’ parameter to read the binary file.

Web Scraping using Python
Web Scraping refers to extracting large amounts of data from the web. This is important for a data scientist who has to analyze large amounts of data.
Python provides a very handy module called requests to retrieve data from any website. The requests.get() function takes in a URL as its parameter and returns the HTML response as its output. The way it works is summarized in the following steps:
- It packages the Get request to retrieve data from webpage
- Sends the request to the server
- Receives the HTML response and stores in a response object
For this example, I want to show you a bit about my city – Delhi. So, I will retrieve data from the Wikipedia page on Delhi:

But as you can see, the data is not very readable. The tree-like structure of the HTML content retrieved by our request is not very comprehensible. To improve this readability, Python has another wonderful library called BeautifulSoup.
BeautifulSoup is a Python library for parsing the tree-like structure of HTML and extracting data from the HTML document.
Find more about BeautifulSoup in this here.
Right, let’s see the wonder of BeautifulSoup.
To make it work, we need to pass the text response from the request object to BeautifulSoup() which creates its own object – “soup” in this case. Calling prettify() on BeautifulSoup object parses the tree-like structure of the HTML document:
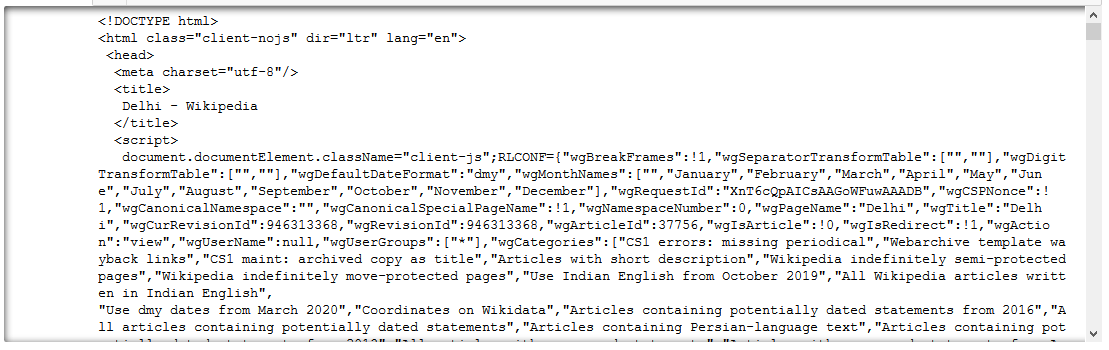
You must have noticed the difference in the output. We have a more structured output in this case!
Now, we can extract the title of the webpage by calling the title() function of our soup object:

The webpage has a lot of pictures of the famous monuments in Delhi and other things related to Delhi. Let’s try and store these in a local folder.
We will need the Python urllib library to retrieve the URL of the images that we want to store. It has a urllib.request() function that is used for opening and reading URLs. Calling the urlretrieve() function on this object allows us to download objects denoted by the URL to a local file:
The images are stored in the “img” tag in HTML. These can be found by calling find_all() on the soup object. After this, we can iterate over the image and get its source by calling the get() function on the image object. The rest is handled by our download function:
Excellent! Now its time to read those images. We’ll cover that in the next section.
Reading Image Files using PIL
The advent of Convolutional Neural Networks (CNN) has opened the flood gates to working in the computer vision domain and solving problems like object detection, object classification, generating new images and what not!
But before you jump on to working with these problems, you need to know how to open your images in Python. Let’s see how we can do that by retrieving images from the webpage that we stored in our local folder.
You will need the Python PIL (Python Image Library) for this job.
Simply call the open() function in the Image module of PIL and pass in the path to your image:

Voila! We have our image to work with! And isn’t my Delhi just beautiful?
Read Multiple Files using Glob
And now, what if you want to read multiple files in one go? That’s quite a common challenge in data science projects.
Python’s Glob module lets you traverse through multiple files in the same location. Using glob.glob(), we can import all the files from our local folder that match a special pattern.
These filename patterns can be made using different wildcards like “*” (for matching multiple characters), “?” (for matching any single character), or ‘[0-9]’ (for matching any number). Let’s see glob in action below.
When importing multiple .py files from the same directory as your Python script, we can use the “*” wildcard:

When importing only a 5 character long Python file, we can use the “?” wildcard:

When importing an image file containing a number in the filename, we can use the “[0-9]” wildcard:

Earlier, we imported a few images from the Wikipedia page on Delhi and saved them in a local folder. I will retrieve these images using the glob module and then display them using the PIL library:

Also Read: The Evolution and Future of Data Science Innovation
End Notes
In this article, I have covered how to read data from the most common file formats that a data scientist might encounter on a daily basis. However, this list is not exhaustive and I encourage you to explore more file formats. If you run into any trouble, feel free to ask in the comments below!
If you are looking to kickstart your journey in data science, I recommend going through some of our amazingly curated courses on Python and Machine Learning.
I am on a journey to becoming a data scientist. I love to unravel trends in data, visualize it and predict the future with ML algorithms! But the most satisfying part of this journey is sharing my learnings, from the challenges that I face, with the community to make the world a better place!







Where is the code? Are you just showing methods from official docs? How about writing some code snippets and showing users how to to get data from different sources and how various method parameters affect the output?
Hi Art, Each file format comes with code snippets in the article. If you're unable to see it - I suggest trying to open the article in a different browser. All the code is present in the article. Thanks, Pranav