This article was published as a part of the Data Science Blogathon
The choice of good hyperparameters determines the success of a neural network model
Introduction
In this article, I’m gonna cover Keras tuner. I hope you have some knowledge on how to make deep learning models and how to build neural networks. But the problem is that you cannot always figure out how many hidden layers to use, how many numbers of neurons to use in each network, what activation function to
use, what should be the learning rate.
There are so many hyperparameters and the only practical solution for that normally is experimenting. By using
multiple for loops you can change the number of layers in your model, change the activation functions, and also the number of neurons. There is a very amazing library called “Keras tuner” which automates the process to a
very good extent.
Let’s get into the practical implementation in Python.
Keras tuners are of three types. They are
- Random Search keras tuner
- Hyperband keras tuner
- Bayesian optimization keras tuner
In this article, I’m gonna implement the Random Search keras tuner.
Installation
The very first step is to install the keras tuner.
You can do it with the following command.
pip install keras-tuner
Then we import TensorFlow as tf.
For the keras tuner library to work, you need the TensorFlow version of greater than 2.
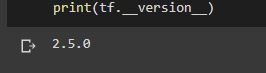
import tensorflow as tf print(tf.__version__)
Loading the dataset
Let’s solve the very basic problem of mnist dataset.
The next step is to get the mnist dataset. It is inbuilt inside TensorFlow.
I load the mnist dataset using this function and I separate the dataset into two classes. One is a train set and the other is a test set. I am dividing it by 255 to normalize the data. Because the dataset contains images and each pixel intensity is gonna range from 0 to 255.
While normalizing makes it easier for the neural network to learn that way. And you can see the shape of the dataset 60,000 images. Each image gonna be 28 x 28.
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
print("x_train.shape:", x_train.shape)

Now I am importing the necessary libraries. I import a module called layers
which will help in building the model. From kerastuner.tuners I am importing RandomSearch. This will help
us to sort the different hyperparameters, different combinations of different
models. So we can see which model is the best.
from tensorflow import keras from tensorflow.keras import layers from kerastuner.tuners import RandomSearch
Tuning with keras tuner
Now I will build a model_build function. The argument hp stands for hyperparameter. This argument
will be useful to try different hyperparameters.
def build_model(hp):
model = keras.Sequential()
model.add(layers.Flatten(input_shape=(28,28)))
model.add(layers.Dense(units=hp.Int('units', min_value=32, max_value=512, step=128), activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
model.compile(optimizer=keras.optimizers.Adam(hp.Choice('learning_rate', values=[1e-2, 1e-4])),
loss = 'sparse_categorical_crossentropy', metrics = ['accuracy'])
return model
Here we are creating a neural network. We start by writing keras.Sequential()because we want to add all the layers in a sequence. Next comes the input layer. Here I am specifying the input shape equal to 28 x 28. And I give Flatten.
The images are two-dimensional. If I give Flatten, it will flatten it into a single dimension which can be provided to the neural network.
The next step is adding the next hidden layer. Now there are different hyperparameters. You
can vary the number of hidden layers. Right now, I am not doing that. I am only varying the number of neurons in each layer. We will get into those complex steps later.
In each hidden layer, you can have any number of neurons. We specify the parameter units equal to hp. Int because this variable is going to be an integer number.
We also specify the minimum and maximum values. The step size = 128 is given which will check the first value is 32 and the next value is 160 and so on.
The activation function used is relu which normally works well. After that, I am adding an output layer. The output layer has 10 neurons because we have 10 classes of 10 digits and the activation function is SoftMax. I am compiling the model using Adam optimizer. Even in Adam optimizer, there can be much learning
rates.
So I am using hp.Choices to try with a limited number of choices. I am giving two values as an option. The loss function used is categorical_crossentropy and the metrics are accuracy. Now we have defined our
model.
Instantiate HyperModel with RandomSearch
The next step is that you have to create an instance of this class. I am calling RandomSearch class in
which the following parameters are provided.
First, we provided our built model function and then the objective. In this case, we are going to maximize the
validation accuracy. Then the maximum number of trials. This is very important because when you give so many hyperparameters, there can be so many permutations and combinations. The max_trials = 5 says that we are only gonna try five times. execution_per_trial = 3 indicates that each trial will try with three different models.
This will save a lot of time.
tuner = RandomSearch(
build_model,
objective = 'val_accuracy',
max_trials = 5,
executions_per_trial = 3,
)
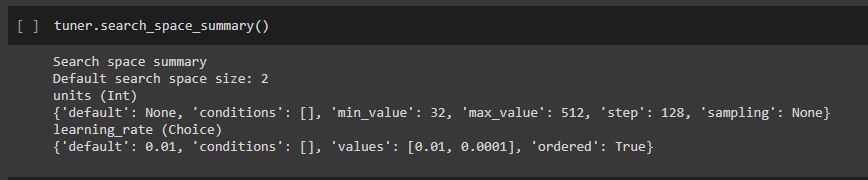
tuner.search_space_summay() will indicate how many hyperparameters you are checking for.
tuner.search_space_summary()
Fitting the model
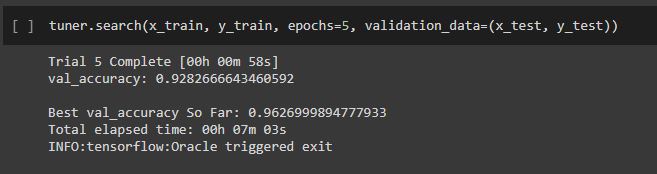
The next thing to do is fitting the model. Here, tuner.search works like model.fit.
tuner.search(x_train, y_train, epochs=5, validation_data=(x_test, y_test))
The results can be checked by using results_summary().
tuner.results_summary()
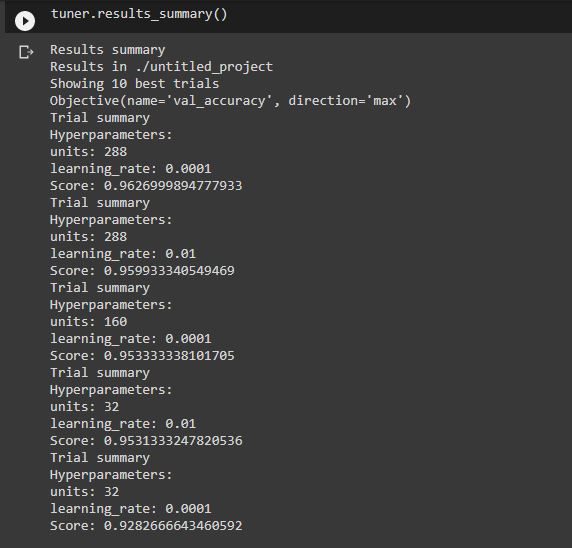
You can see that the best accuracy is 96.26%. For that, the hyperparameters are a learning rate of 0.0001 and the number of units is 288.
Determine the number of hidden layers
Now I am going to show you how to add a different number of hidden layers.
For that, I am using a for a loop. For hidden layers again I am using hp.Int because the number of layers is an integer value. I am gonna vary it between 2 and 6 so that it will use 2 to 6 hidden layers. The step size is gonna be 1 by default. In each hidden layer, we are varying the number of units.
When you give ‘units_+str(i)’ it will print units 1, units 2, units3, and so on depending on upon which hidden
layer you are inside. This is useful for tracking. And again the number of nodes in each layer is 50 to 100 and the step size is 10.
Activation is going to be a list of choices. It can be relu, tanh, sigmoid and so on. Finally, in the output
layer, we have 10 output neurons corresponding to 10 output classes. Here we use the softmax activation function. I am just using the adam optimizer, sparse_categorical_crossentropy as loss function, and the metrics as accuracy.
def build_model2(hp):
model = tf.keras.Sequential()
model.add(layers.Flatten(input_shape=(28,28)))
for i in range(hp.Int('layers', 2, 6)):
model.add(tf.keras.layers.Dense(units=hp.Int('units_' + str(i), 50, 100, step=10),
activation=hp.Choice('act_' + str(i), ['relu', 'sigmoid'])))
model.add(tf.keras.layers.Dense(10, activation='softmax'))
model.compile('adam', 'sparse_categorical_crossentropy', metrics=['accuracy'])
return model
Again, we create an instance using RandomSearch.
tuner2 = RandomSearch(
build_model2,
objective = 'val_accuracy',
max_trials = 4,
executions_per_trial = 1,
directory = '/content/sample_data'
)
Now, I am printing the search space.
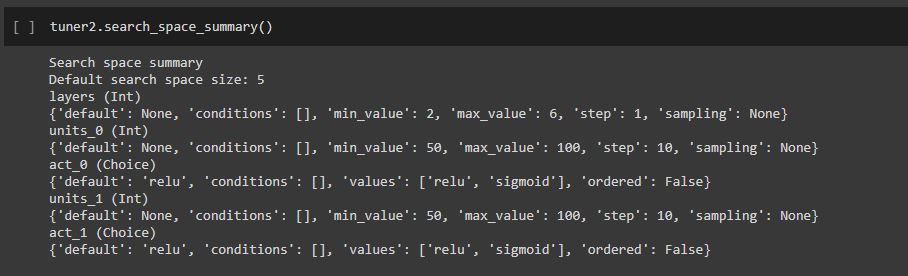
tuner2.search_space_summary()
Next, we will fit the model.
tuner2.search(x_train, y_train, epochs=5, validation_data=(x_test, y_test))
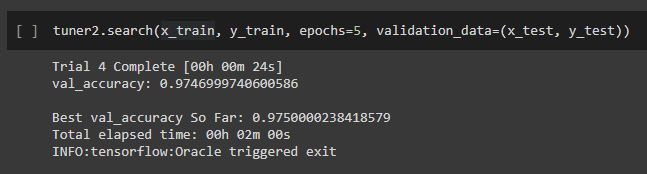
In the trial summary, the best accuracy is 97.50 % and you can see the combinations as well.
tuner2.results_summary()
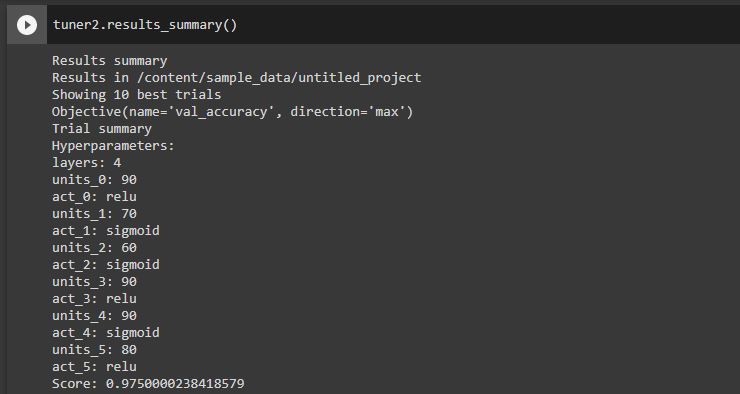
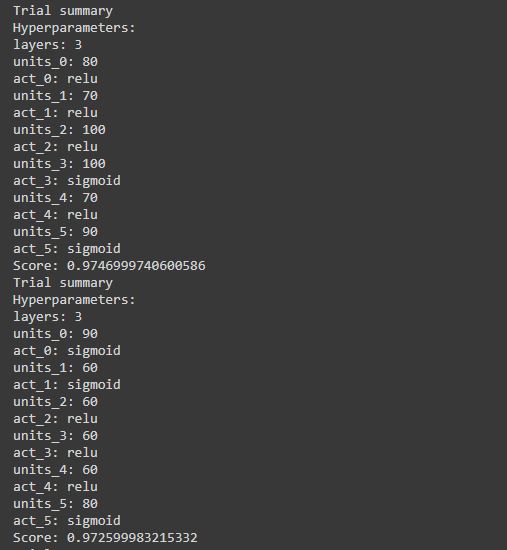
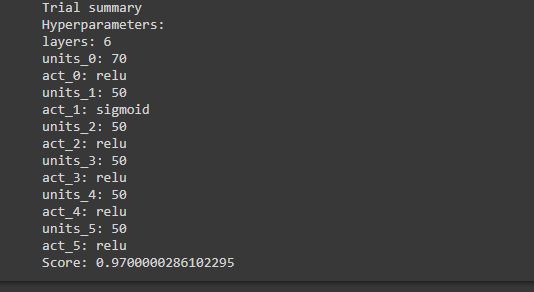
This is so good right.
You can analyze what is the best parameter.
Also, You can extend this for convolutional neural networks as well. You can change the number of filters
in each layer.
References
https://keras-team.github.io/keras-tuner/
https://iopscience.iop.org/article/10.1088/1755-1315/577/1/012012/meta
Endnotes
Keras tuner is such a wonderful library that can help you to check the different combinations of the
different parameters and select which parameter suit best for your model.
In this article, we discussed the keras tuner library for hyperparameter tuning and implemented
keras tuner for mnist dataset, and analyzed the performance of the model by tuning the parameters. I hope you found this article helpful and start building your model and enjoy learning.
The media shown in this article on Sign Language Recognition are not owned by Analytics Vidhya and are used at the Author’s discretion.




Why for every trial summary, it displays all 6 parameters even number of layers is 3 or 4?? it uses all the hidden layers regardless of layers hyperparameter?
Hello Dhanya, Thank you so much for the detailed explanation of Keras tuner steps. I have a small doubt regarding the tuner2.results_summary(), irrespective of the number of layers, we are adding the unit values. for example, first trial summary, layers is 3 but units gets added from units_0 to units_5. Could you please explain this part of the result. Thank you in advance.
Dear Dhanya Thailappan Inlayers number we see for example 4 layers but again we have 6 unit numbers from 0 to 5 that each has its own neuron number. why is it like that? when we say the layer number is 4 shouldn't we have only 4 unit numbers from 0 to 3?