Working on a Project on image recognition or Object Detection but didn’t have the basics to build an architecture? In this article, we will see what are convolutional neural network architectures right from basic and we will take a basic architecture as a case study to apply our learnings, The only pre-requisite is you just need to know how convolution works But don’t worry it is very simple !!
Let us take a simple Convolutional neural network,
This article was published as a part of the Data Science Blogathon.

Table of contents
CNN: Layer-Wise Exploration of Striding and Padding
We will go layer-wise to get deep insights about this Convolutional Neural Network
First, there are few things to learn from layer 1 that is striding and padding, we will see each of them in brief with examples
Suppose we have an input matrix of 5×5 and a filter matrix of 3×3. For those unfamiliar with filters, they are sets of weights in a matrix applied to an image or another matrix to extract specific features. If this is your first time encountering this, please search for more information on convolution!
Note: We always take the sum or average of all the values while doing a convolution.
A filter can be of any depth, if a filter is having a depth d it can go to a depth of d layers and convolute i.e sum all the (weights x inputs) of d layers

Here the input is of size 5×5 after applying a 3×3 kernel or filters you obtain a 3×3 output feature map so let us try to formulate this

So the output height is formulated and the same with o/p width also…
Padding
While applying convolutions we will not obtain the output dimensions the same as input we will lose data over borders so we append a border of zeros and recalculate the convolution covering all the input values.
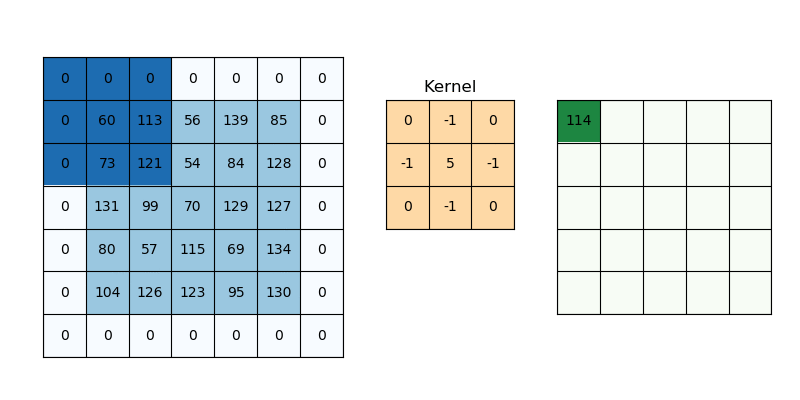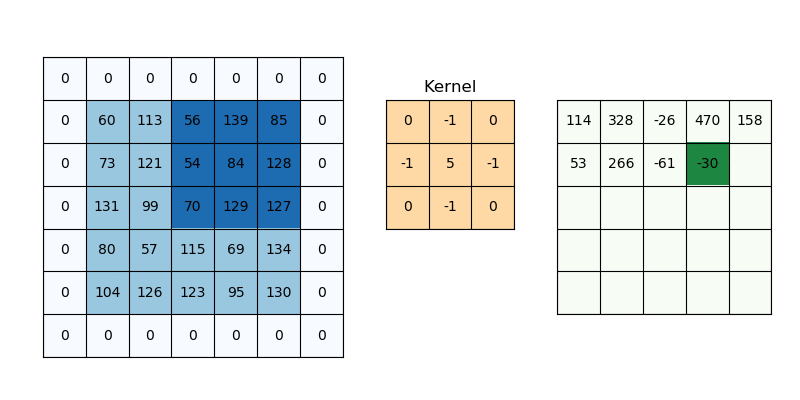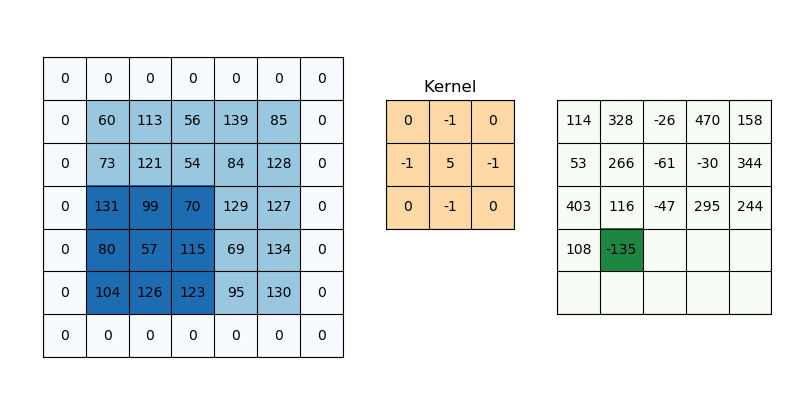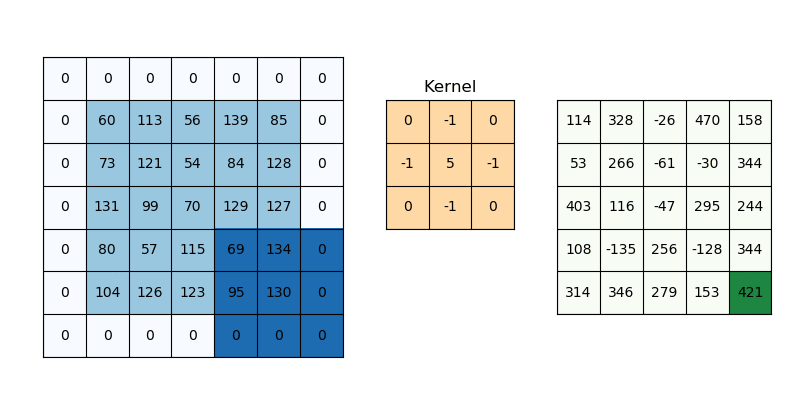
We will try to formulate this,

Here 2 is for two columns of zeros along with height and width, and formulate the same for width also
Striding
Some times we do not want to capture all the data or information available so we skip some neighboring cells let us visualize it,
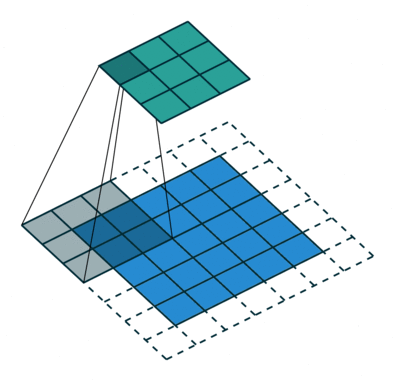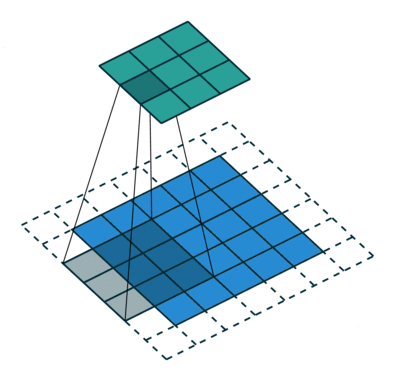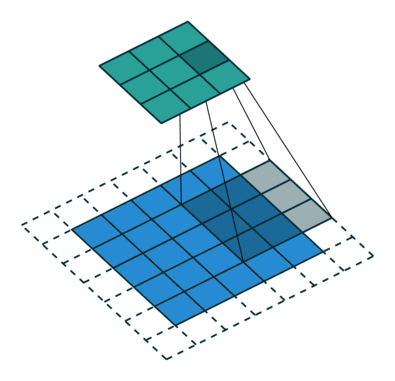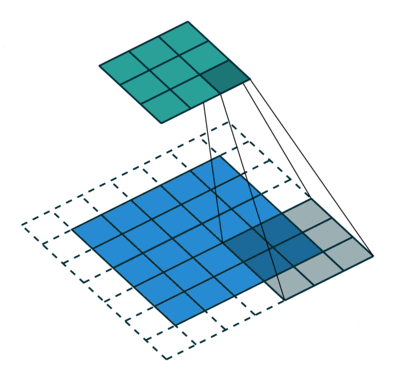
Here the input matrix or image is of dimensions 5×5 with a filter of 3×3 and a stride of 2 so every time we skip two columns and convolute, let us formulate this

If the dimensions are in float you can take ceil() on the output i.e (next close integer)
Here H refers to height, so the output height is formulated and the same with o/p width also and here 2 is the stride value so you can make it as S in the formulae.
Pooling
In general terms pooling refers to a small portion, so here we take a small portion of the input and try to take the average value referred to as average pooling or take a maximum value termed as max pooling, so by doing pooling on an image we are not taking out all the values we are taking a summarized value over all the values present !!!

here this is an example of max pooling so here taking a stride of two we are taking the maximum value present in the matrix
Activation function
The activation function is a node that is put at the end of or in between Neural Networks. They help to decide if the neuron would fire or not. We have different types of activation functions just as in the figure above, but for this post, my focus will be on Rectified Linear Unit (ReLU)

Don’t drop your jaws, this is not that complex this function simply returns 0 if your value is negative else it returns the same value you gave, nothing but eliminates negative outputs and maintains values between 0 to +infinity
Now, that we have learned all the basics needed let us study a basic neural net called LeNet.
Read More: Activation Functions Neural Networks
LeNet-5
Before starting we will see what are the architectures designed to date. These models were tested on ImageNet data where we have over a million images and 1000 classes to predict

LeNet-5 is a very basic architecture for anyone to start with advanced architectures

What are the inputs and outputs (Layer 0 and Layer N) :
Here we are predicting digits based on the input image given, note that here the image is of dimensions height = 32 pixels, width = 32 pixels, and a depth of 1, so we can assume that it is a grayscale image or a black and white one, keeping that in mind the output is a softmax of all the 10 values, here softmax gives probabilities or ratios for all the 10 digits, we can take the number as output with highest probability or ratio.
Convolution 1 (Layer 1) :

Here we are taking the input and convoluting with filters of size 5 x 5 thereby producing an output of size 28 x 28 check the formula above to calculate the output dimensions, the thing here is we have taken 6 such filters and therefore the depth of conv1 is 6, hence its dimensions were, 28 x 28 x 6 now pass this to the pooling layer
Pooling 1 (Layer 2) :

Here we are taking the 28 x 28 x 6 as input and applying average pooling of a matrix of 2×2 and a stride of 2 i.e hovering a 2 x 2 matrix on the input and taking the average of all those four pixels and jumping with a skip of 2 columns every time thus giving 14 x 14 x 6 as output we are computing the pooling for every layer so here the output depth is 6
Convolution 2 (Layer 3) :

Here we are taking the 14 x 14 x 6 i.e the previous o/p and convoluting with a filter of size 5 x5, with a stride of 1 i.e (no skip), and with zero paddings so we get a 10 x 10 output, now here we are taking 16 such filters of depth 6 and convoluting thus obtaining an output of 10 x 10 x 16
Pooling 2 (Layer 4):

Here we are taking the output of the previous layer and performing average pooling with a stride of 2 i.e (skip two columns) and with a filter of size 2 x 2, here we superimpose this filter on the 10 x 10 x 16 layers therefore for each 10 x 10 we obtain 5 x 5 outputs, therefore, obtaining 5 x 5 x 16
Layer (N-2) and Layer (N-1) :

Finally, we flatten all the 5 x 5 x 16 to a single layer of size 400 values an inputting them to a feed-forward neural network of 120 neurons having a weight matrix of size [400,120] and a hidden layer of 84 neurons connected by the 120 neurons with a weight matrix of [120,84] and these 84 neurons indeed are connected to a 10 output neurons

These o/p neurons finalize the predicted number by softmaxing .
How does a Convolutional Neural Network work actually?
It works through weight sharing and sparse connectivity,

So here as you can see the convolution has some weights these weights are shared by all the input neurons, not each input has a separate weight called weight sharing, and not all input neurons are connected to the output neuron a’o only some which are convoluted are fired known as sparse connectivity, CNN is no different from feed-forward neural networks these two properties make them special !!!
How to build layers used to construct ConvNets
Here are the types of layers used to build ConvNets:
- Input Layer: Think of it as the ground floor, where the raw image data enters the CNN.
- Convolutional Layer: This is where the magic happens! Like skilled workers constructing walls, convolutional filters slide across the image, detecting patterns and extracting features.
- Pooling Layer: This is like a foreman optimizing the construction process. Pooling reduces the image size, making computations faster and reducing memory usage.
- Activation Layer: This is like adding color and vibrancy to the building. Activation functions introduce non-linearity, allowing the network to learn complex relationships between features.
- Fully Connected Layer: This is like the top floor, where all the features come together for the final decision. The network takes in the extracted features and classifies the image.
- Output Layer: This is like the roof, where the final classification result is displayed.
Points to look at
- After every convolution the output is sent to an activation function so as to obtain better features and maintaining positivity eg: ReLu
- Sparse connectivity and weight sharing are the main reason for a convolutional neural network to work.
- The number of filters between layers, along with padding, stride, and filter dimensions, is chosen through experimentation. Don’t worry about that for now; focus on building a strong foundation. One day, you’ll conduct those experiments and create a more effective model!
FAQs
Q1. Is CNN supervised or unsupervised?
CNNs are versatile machine learning algorithms capable of both supervised and unsupervised learning.. In supervised learning, the CNN is trained on labeled data, while in unsupervised learning, it is trained on unlabeled data.
Q2. Why CNN is better than Ann?
Differences between CNNs and ANNs:
1. specialized for image-related tasks.
2. capable of extracting local features from images.
3. Can share weights across different parts of the image.
4. Can learn hierarchical representations of images.
5. Tasks: Image classification, object detection, image segmentation, facial recognition. ANN
6. Suitable for a wider range of tasks, including image classification, but not as specialized as CNN.
7. capable of learning from non-image data.
8. Tasks: regression, classification of non-image data, time series forecasting, natural language processing
Q3. What is loss layer in CNN?
In CNNs, the loss layer measures how well the network’s predictions match the actual data. It helps the network improve its performance by adjusting its weights.
Hi Folks, I am Phani Ratan. I have a keen interest in exploring deep learning and computer vision concepts to the core. I believe explaining something to someone will make you 0.01 times better than what you know now. I'm on a mission to make concepts clear and interesting for everyone. support me on this mission by commenting on my posts. Thank you






Hi, I am a graduate student at University of Texas at Dallas. I would like to reuse one of your illustrations on CNN from this article for my thesis report with proper citation if you give me the permission to do so. Thanks in advance. Best, Saquib Irtiza Graduate Student University of Texas at Dallas
EXCELLENT EXPLANATION!!
Thanks Kamala! , Will try to contribute more like this