Introduction
Imagine having the power to instantly understand your customer’s thoughts about a product or service. For instance, when NIKE and REEBOK launch new sports shoes and promote them on social media, manually sifting through thousands of comments to gauge customer sentiment is impossible. However, Natural Language Processing (NLP) offers a solution by enabling computers to understand human language. In this article, we’ll explore how VARDER Sentiment Analysis, a tool specifically designed for analyzing sentiments in social media text, can be used to automate and accurately assess customer feedback, all through the power of Python.
In this article, we will do Vader Sentimental Analysis after doing Natural language Processing. Also, We Will tell in the article about the analysis doing with python of VADER Sentimental Analysis.

Learning Objectives:
- Understand the concept and functionality of VARDER Sentiment Analysis
- Learn how to implement VARDER Sentiment Analysis using Python
- Grasp the process of natural language processing for sentiment analysis
- Recognize the advantages of VARDER Sentiment Analysis for analyzing social media text
This article was published as a part of the Data Science Blogathon.
Table of contents
- Introduction
- What is VADER Sentiment Analysis?
- How Accurate is Vader Sentiment Analysis?
- Analysis of VADER Sentiment Analysis using Python
- Step1: Install nltk Library
- Step2: Import nltk.corpus
- Step3: Collecting Social Media Comments
- Step4: Import File in Python
- Step5: Importing word_tokenize
- Step6: Importing FreqDist
- Step7: Import PorterStemmer
- Step8: Lemmatization
- Step9: Part of Speech Tagging
- Step10: Named entity Recognition
- Step11: Chunking
- Step12: Sentiment Analysis
- What makes VADER for social Media Text?
- Conclusion
- Frequently Asked Questions
What is VADER Sentiment Analysis?
VADER stands for Valence Aware Dictionary and Sentiment Reasoner. It’s a tool used for sentiment analysis, which is basically a way to figure out if a piece of text is expressing positive, negative, or neutral emotions [sentiment analysis ON Analytics Vidhya analyticsvidhya.com].
ARDER Sentiment Analysis is particularly good at understanding sentiment in social media text, like tweets and online comments. It works by looking at a list of words with positive or negative connotations, and then considering things like capitalization and punctuation to get a more nuanced understanding of the feeling behind the text [vaderSentiment – PyPI pypi.org].
Here’s some of the key things VADER can do:
- Tell you if a text is positive, negative, or neutral: This is the basic sentiment analysis task.
- Give you a score: VADER doesn’t just say positive or negative, it assigns a score between -1 (most negative) and +1 (most positive) to show how strong the sentiment is.
- Account for things like capitalization and punctuation: VADER understands that an exclamation point can make a positive word even more positive, or that a sarcastic “great” actually means the opposite.
How Accurate is Vader Sentiment Analysis?
VARDER Sentiment Analysis sentiment analysis is reported to be quite accurate, particularly for social media text like tweets. Studies have shown it to outperform even human raters in some cases. Here’s a breakdown of its accuracy:
- F1 Score: Research suggests VADER achieves an F1 score of 0.96, a metric combining precision and recall, for sentiment classification on tweets [3].
- Compared to Humans: In the same study, VADER’s F1 score was higher than individual human raters (who scored 0.84) [3].
- Compared to Other Models: VADER performs well against other sentiment analysis models, especially for negative sentiment detection [2].
Here are some things to keep in mind:
- VADER’s accuracy may vary depending on the type of text being analyzed (e.g., tweets vs. product reviews).
- Sentiment analysis is a complex task, and no model is perfect. There can always be cases where VADER misinterprets sarcasm or misses context.pen_spark
Analysis of VADER Sentiment Analysis using Python
We are doing all the analysis using python 3.
Step1: Install nltk Library
Firstly, we have to install Natural Language Processing Tool Kit Library. For that use, pip install nltk, then run the code.
Step2: Import nltk.corpus
Now import nltk and nltk.corpus using:
import nltkimport nltk.corpusThe nltk.corpus package defines a collection of corpus reader classes, which can be used to access the contents of a diverse set of corpora.
Step3: Collecting Social Media Comments
For collecting social media Comments, one has to use NodeXL it is an Excel-like tool that helps collect social media data. I am using a free version so, I will get a limited number of comments as data.
Link for downloading NodeXL –https://www.smrfoundation.org/nodexl/installation/
One can directly import data from Twitter, Facebook or YouTube, etc. Then one can save the file in .csv format and import the file in python using the pandas library.
Step4: Import File in Python
import pandas as pd
data = pd.read_csv('C:/Users/HP/Desktop/sem 4/Basic Python/Social_Media_Analysis.csv',encoding='latin1')For NLP, I am using my own statement as if I would use the dataset, it will be a very lengthy analysis.
text = "In Brazil they drive on the right-hand side of the road. Brazil has a large coastli"Step5: Importing word_tokenize
Now, from the library nltk.tokenize import word_tokenize as:
import nltk
import nltk.corpus
import pandas as pd
from nltk.tokenize import word_tokenize
nltk.download('punkt')
text = "In Brazil they drive on the right-hand side of the road. Brazil has a large coastli"
token = word_tokenize(text)
print(token)In this, we are tokenizing the words where tokenizing means splitting the sentences or phrases into small words.
Step6: Importing FreqDist
After this step, from nltk.probability import FreqDist as Frequency helps in understanding how many words have occurred how many times in the given data.
Input:
# finding the frequency distinct in the tokens
# Importing FreqDist library from nltk and passing token into FreqDist
from nltk.probability import FreqDist
fdist = FreqDist(token)
fdistOutput:
FreqDist({'Brazil': 2, 'the': 2, 'In': 1, 'they': 1, 'drive': 1, 'on': 1, 'right-hand': 1, 'side': 1, 'of': 1, 'road': 1, ...})From the output, it can be observed that ‘Brazil’ has been used twice, ‘the’ has been used twice, ‘In’ has been used a single time, and so on.
After that, to find the frequency of the top 10 words, we’ll use fdist.most_common(10).
Input:
# To find the frequency of top 10 words
fdist1 = fdist.most_common(10)
fdist1Output:
[('Brazil', 2),
('the', 2),
('In', 1),
('they', 1),
('drive', 1),
('on', 1),
('right-hand', 1),
('side', 1),
('of', 1),
('road', 1)]It can be observed that ‘Brazil’, ‘the’, ‘In’, ‘they’, ‘drive’, ‘on’, ‘right-hand’, ‘side’, ‘of’, ‘road’ are the top 10 words used in the sentence.
After this, we will use the stemming method to break down the word into a simpler form, for example, I am using waiting, given, giving and give:
Step7: Import PorterStemmer
For stemming, we will import PorterStemmer and LancasterStemmer, these are the two methods from which we can perform the stemming procedure.
Input:
# Importing Porterstemmer from nltk library
# Checking for the word ‘waiting’
from nltk.stem import PorterStemmer
pst = PorterStemmer()
pst.stem("waiting")Output:
'wait'Input:
# Importing LancasterStemmer from nltk
from nltk.stem import LancasterStemmer
lst = LancasterStemmer()
stm = ["giving", "given", "given", "gave"]
for word in stm :
print(word+ ":" +lst.stem(word))Output:
giving:giv
given:giv
given:giv
gave:gavAfter Stemming, comes Lemmatization which helps in breaking down words from plural to a singular form.]
Step8: Lemmatization
Lemmatization can be used in python3 by using Wordnet Lemmatizer, Spacy Lemmatizer, TextBlob, Stanford CoreNLP.
For example, I am using the word ‘corpora’ and ‘rocks’:

Input:
# Importing Lemmatizer library from nltk
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
print("rocks :", lemmatizer.lemmatize("rocks"))
print("corpora :", lemmatizer.lemmatize("corpora"))Output:
rocks : rock
corpora : corpusAfter Lemmatization, we have to identify Stop Words. Stop words are nothing but the articles used in the English language like “the”, “a”, “at”, “for”, “above”, “on”, “is”, “all”.
Articles don’t have any meaning while performing sentimental analysis as we cannot conclude anything from “the”, “a”, “at”, “for”, “above”, “on”, “is”, “all”. The system will look for the words that have some meaning in identifying a product/service like ‘Good’, ‘Bad’ or ‘Great’.
For example, I will use a sentence:
text = "Cristiano Ronaldo was born on February 5, 1985, in Funchal, Madeira, Portugal."Let’s check the output:

Input:
# importing stopwords from nltk library
from nltk import word_tokenize
from nltk.corpus import stopwords
a = set(stopwords.words('english'))
text = "Cristiano Ronaldo was born on February 5, 1985, in Funchal, Madeira, Portugal."
text1 = word_tokenize(text.lower())
print(text1)
stopwords = [x for x in text1 if x not in a]
print(stopwords)Output:
['cristiano', 'ronaldo', 'was', 'born', 'on', 'february', '5', ',', '1985', ',', 'in', 'funchal', ',', 'madeira', ',', 'portugal', '.']
['cristiano', 'ronaldo', 'born', 'february', '5', ',', '1985', ',', 'funchal', ',', 'madeira', ',', 'portugal', '.']Step9: Part of Speech Tagging
We have to make the system understand that what all words are ‘nouns’, ‘pronouns’, etc., for better analysis.
It is known as Part of Speech Tagging (POS)
For example, I will use a sentence:
text = "vote to choose a particular man or a group (party) to represent them in parliament."
Input:
text = "vote to choose a particular man or a group (party) to represent them in parliament"
#Tokenize the text
tex = word_tokenize(text)
for token in tex:
print(nltk.pos_tag([token]))Output:
[('vote', 'NN')]
[('to', 'TO')]
[('choose', 'NN')]
[('a', 'DT')]
[('particular', 'JJ')]
[('man', 'NN')]
[('or', 'CC')]
[('a', 'DT')]
[('group', 'NN')]
[('(', '(')]
[('party', 'NN')]
[(')', ')')]
[('to', 'TO')]
[('represent', 'NN')]
[('them', 'PRP')]
[('in', 'IN')]
[('parliament', 'NN')]After POS, we have to do the Named entity Recognition step
Step10: Named entity Recognition
It is the step in which the system identifies which word is a person’s name, location, etc.
For this, your system should have Ghostscript installed in the file where you have installed python3.
For this step, from nltk import ne_chunk as it helps in giving a tree-like structure to the output so that it will be easily understandable for us.

Input:
from nltk import ne_chunk# tokenize and POS Tagging before doing chunk
text = "vote to choose a particular man or a group (party) to represent them in parliament"
#importing chunk library from nltk
token = word_tokenize(text)
tags = nltk.pos_tag(token)
chunk = ne_chunk(tags)
chunkOutput:

Step11: Chunking
After this, Chunking took place, i.e., grouping the individual piece of information into bigger pieces.
For example, I have used:
text = "We saw the yellow dog."
Input:
text = "We saw the yellow dog"
token = word_tokenize(text)
tags = nltk.pos_tag(token)
reg = "NP: {<DT>?<JJ>*<NN>}"
a = nltk.RegexpParser(reg)
result = a.parse(tags)
print(result)Output:
(S We/PRP saw/VBD (NP the/DT yellow/JJ dog/NN))Step12: Sentiment Analysis
This is the last step of Natural Language Processing. Now we can further use this text (comments dataset) in text Analysis (as I earlier mentioned about Sentiment Analysis). For Sentiment Analysis, we’ll use VADER Sentiment Analysis, where VADER means Valence Aware Dictionary and Sentiment Reasoner.
VADER is a lexicon and rule-based feeling analysis instrument that is explicitly sensitive to suppositions communicated in web-based media. VADER utilizes a mix of lexical highlights (e.g., words) that are, for the most part, marked by their semantic direction as one or the other positive or negative. Thus, VADER not only tells about the Polarity score yet, in addition, it tells us concerning how positive or negative a conclusion is.
Installing VADER
For this, first, install the VADER package using:

VADER belongs to a kind of sentiment analysis that depends on lexicons of sentiment-related words. In this methodology, every one of the words in the vocabulary is appraised with respect to whether it is positive or negative, and, how +ve or -ve. Beneath you can see an extract from VADER’s vocabulary, where more positive words have higher positive evaluations and more adverse words have lower negative grades.
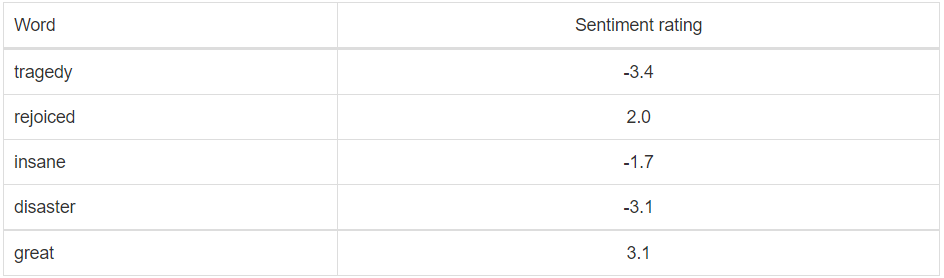
Engineers use methodologies to determine positive or negative words in content, which can be costly and time-consuming. However, if the lexicon matches the content, the method is accurate and fast. VADER engineers used Amazon’s Mechanical Turk for most evaluations, a quick and cost-effective approach to obtaining grades. This method ensures a strong match between the lexicon and the content.
As you would have speculated, when VADER examines a piece of text, it verifies whether any of the words in the content are available in the lexicon. For instance, the sentence “The food is amazing, and the environment is awesome” has two words in the lexicon (amazing and awesome) with the grading of 1.9 and 1.8, respectively (according to the algorithm calculation).
VADER generates four sentiment measurements from word grading: +ve, neutral, and -ve. The model sentence was graded as 45% +ve, 55% neutral, and 0% -ve. The compound score, which includes lexicon grades (1.9 and 1.8), ranges from -1 to 1. The model sentence’s rating is 0.69, strongly on the +ve side.
What makes VADER for social Media Text?
As you would have speculated, the way that lexicons are costly and tedious to create. It implies that they are not frequently refreshed. This means that they do not have a ton of current slang that might be utilized to communicate – how an individual is feeling. Take the beneath tweet to Optus’ client service account, for instance. All the components of this content that show that the individual is miserable (in the blue boxes) are casual compositions – numerous punctuation marks, abbreviations, and emojis. On the off chance that, if you didn’t consider this data, this tweet would look neutral to a sentiment analysis calculation!
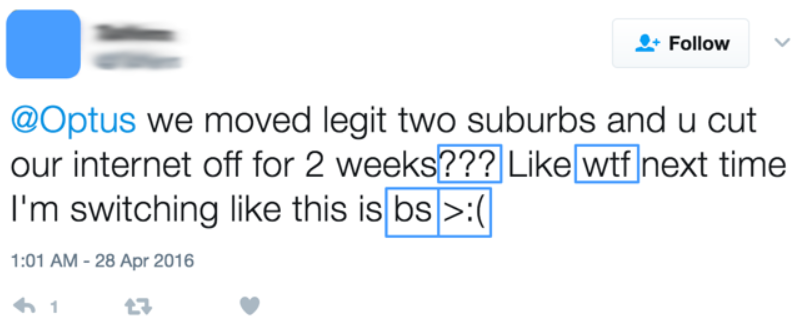
VADER can handle these types of terms for its lexicon. Now let’s have a look at how VADER MODEL works,
To install VADER Library use:
pip install vaderSentimentOutput:
Requirement already satisfied: vaderSentiment in e:anacondalibsite-packages (3.3.2) Requirement already satisfied: requests in e:anacondalibsite-packages (from vaderSentiment) (2.24.0) Requirement already satisfied: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in e:anacondalibsite-packages (from requests->vaderSentiment) (1.25.11) Requirement already satisfied: chardet<4,>=3.0.2 in e:anacondalibsite-packages (from requests->vaderSentiment) (3.0.4) Requirement already satisfied: idna<3,>=2.5 in e:anacondalibsite-packages (from requests->vaderSentiment) (2.10) Requirement already satisfied: certifi>=2017.4.17 in e:anacondalibsite-packages (from requests->vaderSentiment) (2020.6.20) Note: you may need to restart the kernel to use updated packages.I have already installed it, that’s why it is written: “Requirement already satisfied”.
Now it’s time to import SentimentIntensityAnalyzer from vaderSentiment.vaderSentiment
from vaderSentiment.vaderSentiment import SentimentIntensityAnalyzer
After importing VADER libraries, it’s time to create LOOP Functions that help identify our text like – what is the percentage of the entered text (Text Dataset) is Negative/Positive/Neutral?
Input:
# function to print sentiments
# of the sentence.
def sentiment_scores(sentence):
# Create a SentimentIntensityAnalyzer object.
sid_obj = SentimentIntensityAnalyzer()
# polarity_scores method of SentimentIntensityAnalyzer
# oject gives a sentiment dictionary.
# which contains pos, neg, neu, and compound scores.
sentiment_dict = sid_obj.polarity_scores(sentence)
print("Overall sentiment dictionary is : ", sentiment_dict)
print("sentence was rated as ", sentiment_dict['neg']*100, "% Negative")
print("sentence was rated as ", sentiment_dict['neu']*100, "% Neutral")
print("sentence was rated as ", sentiment_dict['pos']*100, "% Positive")
print("Sentence Overall Rated As", end = " ")
# decide sentiment as positive, negative and neutral
if sentiment_dict['compound'] >= 0.05 :
print("Positive")
elif sentiment_dict['compound'] <= - 0.05 :
print("Negative")
else :
print("Neutral")This function will make a sentence positive if the value of the text will be more than or equal to 0.05. It will make the text negative if the value of the text will be less than or equal to -0.05, else it will make the sentence neutral.
One can use the recorded sentiments after cleaning them with the NLP and use the variable that has been selected for the entire comments/sentiments.
VADER Analysis
For VADER analysis, I am going to use:
Text = “ANN is like our brain; millions and billions of cells — called neurons, which processes information in the form of electric signals. Similarly, in ANN, the network structure has an input layer, a hidden layer, and the output layer. It is also called Multi-Layer Perceptron as it has multiple layers. The hidden layer is known as a “distillation layer” that distills some critical patterns from the data/information and passes it onto the next layer. It then makes the network quicker and more productive by distinguishing the data from the data sources, leaving out the excess data.”
Now the Final step adding the text into the Driver Code, i.e., it is the code a programmer has set to analyze something.
# Driver code
if __name__ == "__main__" :
print("Text Selected for VADER Sentimental Analysis :")
sentence1 = ('''ANN is like our brain; millions and billions of cells — called neurons, which processes information in the form of electric signals. Similarly, in ANN, the network structure has an input layer, a hidden layer, and the output layer. It is also called Multi-Layer Perceptron as it has multiple layers. The hidden layer is known as a “distillation layer” that distils some critical patterns from the data/information and passes it onto the next layer. It then makes the network quicker and more productive by distinguishing the data from the data sources, leaving out the excess data.''')
print(sentence1)Output for the Driver Code:
Text Selected for VADER Sentimental Analysis : ANN is like our brain; millions and billions of cells — called neurons, which processes information in the form of electric signals. Similarly, in ANN, the network structure has an input layer, a hidden layer, and the output layer. It is also called Multi-Layer Perceptron as it has multiple layers. The hidden layer is known as a “distillation layer” that distils some critical patterns from the data/information and passes it onto the next layer. It then makes the network quicker and more productive by distinguishing the data from the data sources, leaving out the excess data.
The final command for the result of the Analysis:
In this command, we’ll get to know about the paragraph, i.e., whether it is a positive statement, Negative Statement or Neutral Statement.
We call the function to determine the sentence’s Positive, Negative, and Neutral percentages.
Input:
# function calling
sentiment_scores(sentence1)Output:
Overall sentiment dictionary is : {'neg': 0.023, 'neu': 0.951, 'pos': 0.025, 'compound': 0.0516}
sentence was rated as 2.3 % Negative
sentence was rated as 95.1 % Neutral
sentence was rated as 2.5 % Positive
Sentence Overall Rated As Positive
Conclusion
VADER Sentiment Analysis provides a robust and efficient means of gauging sentiment in text, particularly within social media contexts where it excels due to its lexicon-based approach. By leveraging Python, we can easily implement VADER to process large volumes of comments and feedback, offering valuable insights into customer perceptions. While it demonstrates high accuracy and the ability to handle the nuances of online language, ARDER Sentiment Analysis real strength lies in its ability to quickly and effectively transform qualitative data into actionable quantitative insights, ultimately aiding businesses in making informed decisions based on customer sentiment.
Key Takeaways:
- VADER is particularly effective for sentiment analysis of social media text
- VADER provides sentiment scores on positive, negative, neutral, and compound scales
- Python libraries like NLTK and vaderSentiment enable easy implementation of VADER
- VADER can handle informal language elements like slang, emojis, and punctuation
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Frequently Asked Questions
Q1. What is Vader in sentiment analysis?
A. VADER (Valence Aware Dictionary and sEntiment Reasoner) is a sentiment analysis tool that uses a lexicon and rules to analyze text for positive, negative, and neutral sentiments.
Q2. How accurate is Vader sentiment analysis?
A. VARDER Sentiment Analysis is highly accurate for social media and other informal text, achieving around 90% accuracy, which is comparable to human accuracy.
Q3. What does Vader mean in NLP?
A. In NLP, VADER stands for Valence Aware Dictionary and sEntiment Reasoner, a tool designed to perform sentiment analysis by evaluating the emotional tone of text.
Q4. Is Vader sentiment analysis free?
A. Yes, VARDER Sentiment Analysis is free and open-source, available for use in various programming languages through libraries like NLTK in Python.





Hi Aryan, Thank you for this brilliant blog post. I've following question for VADER example: You have used your sentence directly in polarity score of SentimentIntensityAnalyzer without doing stemming, lemmatization or chunking. Does VADER does all of that internally or a tweet should be sent to VADER after cleaning and tokeninzing it?
I just finished reading your blog and I have to say, it was an outright pleasure. Your writing practice is engaging and descriptive, making me feel like I was right there with you on your adventures. The picture you included were also stunning and really added to the overall quest. cheers
Wow, thank you so much for taking the time to read my blog and for your kind words! I'm thrilled to hear that my writing was engaging and that the pictures were able to enhance your experience. I really appreciate your support and encouragement. I would love to have you along for more adventures and I would be honoured if you follow me on Medium as well (ARYANBAJAJ13.MEDIUM.COM (copy & paste this on google)). I post interesting concepts and the latest updates on AI, ML and other related topics that I believe you may find informative and intriguing. Thanks again for your kind words and I look forward to connecting with you more in the future.