Master Computer Vision In Just A Few Minutes!
This article was published as a part of the Data Science Blogathon
Introduction
Human vision is lovely and complex. It all commenced billions of ages ago when tiny organisms developed a mutation that made them sensitive to light.
Fast forward to today, and life is abundant on the planet, which all have very similar visual systems. They include eyes for capturing light, receptors in the brain for accessing it, and visual cortex processing.
Genetically engineered and balanced pieces of a system help us do things as simple as appreciating a sunrise. But this is just the beginning.
In the past 30 years, we’ve made even more strides to extending this unique visual ability, not just to us but to computers as a whole.

A little bit of History

The first type of the photographic camera invented around 1816 was a small box that held a piece of paper coated with silver chloride. When the shutter was open, the silver chloride would darken when exposed to light.
Now, 200 years later, we have much more advanced versions of the system to capture photos right into digital form. So we’ve been able to nearly simulate how the human eye can apprehend light and shade. But it’s turning out that this was the easy part.
Understanding what’s in the photo is much more difficult.
Consider this picture below:

Our human brain can look at it and immediately know that it’s a flower. Our brains are tricking since we’ve got several million years’ worths of evolutionary context to directly understand what is better.
But a computer doesn’t have that same advantage. Instead, the image looks like just a massive array of integer values representing intensities across the color spectrum to an algorithm.
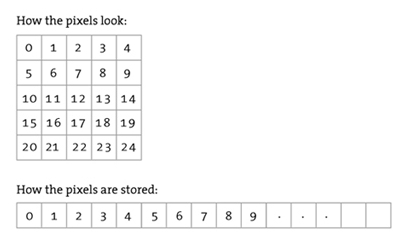
There’s no connection here, just a massive quantity of data. It turns out that context is the crux of getting algorithms to understand image content in the same way that the human brain does.
And to get this work, we practice an algorithm very comparable to how the human brain functions adopting machine learning. Machine learning enables us to adequately train the context for data so that an algorithm can learn what all these numbers in a particular group serve.
And what if we have images that are difficult for a human to classify? Can machine learning achieve better accuracy?
For example, let’s take a look at these images of sheepdogs and mops where it’s pretty hard, even for us, to differentiate between the two.
.png)
With the machine learning model, we can get a collection of images of sheepdogs and mops. Then, as deep as we feed it sufficient data, it will ultimately tell the variation among the two accurately.
Computer vision is taking on increasingly complex challenges and is seeing accuracy that rivals humans are performing the same image recognition tasks.
But like humans, these models aren’t perfect. So they do sometimes make mistakes. The specific type of neural network that accomplishes this is called a convolutional neural network or CNN.
Role of Convolutional Neural Networks in Computer Vision
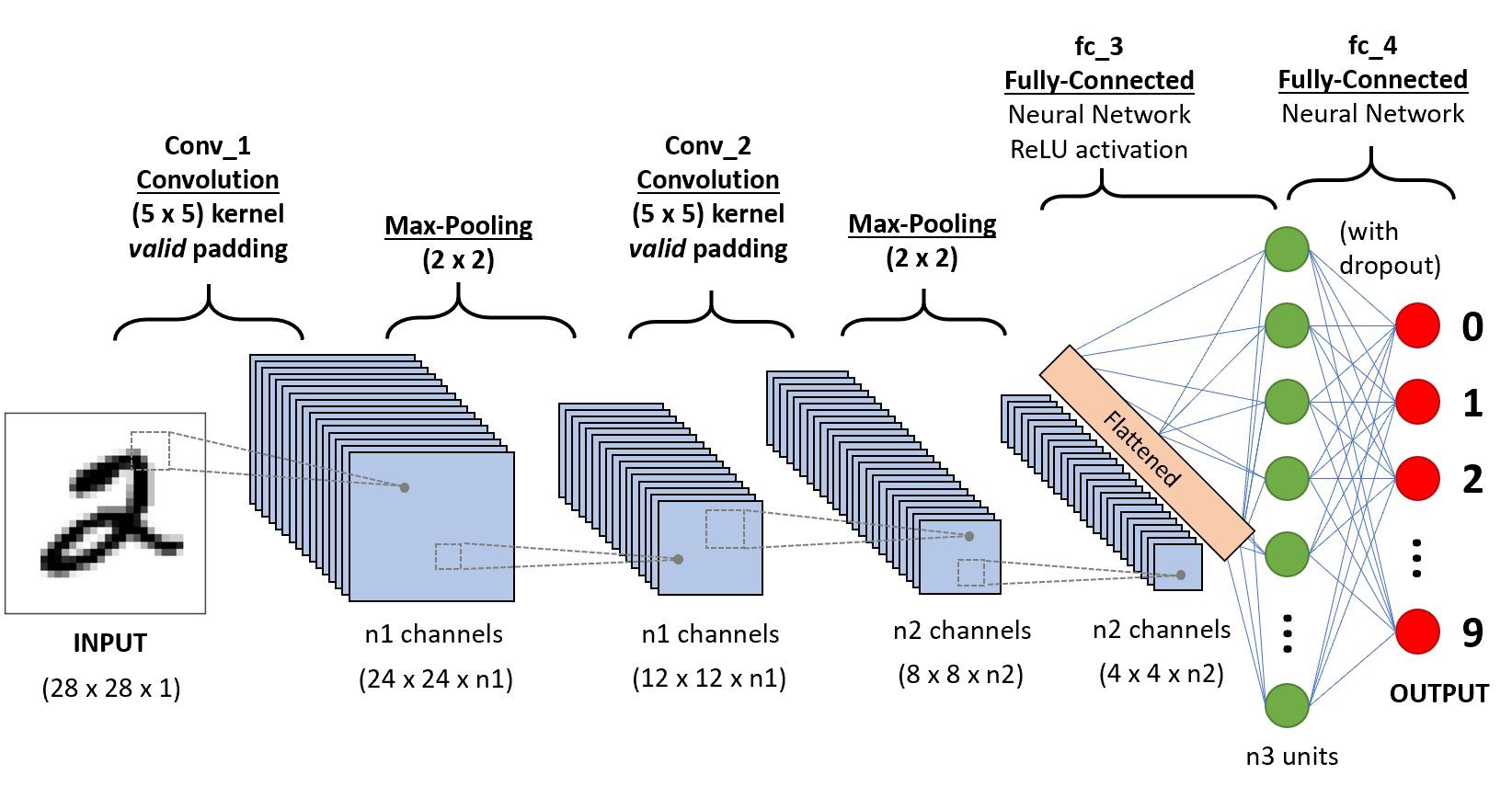
CNN operates by dividing a picture down into more petite groups of
pixels called a filter. Every filter is a matrix of pixel values. Then, the network performs calculations on these pixels, comparing them against pixels in a specific pattern the network is looking at.
In the initial layer of a CNN, it can recognize high-level patterns like uneven edges and sweeps. Then, as the network functions more convolutions, it can classify different things like faces and animals.
How does a CNN know what to look for and if its prediction is accurate?
A large amount of labeled training data helps in the process. When the CNN starts, all of the filter values are randomized. As a decision, its first predictions present slight sense.
Each time the CNN predicts labeled data, it uses an error function to compare how close its forecast was to the image’s actual label. Based on this error or loss function, the CNN updates its filter values and starts the process again. Ideally, each iteration performs with slightly more accuracy.
What if we want to explore a video using machine learning instead of analyzing a single image?
At its essence, a video is just a sequence of picture frames. To analyze footage, we can build on our CNN for image analysis. In noiseless pictures, we can apply CNNs to recognize features.
But when we shift to video, everything gets more complicated as the items we’re recognizing might evolve overhead time. Or, more likely, there’s a context between the video frames that’s highly important to labeling.
For example, if there’s a picture of a half-full cardboard box, we might want to label it packing a box or unpacking a box depending on the frames before and after it.

Now is when CNN’s come up lacking. They can take into spatial report characteristics, the visual data in a picture, but
can’t manipulate temporal or time features like how a frame is
similar to the one before it.
To address this issue, we have to take the output of our CNN and feed it into another model that can handle our videos’ temporal nature described as a recurrent neural network or RNN.
Role Of Recurrent Neural Networks in Computer Vision
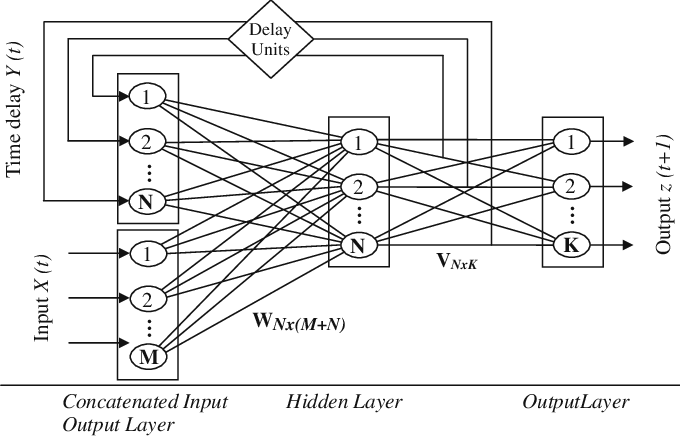
While a CNN treats groups of pixels independently, an RNN can retain information about its already processed and use that in its decision-making.
RNNs can manage various sorts of input and output data. An example of classifying videos, we train the RNN by passing it a sequence of frame descriptions
-empty box
-open box
-closing box
And finally, a label- packing.
As the RNN processes a specific sequence, it practices a loss or error function to match its predicted output amidst the correct label. Then it adjusts the weights and processes the series again until it achieves higher accuracy.
However, the challenge of these approaches to image and video models is that the amount of data we need to mimic human vision is tremendous.
If we train our model to analyze this photo of a duck, as long
as we’re given this one picture with this lighting, color, angle, and shape, we can see that it’s a duck.
Change any of that or even rotate the duck; the algorithm might not understand what it is anymore. So now, this is the signature design problem.
To get an algorithm to truly understand and recognize image content the way the human brain does, you need to feed it substantial amounts of data of millions of objects across thousands of angles, all annotated and adequately defined.
The problem is so big that if you’re a small startup or a
company lean on funding, there are just no resources available for you to do that.
Note: Consequently, technologies like Google Cloud Vision and Video can help. Google understands and filters millions of photographs and videos to train specific APIs. They introduced a network to extract all kinds of data from images and video so that your application doesn’t have to. With just one REST API request, they can access a powerful pre-trained model that gives us all sorts of data.
Conclusion
Billions of years since the evolution of our sense of sight, we found that computers are on their way to matching human vision. Computer vision is an innovative track that practices the latest machine learning technologies to construct software systems that help humans beyond complex areas. From retail to wildlife preservation, intelligent algorithms unlock image classification and pattern recognition problems, sometimes even thoroughly than humans.
About Author
Mrinal Walia is a professional Python Developer with a Bachelors’s degree in computer science specializing in Machine Learning, Artificial Intelligence and Computer Vision. Mrinal is also an interactive blogger, author, and geek with over four years of experience in his work. With a background working through most areas of computer science, Mrinal currently works as a Testing and Automation Engineer at Versa Networks, India. My aim to reach my creative goals one step at a time, and I believe in doing everything with a smile.
Medium | LinkedIn | ModularML | DevCommunity | Github
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.







