Anomaly detection using Isolation Forest – A Complete Guide
This article was published as a part of the Data Science Blogathon
Introduction:
Any data point/observation that deviates significantly from the other observations is called an Anomaly/Outlier. Anomaly detection is important and finds its application in various domains like detection of fraudulent bank transactions, network intrusion detection, sudden rise/drop in sales, change in customer behavior, etc.
Many techniques were developed to detect anomalies in the data. In this article, we will look at the implementation of Isolation Forests – an unsupervised anomaly detection technique.
Table of contents
What is Isolation Forest?
Isolation Forest is a technique for identifying outliers in data that was first introduced by Fei Tony Liu and Zhi-Hua Zhou in 2008. The approach employs binary trees to detect anomalies, resulting in a linear time complexity and low memory usage that is well-suited for processing large datasets.
Since its introduction, Isolation Forest has gained popularity as a fast and reliable algorithm for anomaly detection in various fields such as cybersecurity, finance, and medical research.
Isolation Forests Anamoly Detection
Isolation Forests(IF), similar to Random Forests, are build based on decision trees. And since there are no pre-defined labels here, it is an unsupervised model.
IsolationForests were built based on the fact that anomalies are the data points that are “few and different”.
In an Isolation Forest, randomly sub-sampled data is processed in a tree structure based on randomly selected features. The samples that travel deeper into the tree are less likely to be anomalies as they required more cuts to isolate them. Similarly, the samples which end up in shorter branches indicate anomalies as it was easier for the tree to separate them from other observations.
Let’s take a deeper look at how this actually works.

How do Isolation Forests work?
As mentioned earlier, Isolation Forests outlier detection are nothing but an ensemble of binary decision trees. And each tree in an Isolation Forest is called an Isolation Tree(iTree). The algorithm starts with the training of the data, by generating Isolation Trees.
Let us look at the complete algorithm step by step:
- When given a dataset, a random sub-sample of the data is selected and assigned to a binary tree.
- Branching of the tree starts by selecting a random feature (from the set of all N features) first. And then branching is done on a random threshold ( any value in the range of minimum and maximum values of the selected feature).
- If the value of a data point is less than the selected threshold, it goes to the left branch else to the right. And thus a node is split into left and right branches.
- This process from step 2 is continued recursively till each data point is completely isolated or till max depth(if defined) is reached.
- The above steps are repeated to construct random binary trees.
After an ensemble of iTrees(Isolation Forest) is created, model training is complete. During scoring, a data point is traversed through all the trees which were trained earlier. Now, an ‘anomaly score’ is assigned to each of the data points based on the depth of the tree required to arrive at that point. This score is an aggregation of the depth obtained from each of the iTrees. An anomaly score of -1 is assigned to anomalies and 1 to normal points based on the contamination(percentage of anomalies present in the data) parameter provided.
Source: IEEE. We can see that it was easier to isolate an anomaly compared to a normal observation.
Implementation in Python:
Let us look at how to implement Isolation Forest in Python.
Read the input data:
import numpy as np
import pandas as pd
import seaborn as sns
from sklearn.ensemble import IsolationForest
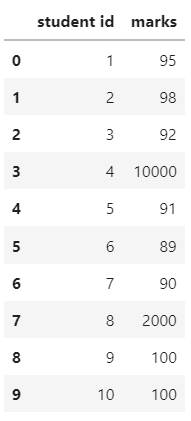
data = pd.read_csv('marks.csv')
data.head(10)Output:
Visualize the data:
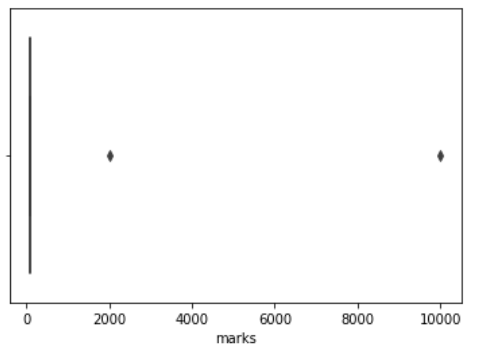
From the box plot, we can infer that there are anomalies on the right.
Define and fit the model:
random_state = np.random.RandomState(42)
model=IsolationForest(n_estimators=100,max_samples='auto',contamination=float(0.2),random_state=random_state)
model.fit(data[['marks']])
print(model.get_params())Output:
{'bootstrap': False, 'contamination': 0.2, 'max_features': 1.0, 'max_samples': 'auto', 'n_estimators': 100, 'n_jobs': None, 'random_state': RandomState(MT19937) at 0x7F08CEA68940, 'verbose': 0, 'warm_start': False}
You can take a look at Isolation Forest documentation in sklearn to understand the model parameters.
Score the data to obtain anomaly scores:
data['scores'] = model.decision_function(data[['marks']])
data['anomaly_score'] = model.predict(data[['marks']])
data[data['anomaly_score']==-1].head()Output:
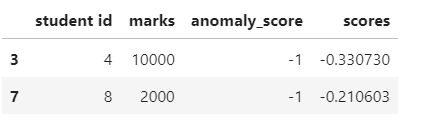
Here, we can see that both the anomalies are assigned an anomaly score of -1.
Model Evaluation:
accuracy = 100*list(data['anomaly_score']).count(-1)/(anomaly_count)
print("Accuracy of the model:", accuracy)Output:
Accuracy of the model: 100.0
What happens if we change the contamination parameter? Give it a try!!
Limitations of Isolation Forest:
Isolation Forests are computationally efficient and
have been proven to be very effective in Anomaly detection. Despite its advantages, there are a few limitations as mentioned below.
- The final anomaly score depends on the contamination parameter, provided while training the model. This implies that we should have an idea of what percentage of the data is anomalous beforehand to get a better prediction.
- Also, the model suffers from a bias due to the way the branching takes place.
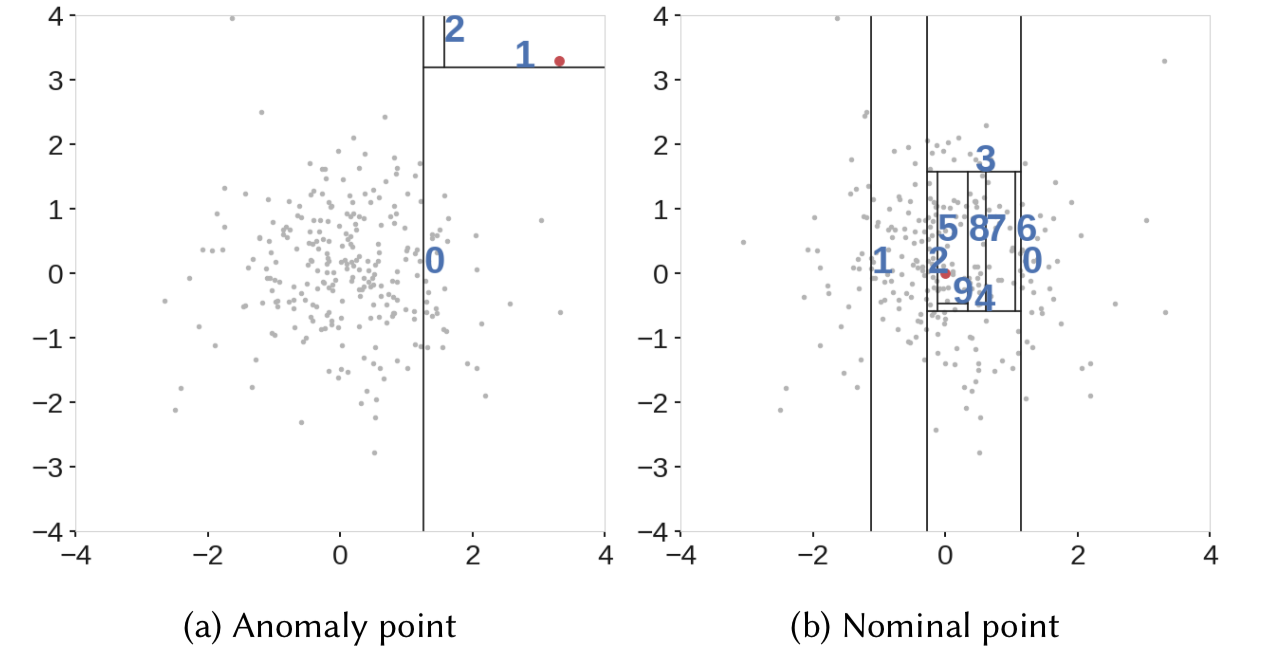
Well, to understand the second point, we can take a look at the below anomaly score map.
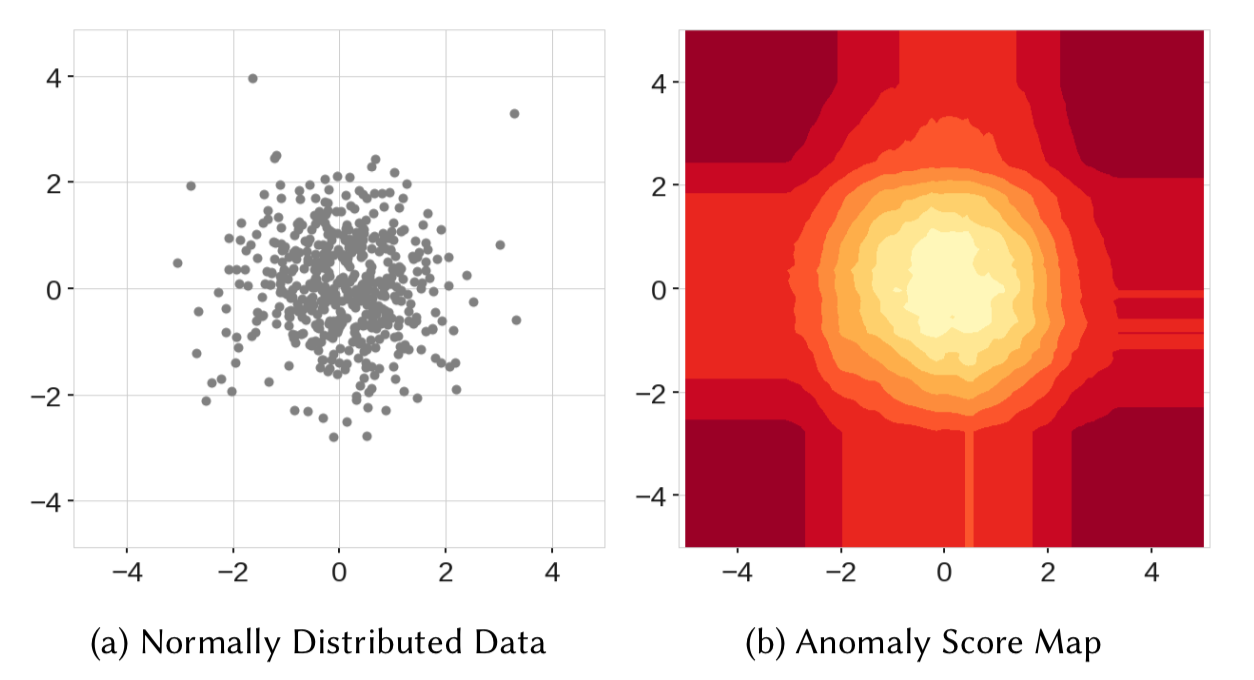
Source: IEEE
Here, in the score map on the right, we can see that the points in the center got the lowest anomaly score, which is expected. However, we can see four rectangular regions around the circle with lower anomaly scores as well. So, when a new data point in any of these rectangular regions is scored, it might not be detected as an anomaly.

Similarly, in the above figure, we can see that the model resulted in two additional blobs(on the top right and bottom left ) which never even existed in the data.
Whenever a node in an iTree is split based on a threshold value, the data is split into left and right branches resulting in horizontal and vertical branch cuts. And these branch cuts result in this model bias.

The above figure shows branch cuts after combining outputs of all the trees of an Isolation Forest. Here we can see how the rectangular regions with lower anomaly scores were formed in the left figure. And also the right figure shows the formation of two additional blobs due to more branch cuts.
To overcome this limit, an extension to Isolation Forests called ‘Extended Isolation Forests’ was introduced by Sahand Hariri. In EIF, horizontal and vertical cuts were replaced with cuts with random slopes.

Though EIF was introduced, Isolation Forests are still widely used in various fields for Anamoly detection.
Conclusion
In conclusion, Isolation Forests effectively detect anomalies, leveraging tree-based structures to isolate outliers efficiently. Their implementation in Python provides a versatile tool for identifying anomalies in various datasets. However, users should be mindful of limitations such as sensitivity to data dimensionality and potential bias towards smaller clusters.
Thanks for reading the article!!
I hope you got a complete understanding of Anomaly detection using Isolation Forests. Feel free to share this with your network if you found it useful.
Frequently Asked Questions
A. Difference between Random Forest and Isolation Forest is that Random Forest is a supervised learning algorithm used for classification and regression tasks, while Isolation Forest is an unsupervised learning algorithm used for anomaly detection.
A. Isolation Forest works by randomly selecting a feature from the dataset and a split value to create partitions of the data. This process is repeated recursively until anomalies are isolated in their own partitions.
Feature image credits: Photo by Sebastian Unrau on Unsplash
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.








This is a great blog post! I'm a big fan of using Isolation Forest for anomaly detection.
Thanks for the feedback!! :)
This is a great blog post! I'm a big fan of using Isolation Forest for anomaly detection.