This article was published as a part of the Data Science Blogathon
Introduction
In a series of three articles, I’ll describe the process of estimation, creating confidence intervals, and hypothesis testing. Information about these topics is present in various textbooks, documents, and websites. But these sources rarely explain the intuition behind the concepts. You can indeed use statistical software and easily compute estimates, confidence intervals or even perform hypothesis testing. But, as Adeleke Adeite quoted,
“Having the right information without proper application is like food ingestion without digestion.”
My purpose is to acquaint you, my readers, with the essence and fundamental thinking behind the trinity of statistical sciences- estimation, confidence intervals, and hypothesis testing. Instead of adopting the usual course of definition, formulae, and numerical, I’ll use a different approach. I’ll first describe a very basic example, proceed with some statistical modelling, apply some theorems, and arrive at the required concepts. I’ll gradually introduce the terminologies and formulae as we move forward with the example
Pre-requisites:
1) Probability: Basic ideas about random variables, mean, variance, and probability distributions. If you’re not familiar with these ideas, then you can read my article on ‘Understanding Random Variables’ here.
2) Patience: I might be repetitive sometimes during the write-up. But I truly believe that repetition reinforces learning. Just as flowing water needs to repeatedly crash against the rocks to break them and flow ahead, we need to repeatedly revise concepts to master them and progress in our academic voyage.
3) Passion: Finally, reading about something without possessing passion is like knowing without learning. Real learning comes when you have a passion for the subject and the concept that is being taught.
Topics:
A) Introduction & Theoretical Notion
B) Primitive Mathematical Formulation
C) Statistical Modelling & Related Assumptions
D) Foundations of Estimation
E) The play of the Law of Large Numbers & the Central Limit Theorem
F) Goodness of Estimator
Our Example:
A) Introduction & Theoretical Notion
Consider a beverage company that has decided to set up a unit in Mumbai, a city in India. The company is, however, not sure if it must produce more amount of tea or coffee. So, it decides to hire you, a statistician to survey the people of Mumbai and determine the proportion of people who prefer tea over coffee. Due to limited resources, it won’t be possible for you to survey the entire population of Mumbai. Instead, you decide to survey a small sample of the population, say, 850 people. You ask of each of them whether they prefer tea or coffee, and note down the data in 0s and 1s, where:
0: Indicates that the person prefers coffee over tea.
1: Indicates that the person prefers tea over coffee.
From your data, you found out that 544 people prefer tea over coffee, while the remaining (306) people prefer coffee over tea. In other words, 64% of the sample population prefers tea over coffee. As a statistician, we are interested in knowing the following:
1) Can we reasonably conclude that around 64% of Mumbai’s population prefers tea over coffee? How can we evaluate the performance of our estimate? These questions will be answered under the domain of estimation.
2) How sure/confident are we about our estimate? Is there a range of possible outcomes that the estimate can take depending upon how confident we want to be? What is this range? These questions will be answered under the domain of confidence intervals.
3) The beverage company does not care about all these formulations. What it wants is only a yes/no answer to whether the population prefers tea over coffee in general. How do I compute this answer? Is my sample size too small to conclude that the company must produce more tea? These questions will be answered under the domain of hypothesis testing.
I hope that by the end of this series of three articles, you’ll be able to answer all these questions, not only particular to the given example, but also for other scenarios you encounter in your day-to-day life. Lets’ start by mathematically formulating our example.
B) Primitive Mathematical Formulation
We’ll first define our random variable. Let Xi be our random variable, which takes the value 0 or 1 depending upon whether the person ‘i’ prefers tea or coffee. A random variable is a function that assigns the sample space of an experiment to real numbers. In our example, the random variable Xi takes in the preference of the person ‘i’ and assigns it a number from the set {0, 1}. For instance, if the 2nd person in our sample prefers coffee over tea, we say X2=0. Why is it called random? Because there’s no fixed value that can be assigned to it. The value that a random variable takes depends upon the sample that we’ve chosen and is therefore not deterministic in nature. It’s also important to note that the random variable Xi is a discrete random variable since it has a countable range (the set {0, 1}).
Let
the sample size for our experiment/survey be ‘n’. If we assign a random variable to measure each person’s preference in our population, then it gives us a sequence of n random variables X1, X2, …, Xn. For our case, n=850 as we are surveying 850 random people from the population
of Mumbai. This allows us to define the following sequence of random variables:
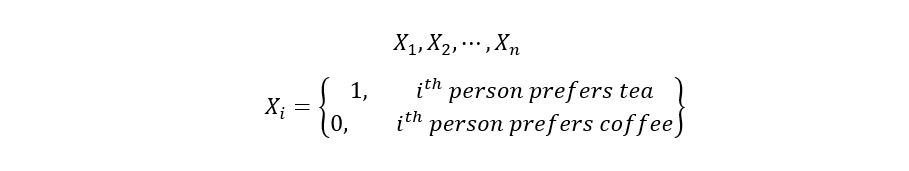
We shall now investigate the distribution of Xi. Let ‘p’ refer to the true proportion of Mumbai’s population that prefers tea over coffee. In other words, if we go out and ask every person in Mumbai about their preference, then exactly p% of the population will prefer tea. But as discussed earlier, it would not be possible to do so due to finite resources for surveying. So, we end up trying to estimate the true p. We’ll call our estimator for p as p-hat. The very basic goal of estimation is to find p-hat, such that the distance between p and the estimated value of p-hat is minimum i.e., we want p-hat to be as close to p as possible.
Note:
- In general, the notation for estimators is a hat over the parameter we are trying to estimate i.e. if θ is the parameter we’re trying to estimate, then the estimator for θ is represented as θ-hat.
- Right now, it’s enough to think of estimators as something that’ll allow us to estimate the true value of the unknown parameter. A more formal definition will be explained later.
- We’ll use the terms estimator and estimate interchangeably because the estimator is essentially the function that gives the estimated value.
That’s the idea behind estimation. Now we’ll determine the distribution of Xi. Since Xi can take only the binary values 0 and 1, Xi is said to follow a Bernoulli distribution with parameter p. What’s p? The probability that Xi takes the value 1 is p, and the probability that Xi takes the value 0 is 1-p. This can be shown as follows:
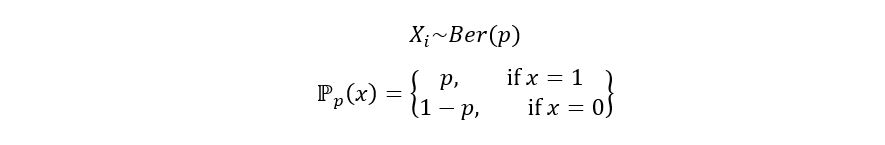
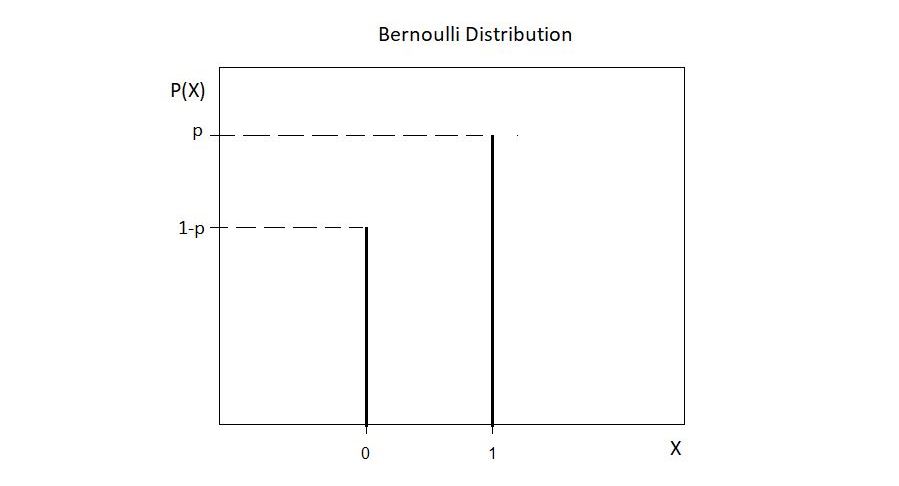
Here, ℙp(x) is the probability mass function (PMF) of Xi. The following figure is the graphical representation of the above distribution:
To understand the distribution of Xi better, we’ll calculate the expectation and variance of the distribution:
1) Expectation of Xi: The expectation of a random variable is like its weighted average. For discrete random variables, it is calculated using the following equation:
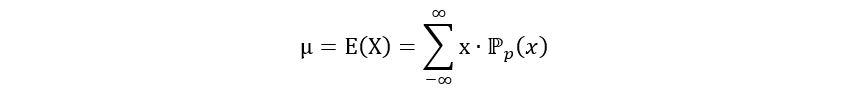
In our case, the expectation is calculated as follows:
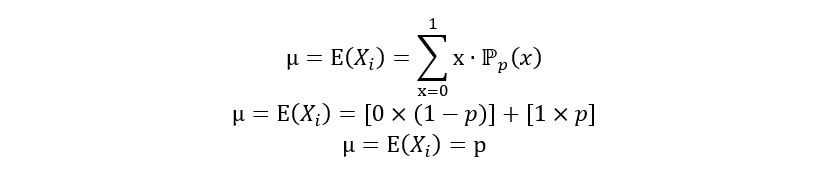
2) Variance of Xi: The variance of random variable shows the spread of its distribution. For discrete random variables, it is calculated using the following equation:
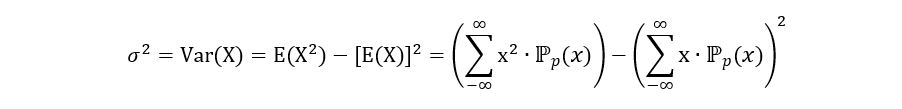
In our case, the variance is calculated as follows:
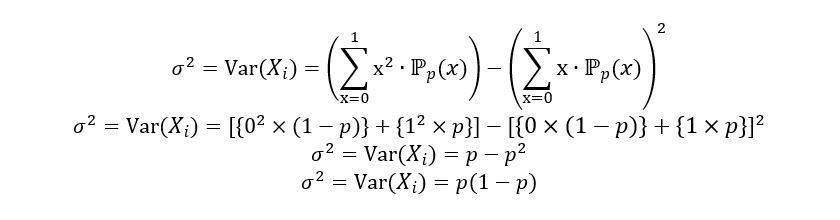
Once we have obtained the variance of Xi, we can easily calculate the standard deviation (square root of variance) as follows:
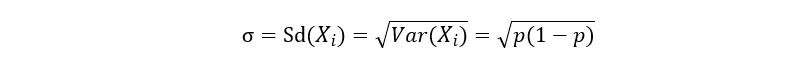
C) Statistical Modelling & Related Assumptions
Under this section, we’ll create a formal statistical model of our experiment. This will require us to make a few assumptions:
1) All the Xi’s are random variables. This assumption is quite intuitive and has been explained before.
2) All the Xi’s are independent. This essentially means that the value a particular Xi takes does not depend upon the value of another random variable Xj. In the context of our example, we assume that one person’s preference is not influenced by another person’s preference.
3) All the Xi’s are identically distributed. That is, they follow the same distribution (Bernoulli) with the same parameter (p).
Often, we club all these assumptions and simply say X1, X2, …, Xn are i.i.d (independent and identically distributed) random variables. These assumptions will also play a pivotal role in the application of various laws/theorems (as will be discussed in the next few sections). Now we are ready, to begin with, the modeling.
Statistical modeling involves using observable data to capture the truth or the reality. Of course, it’s not possible to capture the entire truth. So, our will be to understand as much reality as possible.
In general, a statistical model for a random experiment is the pair:
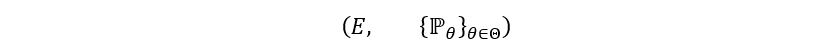
There are a lot of new variables! Let’s understand them one by one and create a statistical model specific to our example.
1) E represents the sample space of the experiment. It’s the range of values that a random variable X associated with a statistical experiment can take. In our case, the random variable Xi can take only two values- 0 (indicating preference of coffee over tea) & 1 (indicating preference of tea over coffee). Hence, for our example, E = {0, 1}
2) ℙθ represents the family of probability measures on E. In simple words, it indicates the probability distribution of the random variable assigned to the experiment. In our case, Xi follows a Bernoulli distribution with parameter p. Hence, for our example, ℙθ = Ber(p)
3) θ represents the set of unknown parameters that characterize the distribution ℙθ. For our example, there is only one unknown parameter-p. Hence, θ = p
4) Θ represents the parameter space i.e., the set of all possible values that the parameter θ could take. In our case, p takes only values between 0 and 1. Thus, Θ = [0, 1]. Why only numbers between 0 and 1? Because p itself shows the probability that Xi = 1, and probability always ranges between 0 and 1.
Using all the above information, we arrive at the following statistical model for our experiment/example:
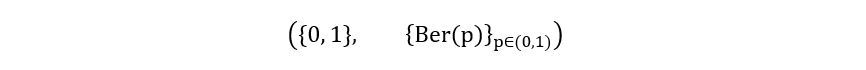
D) Foundations of Estimation
Now, that we know the model for the experiment and the distribution of X, we’ll talk more about the estimator p-hat.
What’s an estimator? At the primitive level, we thought of estimators as a function that can estimate the value of an unknown parameter. However, there’s also a less intuitive, but formal definition of an estimator. Accordingly, an estimator is a statistic that does not depend upon the true parameter. It’s a statistic means that it’s a measurable function of the sample/data i.e., it can be calculated from the given data. Of course, it must not depend upon the true parameter p. If the estimator p-hat was dependent on the true p, how would we ever determine the true p?
Let’s think of a very basic estimator for p. It could be the sample average. The sample average is just the mean of our observations. In our example, the sample average is the proportion of 1s in our data set. Mathematically,
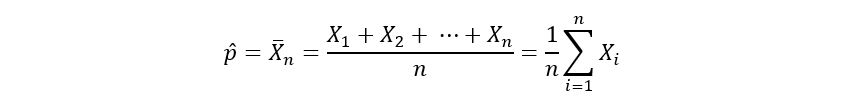
Like X1, X2, …, Xn, the estimator p-hat is also a random variable since its value depends upon the sample that we’re taking. This will allow us to explore some basic, but important mathematical properties of p-hat such as its expectation and variance. (Note: The calculations involve using the properties of expectation and variance.)
1) Expectation of p-hat: We’ll use the property of linearity of expectation to derive the expectation of the sample average estimator as follows:
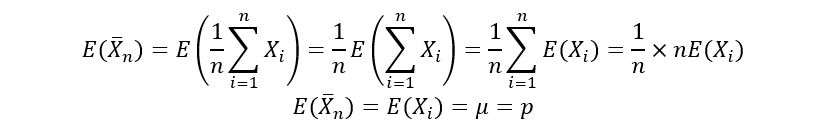
Properties used:
1. E(aY + b) = aE(Y) + b, where Y is a random variable, a and b are constants.
2. E(Y1 + Y2) = E(Y1) + E(Y2), where Y1 and Y2 are random variables.
2) Variance of p-hat: Since our random variables X1, X2, …, Xn are independent, we can use the property that variance of the sum of random variables is the sum of the variances of the random variables, and calculate the variance of p-hat as follows:
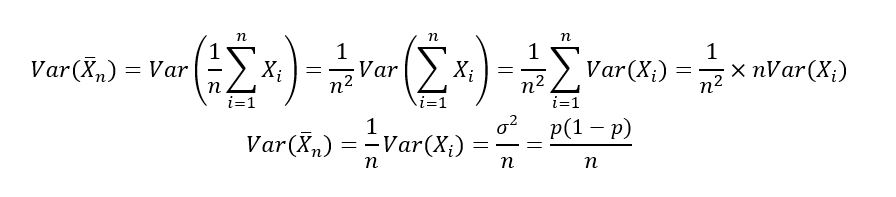
Properties used:
1. Var(aY + b) = a2Var(Y), where Y is a random variable, a and b are constants.
2. Var(Y1 + Y2) = Var(Y1) + Var(Y2), where Y1 and Y2 are independent random variables.
Finally, as previously done, we can calculate the standard deviation of the sample means estimator as follows:
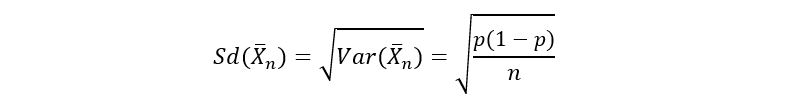
Let’s calculate the value of the estimator for our data:
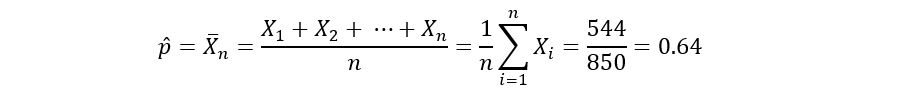
So, our estimated value for p, p-hat seems to indicate that people tend to prefer tea over coffee in Mumbai. That makes us wonder if the same understanding was true when p-hat=0.54. What if p-hat was 0.52? What’s that benchmark value for p-hat beyond which we can conclude that people prefer tea over coffee? To answer these questions, we need to use some famous statistical laws and theorems.
Note: This particular article will focus purely on estimation. The answer to the above questions can be found in the realm of hypothesis testing, which will be dealt with in the third article of the series. But estimation lies at the core of hypothesis testing, and thus an understanding of this article is crucial.
E) The play of the Law of Large Numbers & the Central Limit Theorem
It’s time to use two very important laws that are really like the foundation of statistical inference:
1) Law of Large Numbers (LLN): In simple words, the law of large numbers states that as our sample size grows bigger (approaches infinity), the sample average converges to the true mean of the underlying distribution. That is if X1, X2, …, Xn are i.i.d random variables, then
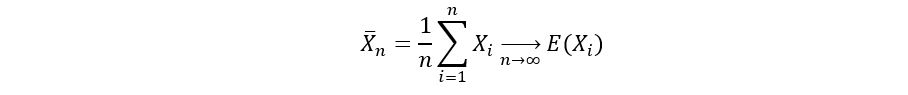
In our case E(Xi) = p, which gives us the following convergence:
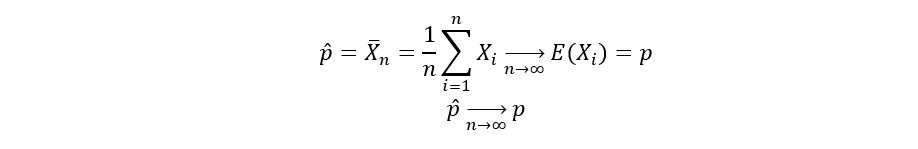
This is a very important and beneficial property of the estimator p-hat. It’s called consistency. It allows the estimator p-hat to become closer to the true value of the unknown parameter p as the sample size n approaches infinity.
Note: There are two forms of the LLN- the weak LLN and the strong LLN. Under the weak LLN, the convergence is said to happen “in probability”. Under the strong LLN, the convergence is said to happen “almost surely”. The distinction between different modes of convergence is not of much importance for the purpose of this article.
2) Central Limit Theorem (CLT): The central limit theorem allows us to garner information about the probability distribution of the estimator p-hat. It states that for large sample sizes (once again as n approaches infinity), the standardized sample average will approximately be normally distributed with mean 0 and variance 1 (i.e., will converge to a standard normal distribution). Piecewise explanation:
- Standardization of a random variable: The process of standardization involves:
i) Subtracting the expectation from the random variable.
ii) Dividing the above difference by the mean of the random variable.
In general, If Y is a random variable, then its standardized form is shown as:
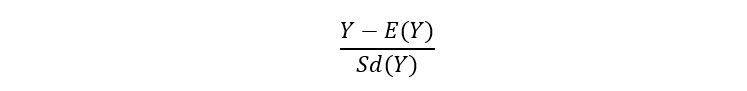
Similarly, for the sample mean estimator (remember even p-hat is a random variable), the standardized form is shown as:
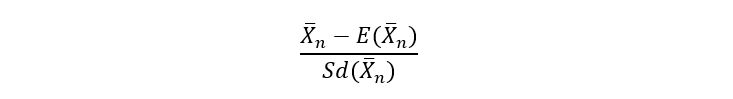
Substituting the value of the mean and standard deviation of the estimator (as derived before), we arrive at the following standardized form of p-hat:
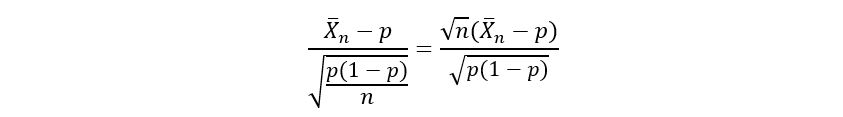
b) Normally distributed: A normal/gaussian distribution is one of the most important probability distributions in statistics. You can read more about the normal distribution here.
So, the application of CLT for any random variable Y, in general, gives us the following convergence:
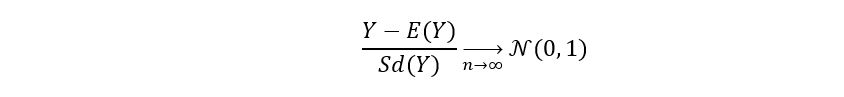
For our example, we arrive at:
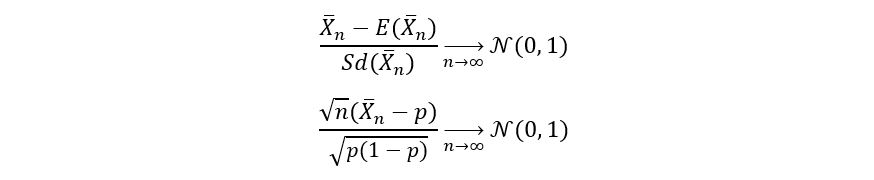
What does the convergence indicate? It basically shows that as our sample size grows big the standardized p-hat will be normally distributed. This is a very important property and will be used throughout statistical inference including the construction of confidence intervals and in hypothesis testing. In fact, this property of estimators is called asymptotic normality. Asymptotic normality makes it easier to play with the random variables and draw a suitable inference. Computational procedures also become very direct and simplified in the domain of normal distribution, primarily because we know a lot about it.
F) Goodness of Estimator
Till now, we have probably managed to construct a fair idea of what estimation is all about. But one question that you might have is still unanswered. How do we choose estimators? What are the properties that an estimator must have to qualify as a ‘good estimator’? Two such properties have already been discussed before- consistency and asymptotic normality. Here, I’ll give you all a more general notion of these properties. I’ll also discuss some additional estimator properties, and using them we’ll try to evaluate the performance of our estimator. Properties:
1) Unbiasedness: We introduce a new term- bias. Bias is the difference between the expectation of the estimator and the true value of the parameter we are trying to estimate. It’s a little less intuitive theoretically, but mathematically it’ll make more sense. If θ-hat is the estimator for θ, then we express bias of θ-hat as follows:
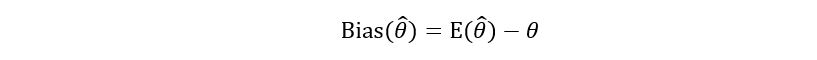
The bias shows how far the true parameter is from the mean value of the estimator. An unbiased estimator has zero bias i.e.,
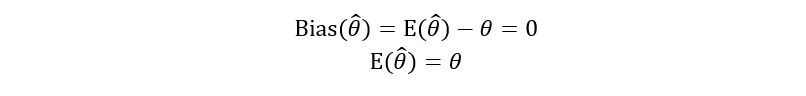
Let’s calculate the bias of p-hat. We had previously derived the expectation of p-hat, we’ll substitute this in the above expression for bias to obtain:
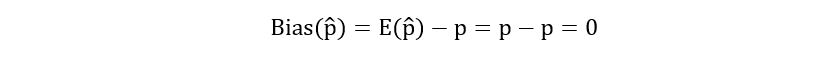
Yes, p-hat is an unbiased estimator! That’s a good indicator. Can we now say to the beverage company that hired us- “My statistical research suggests that 64% of people prefer tea. It’s an unbiased estimator. So go with more production of tea!” Well, not yet. The expectation of p-hat is indeed equal to p theoretically. But it’s possible that we practically observe a sample that’s far away from the expectation of p-hat. This could be due to the large variance of p-hat (we don’t know if it’s large or small, but that’s our presumption; in statistics, you need to always consider the possibility of the worst-case scenario). This leads us to our next metric- efficiency.
2) Efficiency: An efficient estimator is one that has a lower variance. Mathematically if we have two estimators- θ1-hat and θ2-hat, then the estimator θ1-hat is more efficient than θ2-hat if:
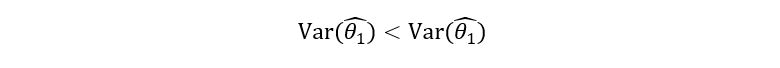
Let’s check the efficiency of our estimator. Previously, we calculated the variance of p-hat, giving us the following result:
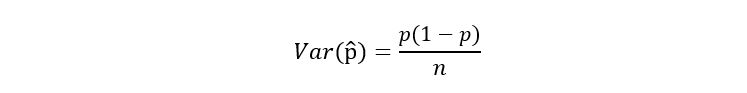
It has a non-zero variance. Fortunately, though the variance is inversely proportional to the sample size n. If n approaches infinity, then the variance of p-hat approaches zero. Seems good. This also explains why we need large sample sizes for statistical researches. Our sample size n = 850. Seems like a huge number! Our variance will be of the order 0.001 indicating that p-hat seems to be a good estimate. The following graph demonstrates the inverse relationship between the variance of p-hat and sample size n:
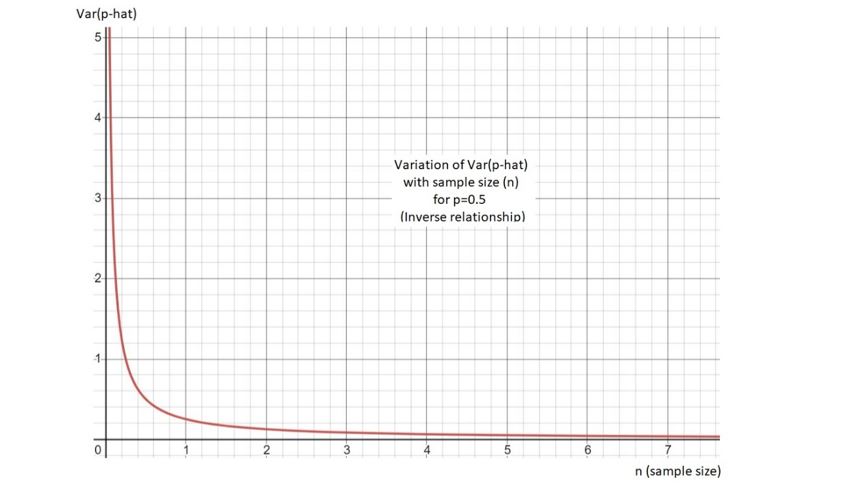
Often, there is a trade-off between bias and variance. Generally, as bias decreases variance increases and vice versa. Even in our scenario, the bias was zero, but the variance was a positive function of p and n. In general, we want estimators to exhibit low bias and low variance i.e., we want a low something and that something combines bias and variance. That something is called the quadratic risk, or more commonly known as the Mean Squared Error (MSE).
3) Quadratic Risk: Quadratic risk or Mean Squared Error is a positive function of both –
bias and variance. It is mathematically defined as:
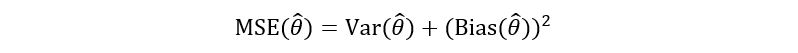
Simple substitution gives us the quadratic risk of p-hat:
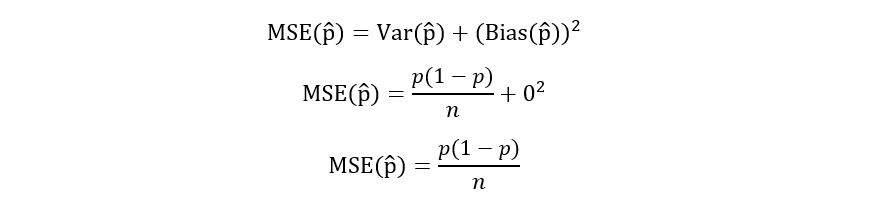
Conclusion
In this article, we started with a very simple example and gradually build up more concepts. We also discussed some mathematical theories and formulated a statistical model for our experiment. We concluded this article with an understanding of the process of estimation. To summarise the entire process of estimation in a few steps:
1) Assign a random variable to the experiment and find out its probability distribution.
2) Analyse the probability distribution and its properties such as expectation and variance.
3) Make assumptions and construct a statistical model.
4) Find a suitable estimator for the unknown parameters of the distribution.
5) Study the properties of the estimator including its expectation and variance.
6) Plug in the data observed into the estimator function to get the estimated value of the parameters.
7) Evaluate the performance of the estimators in terms of their consistency, asymptotic normality, bias, efficiency and mean squared error.
It’s important to note that we took a very basic and simplified example of estimation. In the real world, the file of statistical estimation is vast. There are various sophisticated and advanced estimators for various probability distributions. The purpose of this article was to not only see estimation as a mix of theory and math but also to make us feel the idea. I hope you enjoyed reading this article!
In case you have any doubts or suggestions, do reply in the comment box. Please feel free to contact me via mail.
If you liked my article and want to read more of them, visit this link. The other articles of this series will be found on the same link.
About the Author

I am currently a high school student, who is deeply interested in Statistics, Data Science, Economics, and Machine Learning. I have written two data science research papers. You can find them here.
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.






