This article was published as a part of the Data Science Blogathon
Overview
- This article will give you a basic understanding of how text analysis works.
- Learn the various steps of the NLP pipeline
- Derivation of the overall sentiment of the text.
- Dashboard depicting the general statistics and sentiment analysis of the text.
Abstract
In this modern digital era, a large amount of information is generated per second. Most of the data humans generate through WhatsApp messages, tweets, blogs, news articles, product recommendations, and reviews is unstructured. So to gain useful insights from this highly unstructured data we need to first convert it into structured and normalized form.
Natural language processing (NLP) is a class of Artificial Intelligence that performs series of processes on this unstructured data to get meaningful insight. Language processing is completely non-deterministic in nature because the same language can have different interpretations. It becomes tedious as something suitable to one person is not suitable for another. Moreover, the use of colloquial language, acronyms, hashtags with attached words, emoticons posses overhead for preprocessing.
If the power of social media analytics interests you then this article is the starting point for you. This article covers the basic concepts of text analytics and provides you step by step tutorial to perform natural language processing without the requirement of any training dataset.
Introduction to NLP
Natural language processing is the subfield of Artificial intelligence which comprises systematic processes to convert unstructured data to meaningful information and extract useful insights from the same. NLP is further classified into two broad categories- Rule-based NLP and Statistical NLP. Rule-based NLP uses basic reasoning for processing tasks, therefore manual effort is required without much training of dataset. Statistical NLP on the other hand trains a large amount of data and gain insights from it. It uses Machine learning algorithms for training the same. In this article, we will be learning Rule-based NLP.
Applications of NLP:
- Text Summarization
- Machine Translation
- Question and Answering Systems
- Spell Checks
- AutoComplete
- Sentiment Analysis
- Speech Recognition
- Topic Segmentation
NLP pipeline:

NLP pipeline is divided into five sub-tasks:
1. Lexical Analysis: Lexical analysis is the process of analyzing the structure of words and phrases present in the text. Lexicon is defined as the smallest identifiable chunk in the text. It could be a word, phrase, etc. It involves identifying and dividing the whole text into sentences, paragraphs, and words.
2. Syntactic Analysis: Syntactic analysis is the process of arranging words in a way that shows the relationship between the words. It involves analyzing them for patterns in grammar. For example, the sentence “The college goes to the girl.” is rejected by the syntactic analyzer.
3. Semantic Analysis: Semantic analysis is the process of analyzing the text for meaningfulness. It considers syntactic structures for mapping the objects in the task domain. For example, the sentence “He wants to eat hot ice cream” gets rejected by the semantic analyzer.
4. Disclosure integration: Disclosure integration is the process of studying the context of the text. The sentences are organized in a meaningful order to form a paragraph which means the sentence before a particular sentence is needed to understand the overall meaning. Also, the sentence succeeding the sentence is dependent on the previous one.
5. Pragmatic Analysis: Pragmatic analysis is defined as the process of reconfirming that what the text actually meant is the same as that derived.
Reading the text file:
filename = "C:\Users\Dell\Desktop\example.txt" text = open(filename, "r").read()
Printing the text:
print(text)

Installing the library for NLP:
We will use the spaCy library for this tutorial. spaCy is an open-source software library for advanced NLP written in the programming languages Python and Cython. The library is published under an MIT license. Unlike NLTK, which is widely used for teaching and research, spaCy focuses on providing software for production usage. spaCy also supports deep learning workflows that allow connecting statistical models trained by popular machine learning libraries like TensorFlow, Pytorch through its own machine learning library Thinc.[Wikipedia]
pip install -U pip setuptools wheel pip install -U spacy
Since we are dealing with the English language. So we need to install the en_core_web_sm package for it.
python -m spacy download en_core_web_sm
Verifying the download was successful and importing the spacy package:
import spacy
nlp = spacy.load('en_core_web_sm')
After the successful creation of the NLP object, we can move to the preprocessing.
Tokenization:
Tokenization is the process of converting the entire text into an array of words knows as tokens. This is the first step in any NLP process. It divides the entire text into meaningful units.
text_doc = nlp(text) print ([token.text for token in text_doc])

As we can observe from the tokens, there are many whitespaces, commas, stopwords that are of no use from an analysis perspective.
Sentence Identification
Identifying the sentences from the text is useful when we want to configure meaningful parts of the text that occur together. So it is useful to find sentences.
about_doc = nlp(about_text) sentences = list(about_doc.sents)

Stopwords Removal
Stopwords are defined as words that appear frequently in language. They don’t have any significant role in text analysis and they hamper the frequency distribution analysis. For example- the, an, a, or, and etc. So they must be removed from the text to get a clearer picture of the text.
normalized_text = [token for token in text_doc if not token.is_stop] print (normalized_text)

Punctuation Removal:
As we can see from the above output, there are punctuation marks that are of no use to us. So let us remove them.
clean_text = [token for token in normalized_text if not token.is_punct] print (clean_text)

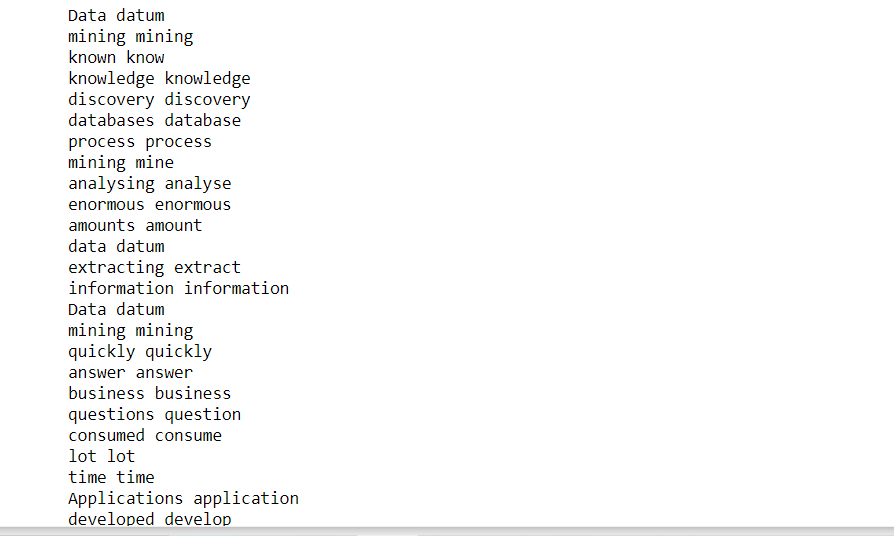
Lemmatization:
Lemmatization is the process of reducing a word to its original form. Lemma is a word that represents a group of words called lexemes. For example: participate, participating, participated. They all get reduced to a common lemma i.e. participate.
for token in clean_text: print (token, token.lemma_)
Word Frequency Count:
Let us now perform some statistical analysis on the text. We will find the top ten words according to their frequencies in the text.
from collections import Counter words = [token.text for token in clean_text if not token.is_stop and not token.is_punct] word_freq = Counter(words) # 10 commonly occurring words with their frequencies common_words = word_freq.most_common(10) print (common_words)

Sentiment Analysis
Sentiment Analysis is the process of analyzing the sentiment of the text. One way of doing this is through the polarity of words whether they are positive or negative.
VADER(Valence Aware Dictionary and Sentiment Reasoner) is a lexicon and rule-based sentiment analysis library in python. It uses a series of sentiment lexicons. A sentiment lexicon is a series of words that are assigned to their respective polarities i.e. positive, negative, and neutral according to their semantic meaning.
For example:
1. words like good, great, awesome, fantastic are of positive polarity.
2. words like bad, worse, pathetic are of negative polarity.
VADER sentiment analyzer finds out the percentages of words of different polarity and gives polarity scores of each of them respectively. The output of the analyzer is scored from 0 to 1 which can be converted to percentages. IT not only tells about the positivity or negativity scores but also how positive or negative a sentiment is.
Let us first download the package using pip.
pip install vaderSentiment
Then analyze the sentiment scores.
from vaderSentiment.vaderSentiment import SentimentIntensityAnalyzer analyzer = SentimentIntensityAnalyzer() vs = analyzer.polarity_scores(text) vs

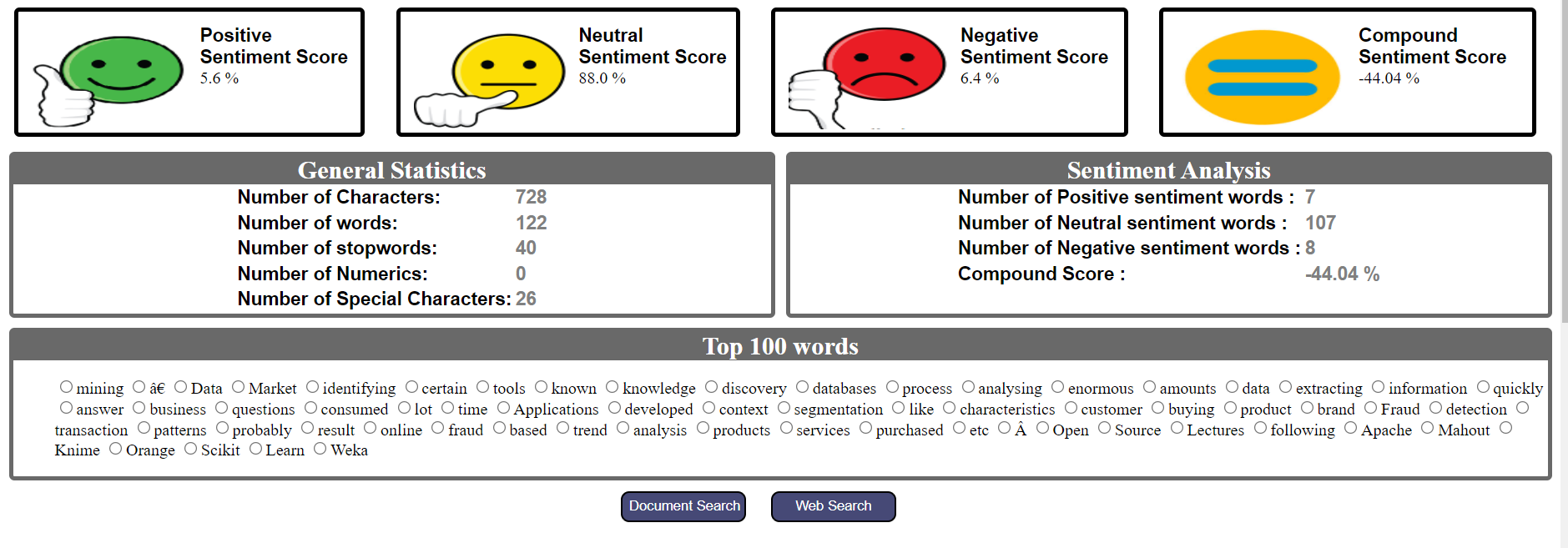
Text Analyzer dashboard
The above steps can be summarized to create a dashboard for the text analyzer. It includes the number of words, number of characters, number of numerics, Top N-words, Intent of the text, overall sentiment, positive sentiment score, negative sentiment score, neutral sentiment score, and sentiment wise word count.
Conclusion
NLP has made a great impact in fields like product review analysis, recommendations, social media analytics, text translation and thus making huge profits for big companies.
Hope this article makes you start your journey in the NLP field.
And finally, … it doesn’t go without saying,
Thank you for reading!
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.




