Data-Driven decision-making has large involvement of Machine Learning Algorithms. For a business problem, the professional never rely on one algorithm. One always applies multiple relevant algorithms based on the problem and selects the best model based on the best performance metrics shown by the models. But this is not the end. One can increase the model performance using hyperparameters. Thus, finding the optimal hyperparameters would help us achieve the best-performing model. Hyperparameters for a model can be chosen using several techniques such as Random Search, Grid Search, Manual Search, Bayesian Optimizations, etc. In this article, we will learn about GridSearchCV which uses the Grid Search technique for finding the optimal hyperparameters to increase the model performance.
Also in this article, we will learn about Hyperparameters, Grid Search, Cross-Validation, GridSearchCV, and the tuning of Hyperparameters in Python, also you will get to learn about the grid search hyperparamter tuning and how it works.

Table of contents
This article was published as a part of the Data Science Blogathon
What is GridSearchCV?
GridSearchCV acts as a valuable tool for identifying the optimal parameters for a machine learning model. Imagine you have a machine learning model with adjustable settings, known as hyperparameters, that can enhance its performance. GridSearchCV aids in pinpointing the best combination of these hyperparameters automatically.
Here’s the process: You provide GridSearchCV with a set of Scoring parameter to experiment with, and it systematically explores each possible combination. For every combination, it evaluates the model’s performance by testing it on various sections of the dataset to gauge its accuracy.
After exhaustively trying out all the combinations, GridSearchCV presents you with the combination of settings that yielded the most favorable outcomes. This streamlines the process of fine-tuning your model, ensuring it operates optimally for your specific task without incurring excessive computational expenses.In this article we have thoroughly exapling about the grid search cv and how grid search cv in machine learning works . what is grid search. so you will get a full understanding of this tutorial.
Hyperparameters vs Parameters
Parameters and Hyper parameters both are associated with the Machine Learning model, but both are meant for different tasks. Let’s understand how they are different from each other in the context of Machine Learning.
Parameters are the variables that are used by the Machine Learning algorithm for predicting the results based on the input historic data. These are estimated by using an optimization algorithm by the Machine Learning algorithm itself. Thus, these variables are not set or hardcoded by the user or professional. These variables are served as a part of model training. Example of best Parameters: Coefficient of independent variables Linear Regression and Logistic Regression.
Hyperparameters are the variables that the user specifies, usually when building the Machine Learning model. They are distinct from parameters and play a crucial role in determining the model’s performance. Hyperparameters are chosen prior to defining the parameters, and they are instrumental in finding the optimal parameter combinations. One common approach to finding the best hyperparameters is through methods like grid search, where a parameter grid is defined, and various combinations of Specified parameter values are evaluated against a specified evaluation metric. The beauty of hyperparameters lies in the user’s ability to tailor them to the specific needs of the model being built. For instance, in Random Forest Algorithms, the user might adjust the max_depth hyperparameter, or in a KNN Classifier, the k hyperparameter can be tuned to enhance performance.
Understanding Grid Search
Now we know what hyperparameters are the multiple combinations, our goal should be to find the best hyperparameters values to get the perfect prediction results from our model. But the question arises, how to find these best sets of hyperparameters? One can try the Manual Search method, by using the hit and trial process and can find the best hyperparameters which would take huge time to build a single model.
For this reason, methods like Random Search, GridSearch were introduced. Here, we will discuss how Grid Seach is performed and how it is executed with cross-validation in GridSearchCV.
Grid Search employs an exhaustive search strategy, systematically exploring various combinations of specified hyperparameters and their Default values. This approach involves tuning parameters, such as learning rate, through a cross-validated model, which assesses performance across different parameter settings. However, due to its exhaustive nature, Grid Search can become time-consuming and resource-intensive, particularly as the number of hyperparameters increases.
Grid Search across Two Parameters (Image by Alexander Elvers from WikiMedia)
Cross-Validation and GridSearchCV
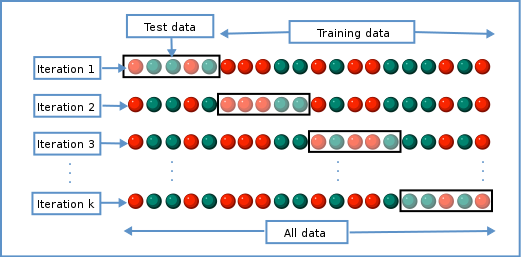
In GridSearchCV, along with Grid Search, cross-validation is also performed. Cross-Validation is used while training the model. As we know that before training the model with data, we divide the data into two parts – train data and test data. In cross-validation, the process divides the train data further into two parts – the train data and the validation data.
The most popular type of Cross-validation is K-fold Cross-Validation. It is an iterative process that divides the train data into k partitions. Each iteration keeps one partition for testing and the remaining k-1 partitions for training the model. The next iteration will set the next partition as test data and the remaining k-1 as train data and so on. In each iteration, it will record the performance of the model and at the end give the average of all the performance. Thus, it is also a time-consuming process.
Thus, GridSearch along with cross-validation takes huge time cumulatively to evaluate the best hyperparameters. Now we will see how to use GridSearchCV in our Machine Learning problem.
How to Apply GridSearchCV?
.GridSearchCV() method is available in the scikit-learn class model_selection. It can be initiated by creating an object of GridSearchCV():
clf = GridSearchCv(estimator, param_grid, cv, scoring)Primarily, it takes 4 arguments i.e. estimator, param_grid, cv, and scoring. The description of the arguments is as follows:
1. estimator – A scikit-learn model
2. param_grid – A dictionary with parameter names as keys and lists of parameter values.
3. scoring – The performance measure. For example, ‘r2’ for regression models, ‘precision’ for classification models.
4. cv – An integer that is the number of folds for K-fold cross-validation.
GridSearchCV can be used on several hyperparameters to get the best values for the specified hyperparameters.
Now let’s apply GridSearchCV with a sample dataset:
Importing the Libraries & the Dataset
Python Code:
Here we are going to use the HeartDiseaseUCI dataset.
Specifying Independent and Dependent Variables
X = df.drop('target', axis = 1)
y = df['target']Splitting the data into train and test set
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 42)Building Random Forest Classifier
rfc = RandomForestClassifier()Here, we created the object rfc of RandomForestClassifier().
Initializing GridSearchCV() object and fitting it with hyperparameters
forest_params = [{'max_depth': list(range(10, 15)), 'max_features': list(range(0,14))}]
clf = GridSearchCV(rfc, forest_params, cv = 10, scoring='accuracy')
clf.fit(X_train, y_train)Here, we passed the estimator object rfc, param_grid as forest_params, cv = 5 and scoring method as accuracy in to GridSearchCV() as arguments.
Getting the Best Hyperparameters
print(clf.best_params_)
This will give the combination of hyperparameters along with values that give the best performance of our estimate specified.
Putting it all together
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn import metrics
import warnings
warnings.filterwarnings('ignore')
df = pd.read_csv('heart.csv')
X = df.drop('target', axis = 1)
y = df['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 42)
rfc = RandomForestClassifier()
forest_params = [{'max_depth': list(range(10, 15)), 'max_features': list(range(0,14))}]
clf = GridSearchCV(rfc, forest_params, cv = 10, scoring='accuracy')
clf.fit(X_train, y_train)
print(clf.best_params_)
print(clf.best_score_)On executing the above code, we get:
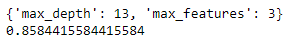
Best Params and Best Score of the Random Forest Classifier
Thus, clf.best_params_ gives the best combination of tuned hyperparameters, and clf.best_score_ gives the average cross-validated score of our Random Forest Classifier.
Grid search cv in machine learning
GridSearchCV is a tool from the scikit-learn library used for hyperparameter tuning in machine learning. It essentially automates the process of finding the optimal combination of hyperparameters for a given machine learning model.
Here is How it Works:
Hyperparameters refer to configurations in a machine learning model that manage how it learns. Instances could be the quantity of trees in a haphazard forest or the pace of learning in a support vector machine. Hyperparameters are determined before training, while model parameters are learned from data.
Grid Search: GridSearchCV methodically explores various combinations of hyperparameter values within a predetermined grid. This grid establishes the potential values for each hyperparameter.
Cross-Validation is used by GridSearchCV to assess the performance of each combination of hyperparameters. The data is divided into folds, the model is trained on certain folds using a particular hyperparameter configuration, and tested on the rest of the folds. All folds and hyperparameter combinations undergo this process again.
Conclusions
Thus, in this article, we learned about Grid Search, K-fold Cross-Validation, GridSearchCV, and how to make good use of GridSearchCV. GridSearchCV is a model selection step and this should be done after Data Processing tasks. It is always good to compare the performances of Tuned and Untuned Models. This will cost us the time and expense but will surely give us the best results. The scikit-learn API is a great resource in case of any help. It’s always good to learn by doing.
Hope you like this article of Grid Search CV where we have exaplin thoroughly of grid search , grid search cv in machine learning,grid search hyperparamter tuning . So we have thoroughly explain about these terms you will clear your doubts for this.
We you read about the article majorly you get about the grid search hyperparameter tuning and how it being used and its being classified by the grid search and its impact realible on grid search , also collapse that grid search cv in machine learning plays and important role in it.
Frequently Asked Questions
Q1. What is GridSearchCV used for?
A. GridSearchCV (Grid Search Cross-Validation) is a technique used in machine learning to search and find the optimal combination of hyperparameters for a given model. It systematically explores a predefined set of hyperparameter values, creating a “grid” of possible combinations. It then evaluates each combination using cross-validation and selects the one that produces the best performance. GridSearchCV helps in automating the process of hyperparameter tuning, enhancing model performance, and avoiding manual trial-and-error.
Q2. Is GridSearchCV a library?
A. GridSearchCV is not a library itself, but rather a class provided by the popular Python machine learning library scikit-learn (sklearn). It is part of the sklearn library’s model_selection module. This class is used to perform grid search and cross-validation to find the best hyperparameters for a given machine learning model. By utilizing GridSearchCV, you can efficiently explore different hyperparameter combinations and optimize your model’s performance.
Q3.What is grid search in Hyperparameter optimization?
Grid search is a method for hyperparameter optimization that systematically evaluates all possible combinations of hyperparameter values within a predefined grid to find the best-performing set of hyperparameters. It’s a straightforward approach but can be computationally expensive for models with many hyperparameters.
Q4. What is better than GridSearchCV?
GridSearchCV, short for Grid Search Cross-Validation, is a technique used in machine learning for hyperparameter tuning. It exhaustively searches through a specified parameter grid to determine the optimal combination of hyperparameters for a given model. It works by evaluating the model’s performance using cross-validation on each combination of parameters provided in the grid and selecting the combination that yields the best performance.
Q5. What is GridSearchCV used for?
GridSearchCV Function is used to evaluate for hyperparameter tuning and with computationally expensive in machine learning by training set exhaustively searching through parameter grids. RandomizedSearchCV, Bayesian Optimization, evolutionary algorithms, and AutoML frameworks are alternatives that may be more efficient or comprehensive, depending on the context.
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.
Rahul Shah
09 Jul, 2024
IT Engineering Graduate currently pursuing Post Graduate Diploma in Data Science.








hey author how can we use our cross validation dataset to find best hyperparameter as i think finding hyperparameter on train dataset is not good as eventually your model is also trained on that
How to download the data
Simply copy the data in a text-editor and save the file as "heart.csv". Hope that helps